1、某表达式的前缀形式为"+-*^ABCD/E/F+GH",运算符优先级为^>*/>-+,它的中缀形式为(C)
A A^B*C-D+E/F/G+H
B A^B*(C-D)+(E/F)/G+H
C A^B*C-D+E/(F/(G+H))
D A^B*(C-D)+E/(F/(G+H))
前缀表达式的计算机求值特点:
从右至左扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(栈顶元素 op 次顶元素),并将结果入栈;重复上述过程直到表达式最左端,最后运算得出的值即为表达式的结果。
1)申请的内存所在位置
new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。
2)是否需要指定内存大小
new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算,而malloc则需要显式地指出所需内存的尺寸。
int *p1 = (int *)malloc(sizeof(int) * length);
int *p2 = new int[length];
C++提供了new[]与delete[]来专门处理数组类型:
A * ptr = new A[10];//分配10个A对象
使用new[]分配的内存必须使用delete[]进行释放:
delete [] ptr;
3) malloc/free是C/C++语言的标准库函数,new/delete是C++的运算符。
4) 是否可以被重载
opeartor new /operator delete可以被重载
而malloc/free并不允许重载。

malloc给你的就好像一块原始的土地,你要种什么需要自己在土地上来播种
而new帮你划好了田地的分块(数组),帮你播了种(构造函数),还提供其他的设施给你使用
3、全局存储区(也称为静态数据存储区)、栈(局部)、堆(动态)、代码存储区区别。
(1)全局存储区(也称为静态数据存储区)存储程序中的全体常数、全局变量、静态变量(全局静态变量和局部静态变量)、各类的静态数据成员。
存放在全局数据存储区中的数据具有生存周期长(自创建之时起直到程序执行结束时为止)、缺省初始值为0、存储区较大等特点。
(2)栈数据存储区(也称为局部数据存储区),它存储程序中各函数调用过程中的局部变量(包括函数形参和返回数据)。存放在栈区中数据具有生存周期短(自创建之时起到所在程序块执行结束为止)、无缺省初始值、存储区较小等特点。
(3)堆区,也称为动态数据存储区。它存储程序中各函数执行过程中用new运算符或malloc()函数动态申请分配的数据。存放在堆区数据具有生存周期不定(动态申请分配和动态释放)、无缺省初始值、存储区较大等特点。
(4)代码存储区。存储程序中全体函数(包括成员函数和非成员函数)的可执行二进制代码。
|
特征 |
全局存储区(静态) |
栈(局部) |
堆(动态) |
代码存储区 |
|
存储数据类型 |
全体常数、全局变量、静态变量(全局静态变量和局部静态变量)、各类的静态数据成员 |
各函数调用过程中的局部变量(包括函数形参和返回数据) |
各函数执行过程中用new运算符或malloc()函数动态申请分配的数据 |
存储程序中全体函数(包括成员函数和非成员函数)的可执行二进制代码。 |
|
初始值 |
缺省初始值为0 |
无缺省初始值 |
无缺省初始值 |
|
|
生存周期 |
长(自创建之时起直到程序执行结束时为止) |
短(自创建之时起到所在程序块执行结束为止) |
不定(动态申请分配和动态释放) |
|
|
区大小 |
较大 |
较小 |
较大 |
较大 |
4、多态性简单介绍:
指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。C++支持两种多态性:编译时多态性,运行时多态性。
a、编译时多态性:通过重载函数实现
b、运行时多态性:通过虚函数实现。
虚函数是在基类中被声明为virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态覆盖(Override)
