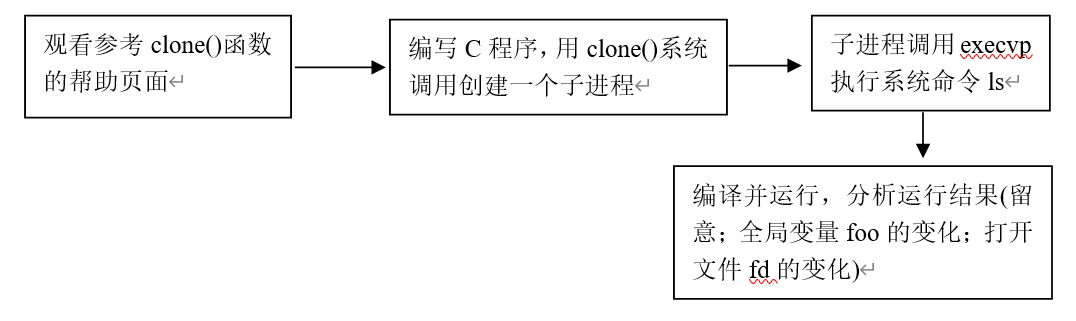
一、实验目的
- 重温进程概念,理解Linux中的进程
- 理解Linux中进程的产生方式,理解fork()与clone()的差别
- 了解Linux中的线程
二、实验内容
- 分析系统调用sys_exit
- 用fork()系统调用创建一个子进程
- 用clone()系统调用创建一个Linux子进程
三、实验准备
1.Linux进程:
1.1.进程的概念:
- 进程不只是一个运行中的程序,还包括这个运行中的程序占据的所有系统资源,即CPU(寄存器)、IO、内存、网络资源等。
- 对于单CPU系统,系统中有多个进程,操作系统轮流让每个进程执行一段时间(用系统的术语来说是时间片),并且让每个进程看来是它自己独占了整个系统资源。操作系统通过进程调度来调度每个进程,并且通过虚拟内存机制来保护每个进程自己独立的内存地址空间,这样,某一个进程的退出或者崩溃都不会对其他的进程或者整个系统有任何影响。
1.2.Linux进程控制块:
- 在Linux中,每个进程由一个task_struct结构表示,在这个结构体里,包含这个进程的所有资源。task_struct相当于进程在内核中的描述。
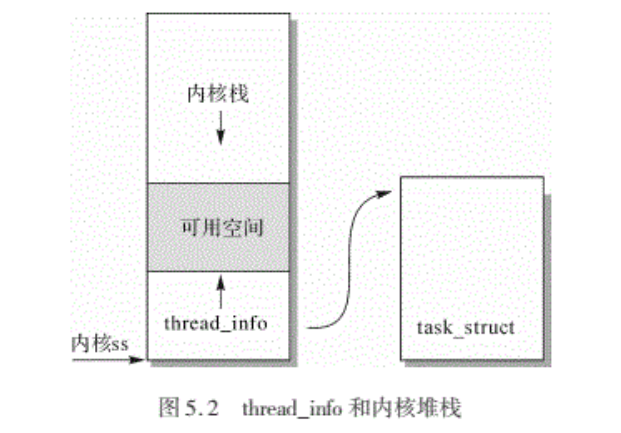
1.2.1.task_struct与内核栈:
- thread_info结构与内核栈放在同一个页面中,thread_info中放置一个指向task_struct的指针,这样可以很方便的管理进程,current宏内部实现中,先根据内核堆栈的位置找到thead_info,然后再根据thread_info找到进程的task_struct。
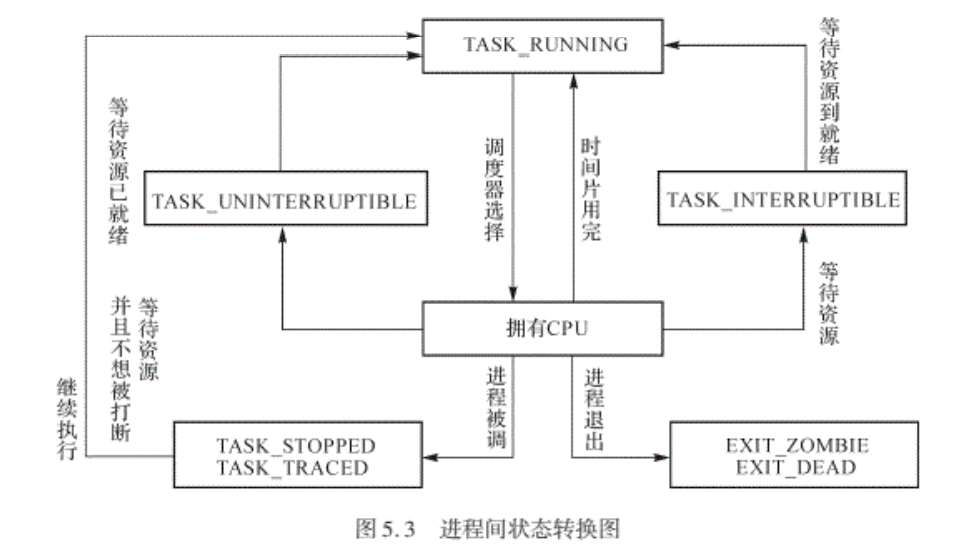
1.2.2.状态转换:
- volatile long state:内核状态,用来表示进程的可运行性
- long exit_state:内核状态,用来表示进程退出时的状态
1.2.3.进程标志位:
- 为了对每个进程运行进行更细粒度的控制,还有一些进程标志位。在task_struct中有变量flags,这个变量可取一些标志及标志的组合:
- unsigned long flags; /* per process flags,defined below */
1.2.4.进程与调度:
- task_struct中与进程调度相关的一些变量有:
- unsigned long policy:进程调度策略
