1、实战问题
如下都是实战环节遇到的问题:
-
logstash谁解决过时区问题,mysql是东八区shanghai 但是这玩意读完存到es就少了8小时?
-
目前索引会比真正时间晚8小时,导致8点前的日志写到昨天索引里,大佬们有招吗?
-
问一下 logstash输出日志到本地文件中,按照小时生成索引,但是他这边的时区是utc,生成的时间和北京时间少8小时,这一块大佬们是咋操作的?
-
......从浏览器kibana那里看timestamp时间戳变成了utc的时区?
上面的问题都涉及到时区问题,涉及到数据的同步(logstash)、写入、检索(elasticsearch)、可视化(kibana)的几个环节。
2、时区问题拆解
我们通过如下几个问题展开拆解。
2.1 Elasticserch 默认时区是?能改吗?
官方文档强调:在 Elasticsearch 内部,日期被转换为 UTC时区并存储为一个表示自1970-01-01 00:00:00 以来经过的毫秒数的值。
Internally, dates are converted to UTC (if the time-zone is specified) and stored as a long number representing milliseconds-since-the-epoch.
https://www.elastic.co/guide/en/elasticsearch/reference/current/date.html
Elasticsearch date 类型默认时区:UTC。
正如官方工程师强调(如下截图所示):Elasticsearch 默认时区不可以修改。

https://discuss.elastic.co/t/index-creates-in-different-timezone-other-than-utc/148941但,我们可以“曲线救国”,通过:
- ingest pipeline 预处理方式写入的时候修改时区;
- logstash filter 环节做时区转换;
- 查询时指定时区;
- 聚合时指定时区。
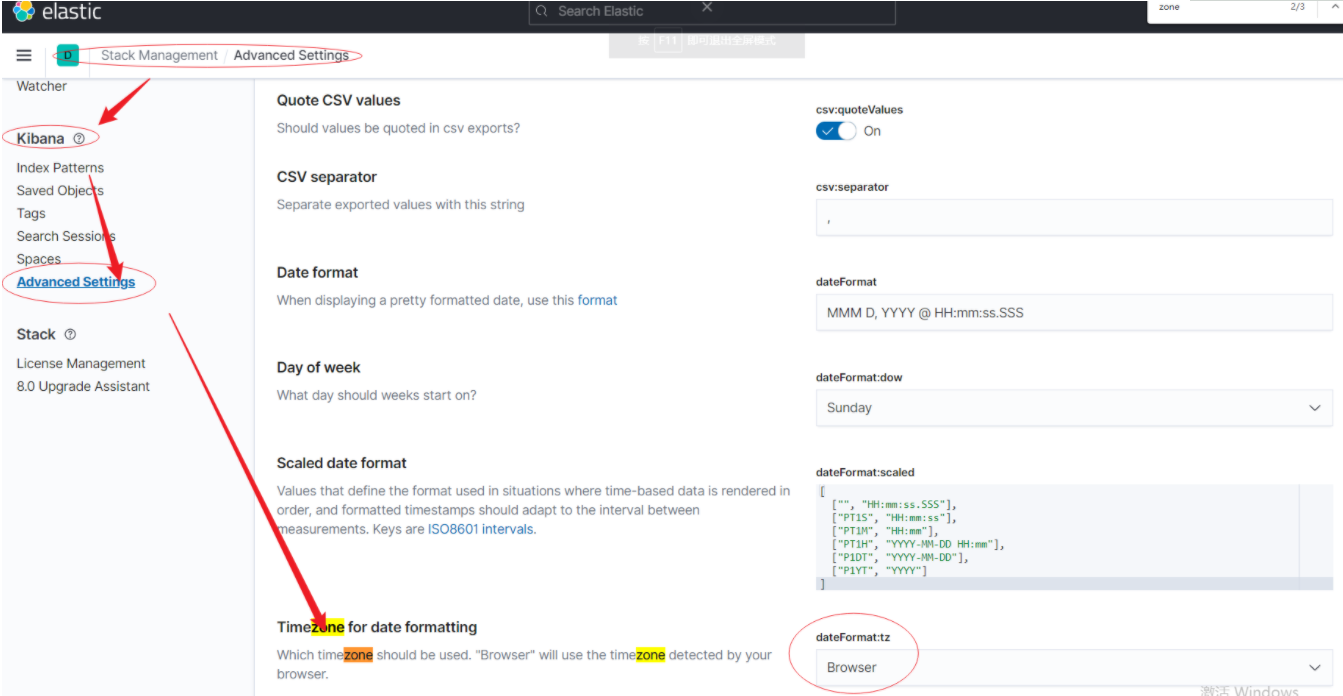
2.2 Kibana 默认时区是?能改吗?
kibana 默认时区是浏览器时区。可以修改,修改方式如下:Stack Management -> Advanced Settings ->Timezone for data formatting.