- #include<iostream>
- using namespace std;
- class A
- {
- public:
- void foo()
- {
- printf("1 ");
- 10. }
- 11. virtual void fun()
- 12. {
- 13. printf("2 ");
- 14. }
15. };
16. class B : public A
17. {
18. public:
- 19. void foo()
- 20. {
- 21. printf("3 ");
- 22. }
- 23. void fun()
- 24. {
- 25. printf("4 ");
- 26. }
27. };
28. int main(void)
29. {
- 30. A a;
- 31. B b;
- 32. A *p = &a;
- 33. p->foo();
- 34. p->fun();
- 35. p = &b;
- 36. p->foo();
- 37. p->fun();
- 38. return 0;
39. }
第一个p->foo()和p->fuu()都很好理解,本身是基类指针,指向的又是基类对象,调用的都是基类本身的函数,因此输出结果就是1、2。
第二个输出结果就是1、4。p->foo()和p->fuu()则是基类指针指向子类对象,正式体现多态的用法,p->foo()由于指针是个基类指针,指向是一个固定偏移量的函数,因此此时指向的就只能是基类的foo()函数的代码了,因此输出的结果还是1。而p->fun()指针是基类指针,指向的fun是一个虚函数,由于每个虚函数都有一个虚函数列表,此时p调用fun()并不是直接调用函数,而是通过虚函数列表找到相应的函数的地址,因此根据指向的对象不同,函数地址也将不同,这里将找到对应的子类的fun()函数的地址,因此输出的结果也会是子类的结果4。
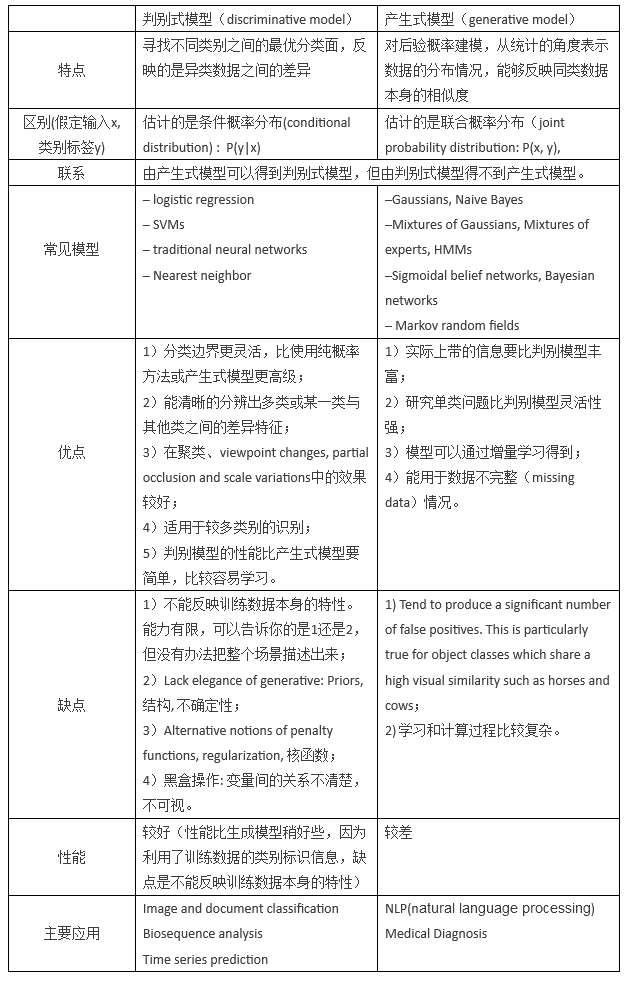
5、生成模型和判别模型
生成模型是使用联合概率建模,模拟这个结果是如何产生的,然后算出产生各个结果的概率。
如利用贝叶斯公式, 先对P(X|Y)进行建模, 然后利用训练集中的 P(Y) 求出联合**概率分布 P(X,Y)**, 最后除以X的概率分布P(X)得出我们的目标(P(Y|X)). 最常见的例子朴素贝叶斯. 生成模型需要做出更多的假设, 因此适用于数据较少的情况下, 但鲁棒性不强, 因为假设错了就效果很差了.判别模型直接使用条件概率P(Y|X)建模,发现各个结果之间的不同,不关心产生结果的过程。
典型的生成模型有:朴素贝叶斯法和隐马尔可夫模型HMM(重点的EM算法)、高斯混合模型GMM、LDA
典型的判别模型有:K近邻法、感知机、决策树、逻辑斯谛回归模型、最大熵模型、SVM、提升方法和条件随机场CRF。
6、#include< > 和 #include” ” 的区别
一、#include< >
#include< > 引用的是编译器的类库路径里面的头文件。
假如你编译器定义的自带头文件引用在 C:Keilc51INC 下面,则 #include<stdio.h> 引用的就是 C:Keilc51INCstdio.h 这个头文件,不管你的项目在什么目录里, C:Keilc51INCstdio.h 这个路径就定下来了,一般是引用自带的一些头文件,如: stdio.h、conio.h、string.h、stdlib.h 等等。
二、#include" "
#include" " 引用的是你程序目录的相对路径中的头文件。
假如你的项目目录是在 D:Projects mp ,则 #include"my.h" 引用的就是 D:Projects mpmy.h 这个头文件,一般是用来引用自己写的一些头文件。如果使用 #include" " ,它是会先在你项目的当前目录查找是否有对应头文件,如果没有,它还是会在对应的引用目录里面查找对应的头文件。例如,使用 #include "stdio.h" 如果在你项目目录里面,没有 stdio.h 这个头文件,它还是会定位到 C:Keilc51INCstdio.h 这个头文件的。