- 每个进程都有自己的调度策略,系统中大部分进程的调度策略是SCHED_NORMAL,有root权限的进程能改变自己和别的进程的调度策略。调度器根据每个进程的调度策略给予不同的优先级。
- 进程的调度优先级:
+int prio,static_prio;unsigned long rt_priority;- prio是进程的动态优先级,随着进程的运行而改变,调度器有时候还会根据进程的交互特性、平均随眠时间等进行奖惩。
- static_prio为普通进程的静态优先级
- rt_priority为实时进程的静态优先级
1.2.5.进程id、父进程id、兄弟进程:
- 每个进程都有自己独立的一个id:pid_t pid;
- 每个进程(init进程除外)都是由父进程派生出来(关于这一点,我们在进程的产生中会详细讲述),并且也可能有自己的兄弟进程(指属于同一个父进程的进程)。所有这些进程组成一个类似于家族的关系。
1.2.6.用户id、组id:
- task_struct里面维护了一些根文件系统权限控制相关的变量:
- uid_t uid,euid,suid,fsuid;
- gid_t gid,egid,sgid,fsgid;
- uid:是创建这个进程的用户的id,系统根据这些id控制每个用户的权限
- euid:effective uid,即有效uid,系统通过一个进程的euid来判断进程的权限的。大多数情况,uid和euid是相等的,但是有时候,进程需要以可执行文件的属主来运行哪个程序,而不是以可执行程序的用户来运行。这时,euid就是那个可执行文件的属主的用户id。
- suid:当有时候必须通过系统调用改变uid和gid的时候,需要用suid来保存真实的uid。
- fsuid:是Linux内核检查进程对于文件系统访问时所参考的位,一般来说等同于euid,当euid改变的时候,fsuid也会相应地被改变。
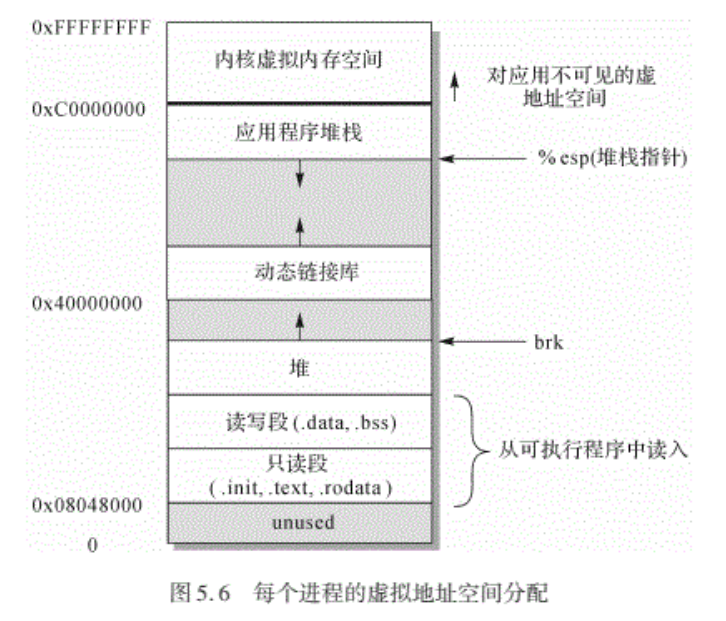
1.2.7.进程与虚拟存储、进程的地址空间、内存分布:
- 物理地址: 是真正的对物理内存的地址,有多大的物理内存,就有多大的对应的物理地址空间,当然这个空间不一定是从0开始,甚至有时候也不一定是连续的。
- 虚拟地址:出于按需调页(进程的物理页面只有在需要的时候才被调入内存)的设计,和对进程间相互地址空间的保护,现代操作系统都引入了分页式内存管理、虚拟地址等概念。虚拟地址是另外一套地址,它不受限于具体的物理内存大小,而只是因为不同的硬件体系结构不同而有所不同。