2.3 Logstash 默认时区是?能改吗?
默认:UTC。可以通过中间:filter 环节进行日期数据处理,包括:转时区操作。小结一下:
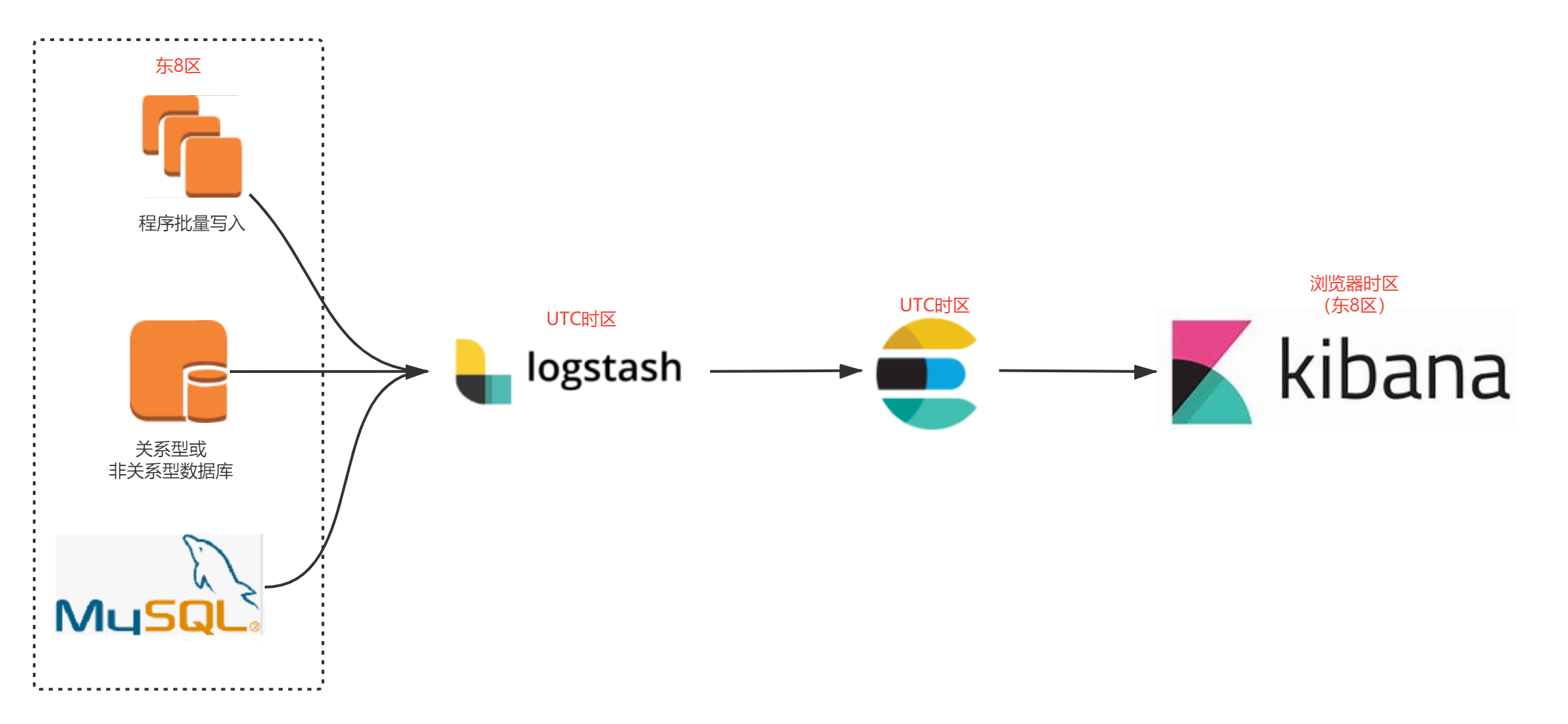
- logstash 默认 UTC 时区。
- Elasticsearch 默认 UTC 时区。
- Kibana 默认浏览器时区,基本我们用就是:东八区。
- 如果基于Mysql 同步数据,Mysql 数据是:东八区。
我们看一下东8区百度百科定义:东八区(UTC/GMT+08:00)是比世界协调时间(UTC)/格林尼治时间(GMT)快8小时的时区,理论上的位置是位于东经112.5度至127.5度之间,是东盟标准的其中一个候选时区。当格林尼治标准时间为0:00时,东八区的标准时间为08:00。通过上面的定义,能加深对 logstash 同步数据后,数据滞后8小时的理解。
3、时区问题解决方案
基于上面的分析,如何解决时区问题呢?由于 kibana 支持手动修改时区,不在下文讨论 的范围之内。实战项目中,自己根据业务需求修改即可。那么问题就转嫁为:写入的时候转换成给定时区(如:东8区)就可以了。
3.1 方案一:ingest 预处理为东8区时区
- 步骤 1:定义预处理管道:chage_utc_to_asiash(名称自己定义即可)。
在该管道中实现了时区转换。
- 步骤 2:创建索引同时指定缺省管道:chage_utc_to_asiash。
- 步骤 3:写入数据(单条或 bulk 批量均可)
PUT _ingest/pipeline/chage_utc_to_asiash { "processors": [ { "date" : { "field" : "my_time", "target_field": "my_time", "formats" : ["yyyy-MM-dd HH:mm:ss"], "timezone" : "Asia/Shanghai" } } ] } PUT my-index-000001 { "settings": { "default_pipeline": "chage_utc_to_asiash" }, "mappings": { "properties": { "my_time": { "type": "date" } } } } PUT my-index-000001/_doc/1 { "my_time": "2021-08-09 08:07:16" }
