空间众包:任务发起者利用智能手机等移动设备的定位信息,请求与具体位置紧密相 关的数据,自愿参与完成任务的用户行驶到任务指定的具体地点收集相关的数据, 然后将数据返回给任务请求者。(①空间众包平台上的工人只能参与完成分布在其附近的一小部分任务②完成任务的必要条件是在任务过期之前,实际行驶到任务指定的地点)
空间众包应用:新闻、旅游、情报、灾害响应和城市规划等
空间众包分类:
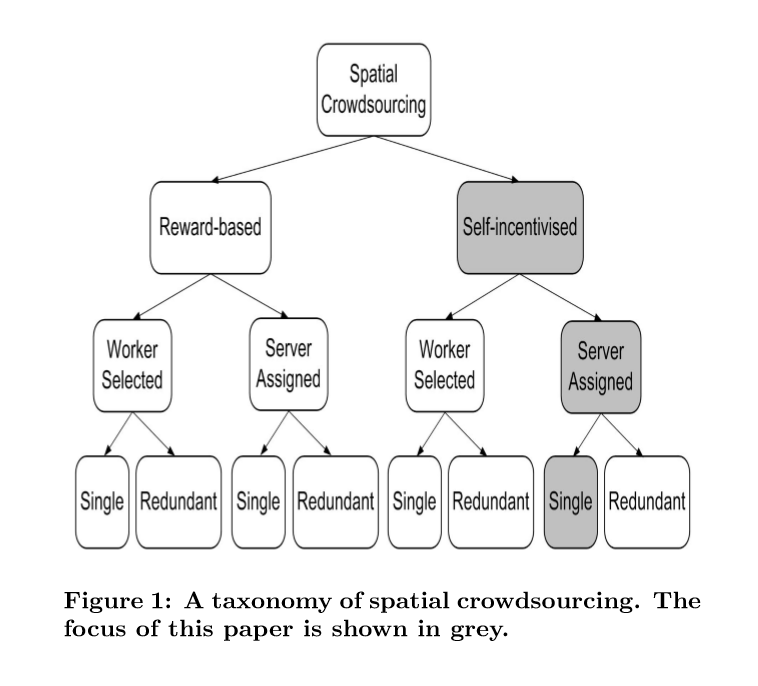
1.工人的动机: ①基于奖励的众包机制 ②自我激励的众包机制
2.任务发布模式:
①以用户为中心的模式(WST)
优点:工人可自主选择附近的任何任务,无需为每次任务向
服务器透露自己的位置。
缺点:①SC服务器对空间任务分配没有任何的控制权,这
可能导致某些空间任务从未被分配,而其他任务则被
冗余分配。
②工人根据自己的目标选择任务,这不一定是SC服
务器的的最终目标
②以平台为中心的模式(SAT)
优点:可以在最大化整体任务分配(即,全局优化)的同时为
每个工人分配他的附近任务。
缺点:工作人员应为每项任务向SC服务器报告其位置,这
可能构成隐私侵犯
3.任务分配方法(验证空间任务的有效性):
①基于单人的任务分配
在此分配方法中,一般假设工人是受信任的,他们可以正确完成
空间任务,而且没有恶意意图。因此,每个空间任务仅分配给一
个工人(最好分配给最近的工人)
②带冗余的任务分配
在此分配方法中,基于群体智慧的直观假设,大多数人都可以信
任。因此,具有多数票的数据是正确的。每个空间任务应由k个
附近的工人完成,其中k由发出任务的请求者定义。因此,k值
越大,任务完成的正确率就越大。
本论文要解决的问题是什么?
