1.JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS 并发垃圾回收是因为无法忍受STW(Stop-The-World)
2. Serial 年轻代 串行回收
单CPU效率最高,虚拟机是Client模式的默认垃圾回收器。Serial回收器使用单线程进行垃圾回收,使用复制算法。在 HotSpot 虚拟机中,使用-XX:+UseSerialGC 参数可以指定使用Serial(新生代串行收集器)+ Serial Old(老年代串行收集器)。

3. PS 年轻代 并行回收
新生代并行回收收集器也是使用复制算法的收集器。从表面上看,它和并行收集器一样都是多线程、独占式的收集器。但是,并行回收收集器有一个重要的特点:它非常关注系统的吞吐量。
在启动参数中指定-XX:+UseParallelGC,会使用Parallel Scavenge(新生代并行回收收集器) + SerialOld的回收器组合
如果使用-XX:+UseParallelOldGC,表示Parallel Scavenge(新生代并行回收收集器)+ Parallel Old(并行回收收集器)

4. ParNew 年轻代 配合CMS的并行回收
Serial回收器的多线程版本,只能用于新生代。使用复制算法,多线程并行工作。在多CPU主机上的性能高于Serial,单CPU主机上的性能低于Serial。
如果使用-XX:+UseParNewGC,表示ParNew(并行收集器)+ Serial Old(串行收集器)

5. SerialOld老年代 串行回收
Serial收集器的老年版本,独占式,单线程,使用的是标记--整理算法,这个收集器的目的也是用于Client模式下的虚拟机使用。

6. ParallelOld老年代 并行回收
是Parallel Scavenge收集器的老年版本,使用多线程和标记整理算法,注重吞吐量优先,在注重吞吐量和CPU资源铭感的场合,都可以考虑Parallel Scavenge加Parallel Old收集器。

7. ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms)
算法:三色标记 + Incremental Update
1.初始标记:Stop the world,只标记GC Roots能直接关联到的对象。
2.并发标记:GC Roots Tracing
3.重新标记:Stop the world,修正并发标记期间,因用户程序继续运行导致标记产生变动的那一部分对象的标记记录。
4.并发清除:并发清除可以和用户线程一起运行,所以总体上停顿的时间非常短。
但是CMS收集器有三个显著缺点:
1.对CPU资源敏感。
2.无法处理浮动垃圾。
3.收集结束后会产生大量碎片。

8. G1 (10ms) 算法:三色标记 + SATB
1.G1的设计原则是"首先收集尽可能多的垃圾(Garbage First)"。因此,G1并不会等内存耗尽(串行、并行)或者快耗尽(CMS)的时候开始垃圾收集,而是在内部采用了启发式算法,在老年代找出具有高收集收益的分区进行收集。同时G1可以根据用户设置的暂停时间目标 自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间就越大;
2.G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。由于都是以相等大小的分区为单位进行操作,因此G1天然就是一种压缩方案(局部压缩);
3.G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换;
4.G1的收集都是STW的,但年轻代和老年代的收集界限比较模糊,采用了混合(mixed)收集的方式。即每次收集既可能只收集年轻代分区(年轻代收集),也可能在收集年轻代的同时,包含部分老年代分区(混合收集),这样即使堆内存很大时,也可以限制收集范围,从而 降低停顿。
原文链接:https://blog.csdn.net/coderlius/article/details/79272773
9. ZGC (1ms) PK C++ 算法:ColoredPointers + LoadBarrier
10. Shenandoah 算法:ColoredPointers + WriteBarrier
11. Eplison
12PS 和 PN区别的延伸阅读: ▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73
10.垃圾收集器跟内存大小的关系
1.Serial 几十兆
2.PS 上百兆 - 几个G
3.CMS - 20G
4.G1 - 上百G
5.ZGC - 4T - 16T(JDK13)
1.8默认的垃圾回收:PS + ParallelOld

12.三色标记算法
1.用于CMS和G1垃圾回收器,发生在并发标记垃圾阶段
2.三色分别是:黑色(自身和成员变量均被标记完成),灰色(自身被标记,成员变量未被标记),白色(未被标记的对象)
3.三色标记是在根可达算法的基础上实现的。找到对象被引用就将其标记,未被标记的是垃圾。
4.漏标
第一阶段:A引用B,B引用C。A完全扫描标记黑色,B部分扫描标记灰色,C还未被扫描,标记白色
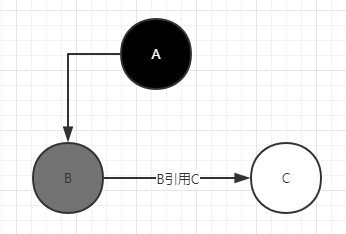
第二阶段:标记过程中,B到C的引用断开,此时A到C添加了新的引用。
因为A已经被标记为黑色(完全扫描),所以当再次标记的时候,C不会被标记。
B已经不引用C,所以扫描灰色B的时候,也不会标记C。这种情况就是漏标
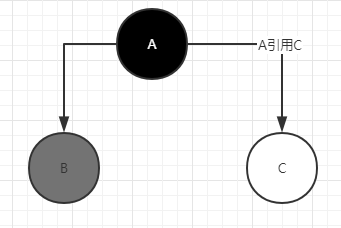
5.漏标的解决办法
CMS:Incremental Update 增量更新,关注引用的增加
将黑色重新标记未灰色,下次重新扫描属性
G1:SATB snapshot at the beginning 关注引用的删除
讲引用推到GC的堆栈。保证C会被再次扫描。