词云图,大家一定见过,大数据时代大家经常见,我们今天就来用python的第三方库wordcloud,来制作一个大数据词云图,同时会降到这个过程中遇到的各种坑,
举个例子,下面是我从自己的微信上抓的微信好友签名,制作的词云图:看来用的做多的还是“方得始终”啊

首先我们需要几个库,pip完了导入
1 import chardet #检测字符类型的类 2 from wordcloud import WordCloud #词云库 3 import matplotlib.pyplot as plt #数学绘图库
咱们这个例子分2步,第一步:从文件读取一段文字,第二步制作词云图并显示出来
看代码:从桌面读取一个文件
1 with open("C:\Users\fyc\Desktop\virgo.txt", "r") as f: 2 text = f.read() 3 type = chardet.detect(text) 4 text1 = text.decode(type["encoding"])
在这要做一个编码的工作,应为词云的generate函数接受的是一个Unicode类的对象,其他的对象会导致异常,经过层层跟进,终于在wordcloud.py文件里发现了这一行代码:
1 stopwords = set(map(str.lower, self.stopwords)) 2 3 flags = (re.UNICODE if sys.version < '3' and type(text) is unicode 4 else 0) 5 regexp = self.regexp if self.regexp is not None else r"w[w']+" 6 7 words = re.findall(regexp, text, flags)
问题出在正则表达式:如果不是unicode类型,进来的text经过re.findall计算,将什么也匹配不到,words为一个空list,随后就会抛出异常
所以在generate()之前一定要转码成“Unicode”类型。
第二步:生成词云,并显示:
1 wc1 = WordCloud( 2 background_color="white", 3 width=1000, 4 height=860, 5 font_path="C:\Windows\Fonts\STFANGSO.ttf",#不加这一句显示口字形乱码 6 margin=2) 7 wc2 = wc1.generate(text1) #我们观察到generate()接受一个Unicode的对象,所以之前要把文本处理成unicode类型 8 9 plt.imshow(wc2) 10 plt.axis("off") 11 plt.show()
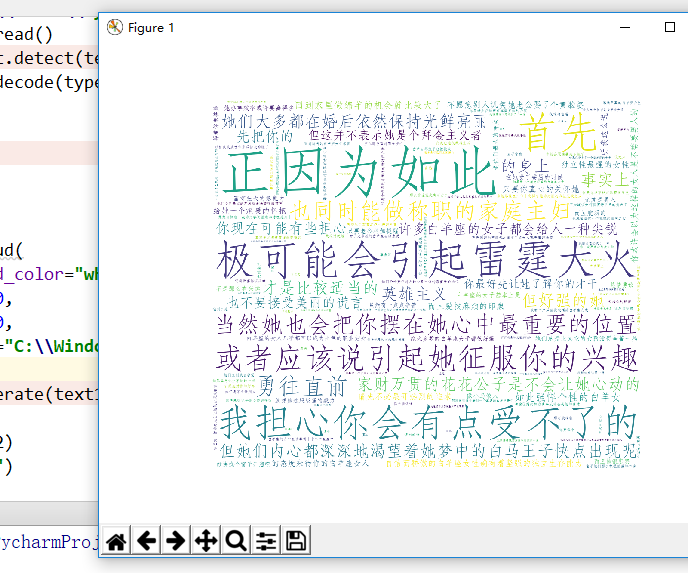
wordcloud构造处一个词云对象,然后generate()方法把传进来的文本“text"按照词出现的频率安排词的大小,其中text,我是找了一篇关于白羊座的介绍,文字如下:
豪放率真的白羊座女生,富有强大的想象力,热情勇敢,女汉子味十足。勇往直前,是你们最大的特点。所以即便面对困难挫折,白羊女都敢于迎接挑战。可以说,这是个极具战斗精神的新时代女性。如此强悍个性的白羊女,在异性的眼中却永远都少了点女人味专属的温柔,往往都是称兄道弟的份。
如果你期待一个林黛玉般的女孩来满足你的男子气概,碰到了她,你可真是门儿都没有了,识相的话,赶快找个窗子开溜吧!在火星守护下的白羊座女子,通常是积极而且坚强的。像小鸟依人、楚楚可怜这一类的形容词很难加诸在她身上。
白羊座的女子应该算得上十二个星座中,独立性最强的女性。她绝对不是那种整天守在家里,等着你来接她、送她,完全缺乏独立行动能力的典型。对于大多数的白羊座女孩来说,她宁愿相信如果没有你在身边碍手碍脚,她办事效率或许要高得多。听我这么说,你或许会以为这样的女人是不需要男人的!那可就错啦!自信而骄傲的白羊座女性确有着坚强的独立生存能力。但她们内心都深深地渴望着她梦中的白马王子快点出现呢!很难相信吧!看起来那么锐利的她,其实是充满着童话般梦想的。而对所有的白羊座女子来说,她们心里最大的矛盾就是渴望征服对方,又期待着被对方征服的微妙心里。
你现在可能有些担心,不知道该如何扮演好自已的角色了,是吗?别慌!先把你的“真心”准备好,以后的办法就好商量了,虽然有一点点辛苦,不过保证值得。
首先,你必须认清,白羊座的女子基本上是“英雄主义”的。她会倾心于一个令她佩服的男人。她要嫁一个让她引以为傲的丈夫。她或许会比较欣赏事业有成的男人,但这并不表示她是个拜金主义者。家财万贯的花花公子是不会让她心动的,满腔理想的热血青年反而会受她的青睐。因此,如果你爱上了一个白羊座的女子,请先不必展开热烈的追求。哈巴狗一样的男人会让她既讨厌又害怕,她深怕给你一个礼貌的微笑之后,你就会死缠着她不放了。你最好先让她了解你的才干、你的魅力,引起她对你的好奇(或者应该说引起她征服你的兴趣),等你感受到她对你真有好感之后,你再诚恳的对她表示爱意,那么前途就大有可为了!
你要像个“大男人”的样子(我说过她很英雄主义),但是你绝不能对她颐指气使。你一定要真心的关怀她,但绝对不要太纵容她。我想你应该用一种“英雄惜英雄”的态度来待你的白羊座女人,才是比较适当的。
绝大多数的白羊座女子都很好强,她们坚持要在对方的心目中保持最重要的地位。当然她也会把你摆在她心中最重要的位置。而且她很忠实、很大方。她愿意与你分享她的一切。当然,她也会认为你应该与她分享一切,包括你的秘密。欺骗你的白羊座女人,有如犯了欺君之罪一样的严重。这一点你可千万要记住,她情愿听你令她心碎的忏悔,也不要接受美丽的谎言。你最好少在她面前夸奖其她的女孩,尤其是那种由衷的赞美,极可能会引起雷霆大火。
由于她们那么积极坚强的个性,许多白羊座的女子都会给人一种尖锐、而且爱找麻烦的印象。在表面上,她们是不会让别人(尤其是男人)占便宜的。很多人会认为白羊座的女人总是尖嘴利牙的得理不饶人。正因为如此,她们常常会吃些暗亏,受到挫折,她们总是比其它的女孩活得辛苦一些。其实,你应该明白,她们的内心多半是正直、善良,而且脆弱的。只要你真心的关怀她,在她受了委屈的时侯,给她一个温暖的怀抱,她会成为你一生忠实可靠的伴侣。
白羊座的女人几乎都可以成为出色的职业妇女,也同时能做称职的家庭主妇。事实上,让她拥有自已的事业对你们的婚姻是有帮助的。当她尽量在工作上发挥了她的好胜心和征服欲之后,回到家里做绵羊的机会就比较大了。如果要一个精力旺盛的白羊座女子,把心思全放在“你”的身上,我担心你会有点受不了的。至于家庭,你大可放心,她虽然柴米油盐之类的琐事,不是那么有兴趣,但好强的她,不会让自已成为一个失败的主妇的。
还有件事你该庆幸,那就是我很少看到一个邋遢的白羊座妻子,她们大多都在婚后依然保持光鲜亮丽,不愿意别人讥笑她老公娶了个黄脸婆。就算偶尔懒散一下,只要老公稍加提醒,她们立刻就会警觉。我有个产后稍微发福的白羊座女友,就因为老公说了一句“以前我最欣赏你那双修长的腿了。”她硬是两个月减肥了二十磅。就凭她这股坚强的毅力,你能不相信她会全力以赴的做个好妻子吗?