前提条件:SAT模式、自我激励、基于单人的任务分配
众包从业者,将其任务查询请求发送到SC服务器。工人的任务查询请求包括其位置以及一些约束条件(例如,区域),以告知SC服务器他有空工作。因此,接受到工人请求的SC服务器将其附近的任务分配给每个工人。在此类空间众包中,主要的优化目标是在符合工人的约束条件的同时最大化总体的任务分配数量。
最大化任务分配数量(MTA)
(SC服务器不断接收空间任务,并从工人那里不断地接收任务查询请求,因此,SC服务器只能在每一个时间点最大化任务分配(即,局部优化),无法知晓未来)
预备工作:
空间任务 <l,q,s,δ>表示需在二维空间位置l处应答查询q,查询q在时间s时被发出,并将在时间s+δ过期。(只有当工人实际位于位置l时,才能应答空间任务的查询q)
空间众包查询 (<t1,t2,…>,k)是请求者发出的一组空间任务和参数k,其中每个空间任务ti将被完成k次。(注意,在单人任务分配模式下,SC服务器应将每个空间任务仅分配给一个工人,即k=1)
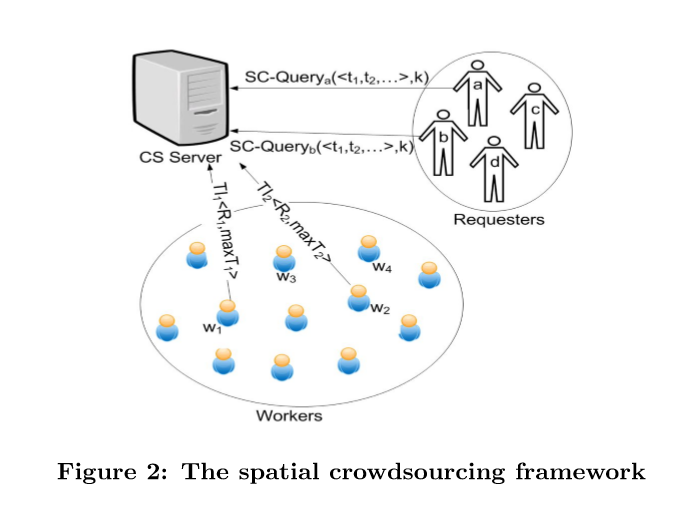
工作者 用w表示工人,工人是自愿完成空间任务的移动设备的载体。工人可以处于在线状态或者离线状态。工人要在在线状态接收任务。(请注意,在自我激励机制下,工人自愿执行空间任务,工人一旦上线,他就会向SC服务器发送任务查询请求)
任务查询 任务查询是当在线工人w准备去工作得时候向SC服务器发送的一个请求。请求中含有w的位置信息l,以及两个约束空间区域R和可接受任务的最大数目maxT。工人在矩形表示的空间区域R中接受任务,该区域以外的任何任务都将被工人拒绝。maxT是工人愿意执行的任务的最大数量。(任务查询是针对SAT模式定义的,在此模式下,工人将其位置发送给SC服务器以正确的分配任务。工人还可以在他们的任务查询请求中指定其他约束(例如,任务的类别,他们有多少时间)。但在此文中我们将考虑两个约束(R和maxT))
任务分配实例集 记Wi={w1,w2,…}为时间si时的在线工作者集,同时记Ti={t1,t2,…}为时间si时的可用的的任务集。Ii表示的任务分配实例集,由<w,t>形式的元组组成。元组表示空间任务t被分配给工人w,并且满足工人w的约束条件。li表示在时间si时分配的任务数。(任务分配实例集必须符合工人的约束条件。对于每个元组<w,t>∈Ii,空间任务t的位置必须在工人w的空间区域R内。此外,每个工人最多可以分配maxT个任务(即,Ii中包含w的元组的数量最多为maxT))
最大任务分配 给定一个时间集合∅={s1,s2,…,sn},让Ii为时间时刻si上分配的任务数。最大任务分配是一个在时间∅内向工人分配任务,使总的任务数量(即,∑_(i=1)^n▒〖Ii〗)最大化。(理想情况下,所有任务都将分配给所有工人。但是由于,工人的约束条件,这不太可能实现。因此,本文的目标是使分配的的任务数量最大化)