当写入数据后,执行检索时,kibana dev tool 返回结果如下:
"hits" : [ { "_index" : "my-index-000001", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "my_time" : "2021-08-09T08:07:16.000+08:00" } } ]
最明显的特征是:多了+08:00 时区(东8区)标志。然后,我们用:kibana discover可视化展示一下:
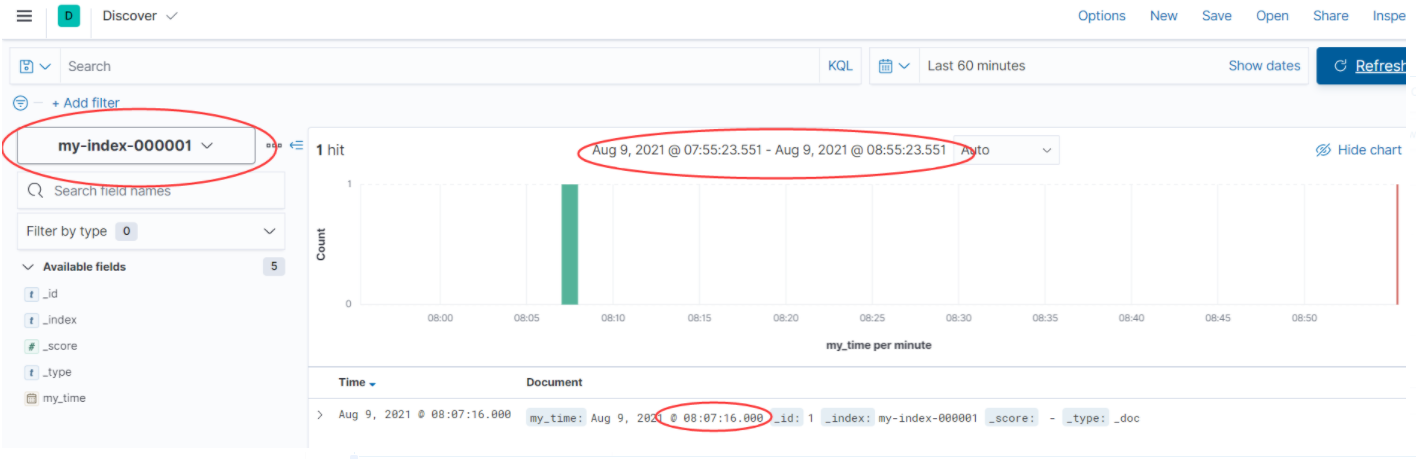
上图中,kibana 采用默认浏览器时区。如果不做上面的 ingest 预处理实现,会怎么样呢?大家如果实现过,肯定会感触很深。需要我们在kibana中切换时间范围,才能找到之前写入的数据。ingest 预处理时区的好处:方便、灵活的实现了写入数据的时区转换。
3.2 方案二:logstash 中间 filter 环节处理
拿真实同步案例讲解一下时区处理:
- 数据源端:Mysql;
- 数据目的端:Elasticsearch;
- 同步方式:logstash,本质借助:logstash_input_jdbc 插件同步;
- 时区处理:logstash filter 环节 ruby 脚本处理。
如下只给出了中间 filter 环节的脚本:
filter { ruby { code => "event.set('timestamp', event.get('publish_time').time.localtime + 8*60*60)" } ruby { code => "event.set('publish_time',event.get('timestamp'))" } mutate { remove_field => ["timestamp"] } }
三行脚本含义,解释如下:
- 第一行:将 publish_time 时间加 8 小时处理,赋值给 timestamp。
publish_time 到了 logstash 已转成了 UTC 时区了。timestamp 类似似 C 语言中的交换两个数函数中的 temp 临时变量。
- 第二行:将 timestamp 时间赋值给 publish_time。
