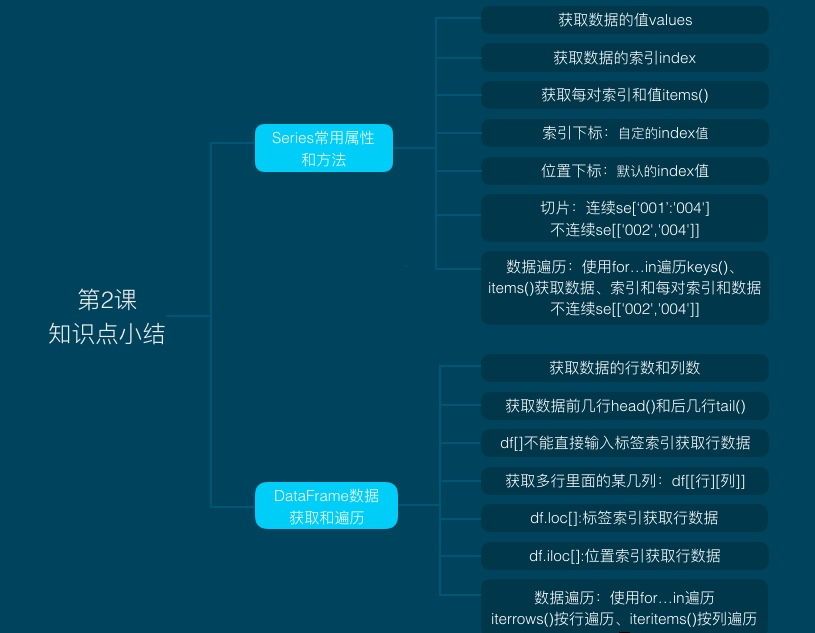
1.Series
from pandas import Series
emp=['001','002','003','004','005','006']
name=['亚瑟', '后裔','小乔','哪吒' ,'虞姬','王昭君']
series = Series(data=name,index=emp)
# 获取单个数据
print(series[0])
# 获取多个不连续的数据
print('位置下标',series[[1,3]])
# 使用切片获取连续的数据
print('位置切片',series[0:3])
2.Dataframe
import pandas as pd
df_dict = {
'name':['ZhangSan','LiSi','WangWu','ZhaoLiu'],
'age':['18','20','19','22'],
'weight':['50','55','60','80']
}
df = pd.DataFrame(data=df_dict,index=['001','002','003','004'])
print(df)
# 获取行数和列数
print(df.shape)
# 获取行索引
print(df.index.tolist())
# 获取列索引
print(df.columns.tolist())
# 获取数据的维度
print(df.ndim)
# 获取前两条
df.head(2)
# 获取后两条
df.tail(2)
# 通过位置索引切片获取一行
print(df[0:1])
# 通过位置索引切片获取多行
print(df[1:3])
# 获取多行里面的某几列
print(df[1:3][['name','age']])
# 获取DataFrame的列
print(df['name'])
# 如果获取多个列
print(df[['name','age']])
通过行标签索引筛选loc[],通过行位置索引筛选iloc[],loc['001':'003']的结果中包含行索引003对应的行。iloc[0:2] 结果中不包含序号为2的数据,切片终点对应的数据不在筛选结果中
# 获取某一行某一列的数据
print(df.loc['001','name'])
# 某一行多列的数据
print(df.loc['001',['name','weight']])
# 一行所有列
print(df.loc['001',:])
# 选择间隔的多行多列
print(df.loc[['001','003'],['name','weight']])
# 选择连续的多行和间隔的多列
print(df.loc['001':'003','name':'weight'])
# 取一行
print(df.iloc[1])
# 取连续多行
print(df.iloc[0:2])
# 取间断的多行
print(df.iloc[[0,2],:])
# 取某一列
print(df.iloc[:,1])
# 某一个值
print(df.iloc[1,0])
3.遍历
按value遍历:
for value in df['薪资']:
print(value)
iterrows(): 按行遍历,将DataFrame的每一行转化为(index, Series)对。index为行索引值,Series为该行对应的数据。
for index,row_data in df.iterrows():
print(index,row_data)
for col,col_data in df.iteritems()
print(col,col_data)