- 虚拟地址对于进程管理的有优点:
- 每一次进程被装载入内存,位置可以是不一样的,操作系统管理每个进程装载入内存的位置,并做好虚拟地址到物理地址的映射。程序员编写代码不用关心代码被装载到内存那个地方。
- 每个进程都有自己的地址空间这意味着能同时运行多个进程,即使这些进程来自同一个程序,它们的地址空间也不会发生冲突。而且,通过把不同进程的虚地址映射到同样的物理地址,还能方便地实现进程间内存共享,这是很重要的一种进程间通信机制。
1.2.8.进程自己的资源:
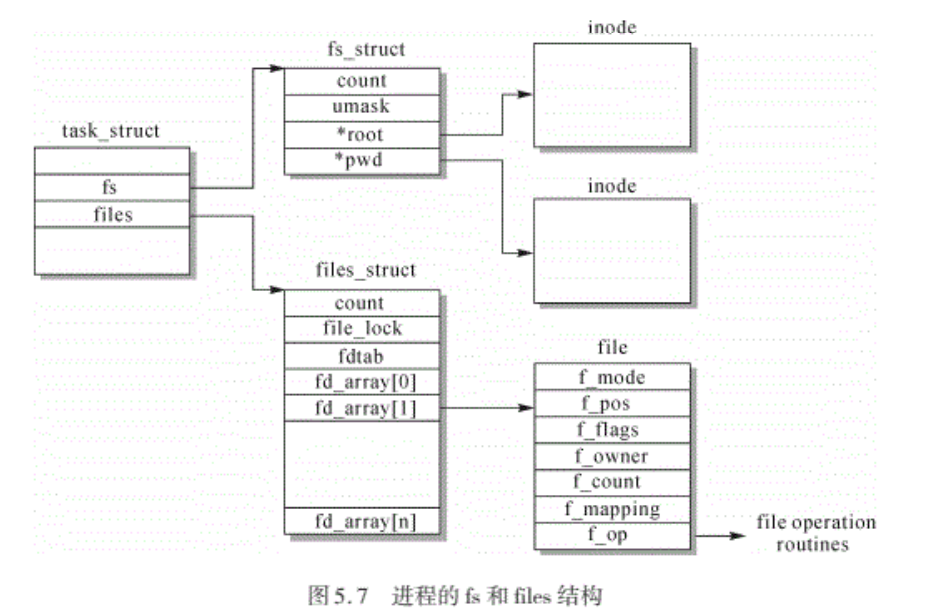
- 从task_struct可以链接到很多属于该进程的资源,fs和files结构主要用于管理进程当前的目录状况和进程打开的所有文件。
2.Linux进程创建及分析:
2.1.第一个进程:
- 第一个进程事实上就是Linux kernel本身。像所有其他的进程一样,Linux kernel本身也有代码段、数据段、堆栈。只不过Linux kernel这个进程自己来维护这些段,这一点是与其他进程不同的地方。第一个进程是唯一一个静态创建的进程,在Linux kernel编写并且编译的时候创建。
2.2.fork、clone、kernel、thread:
- 系统中其他的进程都通过复制父进程来产生,Linux提供两个系统调用fork和clone来实现个功能,广义上都叫它们为fork(),表示一个进程分叉产生两个进程;Linux后来为了线程实现的1方便,引入了轻量级进程的概念,通过clone系统调用产生。而它们的底层都是调用do_fork()。
- 调用fork的进程叫做父进程,由此调用而产生的进程叫子进程。父进程和子进程都会从fork()调用中返回,父进程返回的是子进程的pid,子进程从fork()返回的是0,所以如果想让父进程和子进程走不同的路径,可以通过判断fork()调用的返回值实现。
2.2.1.fork分析:
- fork()主要做下面这些事:
- 为新进程分配一些基本的数据结构。具体到Linux,最重要的比如一个新的进程号pid,一个task_struct和一个8K大小的联合体(存放thread_into和内核栈)等。
- 共享或者拷贝父进程的资源,包括环境变量、当前目录、打开的文件、信号量以及处理函数等。
- 为子进程创建虚拟地址空间。子进程可能跟父进程共享代码段,数据段也可能采用COW(写时拷贝)的策略使fork()的速度与灵活性得到提高。
- 为子进程设置好调度相关的信息,使得子进程在适当的时候独立于父进程,能被独立调度。