- 第三行:删除中转字段:timestamp。
源数据Mysql 效果:
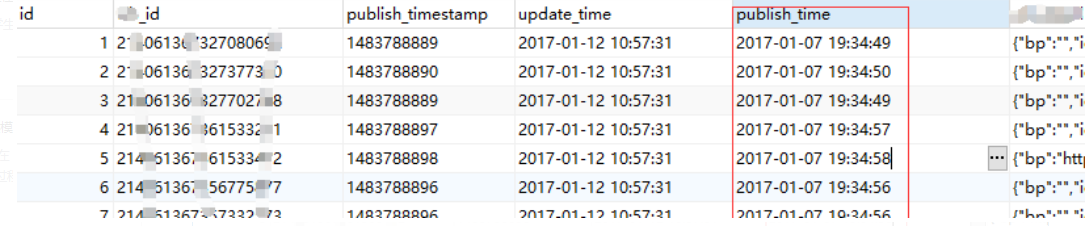
同步后 效果:
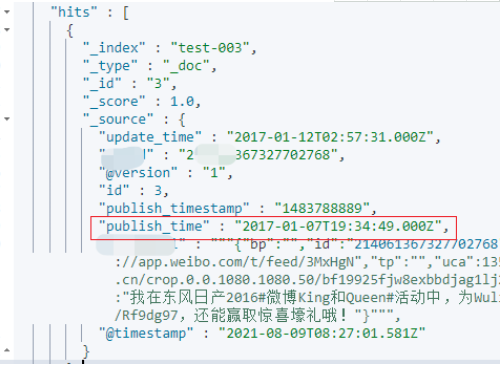
如上两个截图,对比一下区别:
- publish_time 做了时区处理,两者时间已一致,都是东 8 区。
- update_time 未做时间处理,写入Elasticsearch 后由东8区时间 10:57:31 转为UTC时区时间 02:57:31,少了8小时。
4、检索和聚合的时候指定时区
假定我们写入ES前未做时区处理(实战环节常有的场景),但是检索或者聚合的时候想做时区处理可以吗?
可以的,具体实现方式如下:
POST testindex/_search?pretty { "query": { "range": { "date": { "gte": "2020-01-01 00:00:00", "lte": "2020-01-03 23:59:59", "format": "yyyy-MM-dd HH:mm:ss", "time_zone": "+08:00" } } }, "size": 0, "aggs": { "per_day": { "date_histogram": { "calendar_interval": "day", "field": "date", "time_zone": "+08:00" } } } }
如上示例中,整合了检索和聚合,有两个要点:
- 要点1:range query 中指定时区检索。
- 要点2:data_histogram 聚合中指定时区聚合。
5、小结
数据写入时间不一致、数据滞后8小时等时区问题的本质是:各个处理端时区不一致,写入源的时区、Kibana默认是本地时区(如中国为:东8区时区),而 logstash、Elasticsearch 是UTC时区。

本文给出了两种写入前预处理的解决方案,方案一:基于管道预处理;方案二:基于logstash filter 中间环节过滤。两种方案各有利弊,预处理管道相对更轻量级,实战选型建议根据业务需求。本文最后指出在检索和聚合环节使用时区处理方式。
参考
https://t.zsxq.com/2nYnq76
https://mp.weixin.qq.com/s/gBY7uNSjy-4fux0cf3rBDg