一个例子
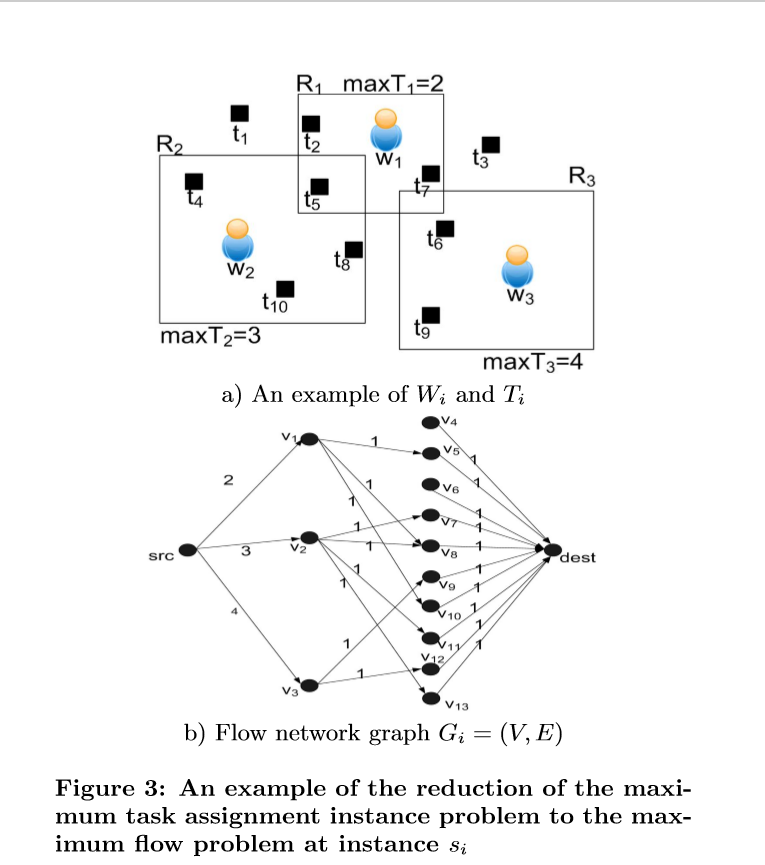
本论文解决问题的方法:
将问题转换为最大流量问题。
1.贪婪策略(GR):通过在每个时间点最大化任务分配来达到局部优化策略。贪婪策略在工人的约束条件下分配给每个工人其附近的任务。Ford-Fulkerson算法等计算最大流量的算法。
2.最小区域信息熵优先级(LLEP):利用区域信息熵来改进贪婪策略。如果空间任务位于工人数量较多的区域(即,较高的区域信息熵),则将来更有可能执行该空间任务。因此,LLEP方法将较高的优先级分配给区域信息熵较低将来不太可能完成的空间任务,从而改善总体任务分配。LLEP策略通过计算每个时间实例的最小成本最大流来解决MAT问题,其中成本是根据任务的区域信息熵来定义的。
3.最近邻优先级(NNP):由于工人应亲自前往某个位置以执行任务,因此工人的差旅成本也是一个重要因素。此方法通过为差旅成本较低的任务分配更高的优先级,将工人的差旅成本纳入任务分配。
用工人w和空间任务t之间的欧几里得距离表示工人w到任务t的旅行成本,记为d(w,t)。因此,通过计算每个工人与其空间区域内的任务的距离,可以将较高的优先级与较接近 的任务相关联。可以将一定成本,即工人w与任务t之间的距离,与工人w和空间任务t之间的每条边相关联。因此,问题为在每个时间实例中分配最大数量的任务,而分配的总成 本最低。在此方案下,问题变成最小成本最大任务分配实例问题,可以使用与2类似的解决方案,但具有不同的成本函数来解决此问题。
评估方法:
性能指标:①分配的任务总数 ②工人执行空间任务的平均差旅成本,差旅成本根据工人与任务位置的之间的欧几里得距离(其他指标也时用,例如网络距离)来衡量。
整个的空间面积为50km50km,时间集合∅={s1,s2,…,sn}为100天,时间实例的粒度为1天,每个空间任务的持续时间设置为40天(即δ=40),任务数量默认为100k(变化范围50k-200k),工人数量固定为10k,maxT范围1-20,R范围整个区域的0.01~0.05。区域信息熵范围30m30m。
1.第一组实验:改变空间任务的数量
2.第二组实验:最大可接受任务约束的影响
3.第三组实验:空间区域约束的影响
代码:
思路:求解某一时刻的最大任务分配,从文件中读取数据,点数,边数,源点序号,汇点序号,每边的起点,终点,容量。依据数据构建网络流图是,使用dinic算法求解最大流。
想法和体会:
1.实验中未考虑任务的时效性
2.工人接受任务的最大数量和行动范围应该是不确定的
论文文献:GeoCrowd: Enabling Query Answering with Spatial Crowdsourcing