- fork()的返回。对于父进程来说,fork()函数直接返回子进程的pid;而对于子进程来说,是在子进程被第一次调度执行的时候,返回0。
2.2.2.clone()分析:
- clone的直译是克隆,指的是子进程基本完全复制父进程。clone的产生源于应用层对于线程的需求。Linux从自己的角度重新解释了应用层的需求,提出了“轻量级进程(lightweight process)”的概念。提供给应用层clone系统调用。它不但能用于产生传统意义上的线程,更有精细的参数,可以控制子进程与父进程之间共享的内容。
- clone()与fork()类似,也是用来产生一个新进程的。不同之处在于clone()允许子进程跟父进程共享一些上下文,比如内存、打开文件描述符、信号处理函数表等。
- clone()给予用户很大的自由来定义子进程跟父进程共享哪些内容,定义一个新的子进程“轻量级”的程度。
2.3.exec装载与执行进程:
- 在Linux中,exec调用用于从一个进程的地址空间中执行另外一个进程,覆盖自己的地址空间。有了这个系统调用,shell就可以使用fork+exec的方式执行别的用户程序了。一个进程使用exec执行别的应用程序之后,它的代码段、数据段、bss段和堆栈都被新程序覆盖,唯一保留的是进程号。
2.4.Linux中的线程:
2.4.1.Linux线程的实现方式及特点:
- 在Linux中,线程实际上被看作是“轻量级进程”。在Linux各种线程库的实现中(比如LinuxThreads),现在使用比较普遍的库通常都遵循的是1:1模型(即一个内核线程对应一个用户线程),在这种实现中,线程是通过clone()系统调用来产生的,所以一个用户线程一定对应了一个内核线程。线程是用系统调用clone创建的,它允许创建出来的新进程共享父进程的内存空间、文件描述符和软中断处理程序等。
- 特点:
- 在对CPU资源要求较多的多处理中,最小的损耗代价
- 最小损耗代价的I/O操作
- 一种简单而稳定的实现(大部分困难的工作由内核调度程序替我们做了)
- 在锁和条件的操作中线程切换的代价过高,因为必须通过内核去切换
2.4.2.Linux核心对线程的支持:
- Linux核心对线程的支持主要是通过其系统调用clone()。对于子进程的创建,clone()系统调用可以进行很详细地控制,这样调用者可以根据自己的需求创建出轻量级进程
四、实验思路
-
1.分析系统调用sys_exit函数:
-
2.用fork()创建子进程:

-
3.用clone()创建子进程: