python2的编码实在是个头疼的问题,编码问题也将作为一个长期的话题,遇到问题随时补充。
这次的问题比较简单,是在做词云wordcloud的时候发现的,作用就是从文本文件中读取文字,将其制作成词云。部分代码如下:
1 import chardet 2 from wordcloud import WordCloud 3 import matplotlib.pyplot as plt 4 5 with open("C:\Users\fyc\Desktop\json.txt", "r") as f: 6 text = f.read() 7 type = chardet.detect(text) 8 text1 = text.decode(type["encoding"]) 9 text2 = "".join(text1) 10 print text 11 print text1 12 print text2 13 14 wordcloud = WordCloud( 15 background_color="white", 16 width=1000, 17 height=860, 18 margin=2).generate(text2) 19 20 plt.imshow(wordcloud) 21 plt.axis("off") 22 plt.show()
我们只关注5,6,7,8这四行代码,我在14行打了断点,观察读取的内容
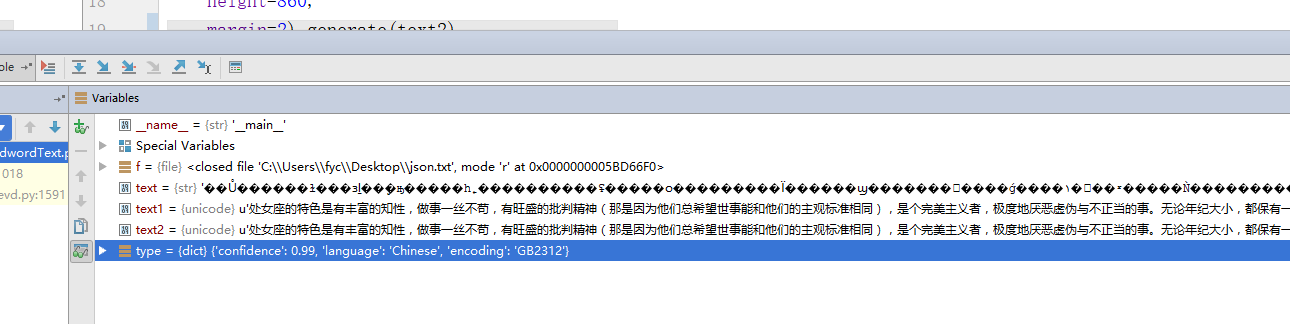
很明显,直接读取,text是str类型,完全是乱码,text1做了处理,显示正常。
在这我们隆重介绍 python 内建模块 chardet模块,编码检测。这个模块可以检测出一行字符是什么编码,我们看一下text的编码,如下:
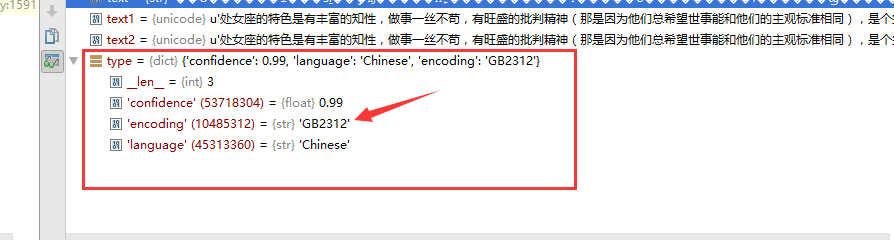
chardet模块的detect方法返回一个字典,其中的“encoding",明显的指出,这个是”GB2312"编码,接下来我们会心一笑,可以用decode来解码了,解码完应该就是正常显示了。
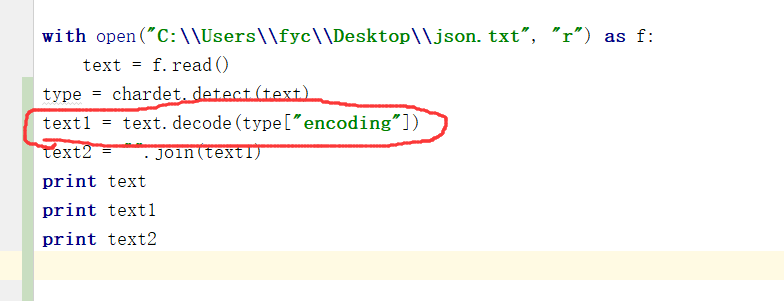
所以我们用了上面的这一句,那么今后所有的读取文件地方,在显示之前,我们都可以用chardet检测一下字符串的编码,相应解码。就可以避免文件乱码的情况了