关于构造方法的介绍需要说明几点:第一,用的是关键词参数,无需记住参数位置,技术参数的关键词就行。
关于参数的含义,在pycharm中查看快速文档,说明如下:
class WordCloud(object) def __init__(self, font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=.9, mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None, background_color='black', max_font_size=None, font_step=1, mode="RGB", relative_scaling=.5, regexp=None, collocations=True, colormap=None, normalize_plurals=True) Documentation is missing. The following is copied from class WordCloud. Word cloud object for generating and drawing. font_path: (string) Font path to the font that will be used (OTF or TTF). Defaults to DroidSansMono path on a Linux machine. If you are on another OS or don't have this font, you need to adjust this path. (int (default=400)) Width of the canvas. height: (int (default=200)) Height of the canvas. prefer_horizontal: (float (default=0.90)) The ratio of times to try horizontal fitting as opposed to vertical. If prefer_horizontal < 1, the algorithm will try rotating the word if it doesn't fit. (There is currently no built-in way to get only vertical words.) mask: (nd-array or None (default=None)) If not None, gives a binary mask on where to draw words. If mask is not None, width and height will be ignored and the shape of mask will be used instead. All white (#FF or #FFFFFF) entries will be considerd "masked out" while other entries will be free to draw on. [This changed in the most recent version!] scale: (float (default=1)) Scaling between computation and drawing. For large word-cloud images, using scale instead of larger canvas size is significantly faster, but might lead to a coarser fit for the words. min_font_size: (int (default=4)) Smallest font size to use. Will stop when there is no more room in this size. font_step: (int (default=1)) Step size for the font. font_step > 1 might speed up computation but give a worse fit. max_words: (number (default=200)) The maximum number of words. stopwords: (set of strings or None) The words that will be eliminated. If None, the build-in STOPWORDS list will be used. background_color: (color value (default="black")) Background color for the word cloud image. max_font_size: (int or None (default=None)) Maximum font size for the largest word. If None, height of the image is used. mode: (string (default="RGB")) Transparent background will be generated when mode is "RGBA" and background_color is None. relative_scaling: (float (default=.5)) Importance of relative word frequencies for font-size. With relative_scaling=0, only word-ranks are considered. With relative_scaling=1, a word that is twice as frequent will have twice the size. If you want to consider the word frequencies and not only their rank, relative_scaling around .5 often looks good. color_func: (callable, default=None) Callable with parameters word, font_size, position, orientation, font_path, random_state that returns a PIL color for each word. Overwrites "colormap". See colormap for specifying a matplotlib colormap instead. regexp: (string or None (optional)) Regular expression to split the input text into tokens in process_text. If None is specified, r"w[w']+" is used. collocations: (bool, default=True) Whether to include collocations (bigrams) of two words. colormap: (string or matplotlib colormap, default="viridis") Matplotlib colormap to randomly draw colors from for each word. Ignored if "color_func" is specified. normalize_plurals: (bool, default=True) Whether to remove trailing 's' from words. If True and a word appears with and without a trailing 's', the one with trailing 's' is removed and its counts are added to the version without trailing 's' – unless the word ends with 'ss'. Notes Larger canvases with make the code significantly slower. If you need a large word cloud, try a lower canvas size, and set the scale parameter. The algorithm might give more weight to the ranking of the words than their actual frequencies, depending on the max_font_size and the scaling heuristic.
大家使用百度翻译应该能看明白,这里说明几个比较关键的参数:
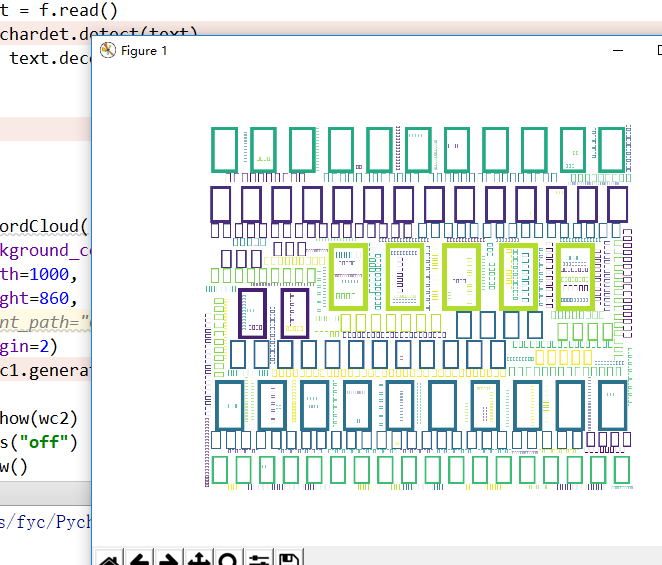
font_path:这个是在词云图中显示文字的字体存放的路径,特别是在显示中文的时候,这个参数尤为重要,如果缺省的话容易造成乱码,如下:
width,height 顾名思义,画布的长宽。
prefer_horizontal :词云的字体优先水平放置
mask:这是背景的形状,缺省是画布的形状。
其他几个参数就不说了
第三步就是用matplotlib库将词云图显示出来,这一段代码比较固定,没什么变化,死记硬背了
1 plt.imshow(wc2) 2 plt.axis("off") 3 plt.show()
其中,axis是显示坐标,这里我们选择不现实坐标。整体效果如下: