Feature Pyramid Networks for Object Detection 特征金字塔网络用于目标检测
论文背景:
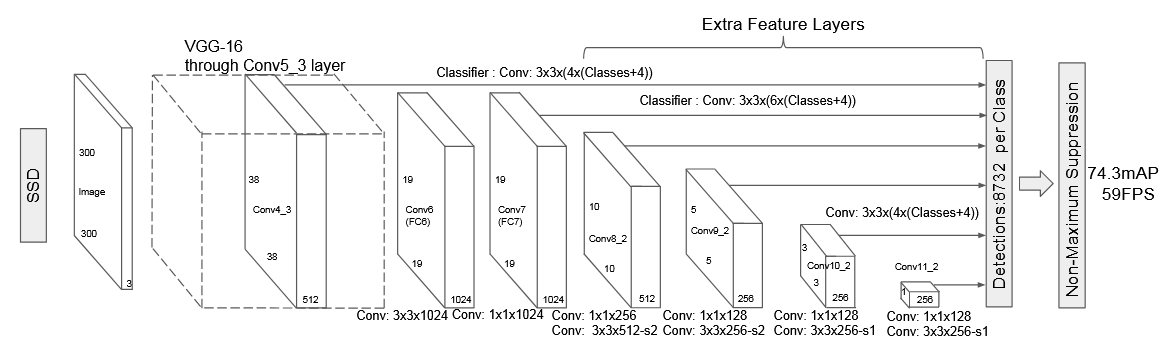
特征金字塔是用于检测不同尺寸物体的识别系统的基本组成部分。但是最近的深度学习目标检测方法避免了使用金字塔表示,部分原因在于它是计算和内存密集型的。Fast R-CNN和Faster R-CNN主张使用单一尺度计算特征,因为它提供了精确度与速度之间良好的折中,然而多尺度检测仍然表现更好,特别是对小目标检测。SSD(Single Shot MultiBox Detector)利用不同层的特征图进行不同尺寸的目标预测,效果又快又好,SSD为了预测小目标,就得把比较低的层拿出来进行预测,较低的层语义特征较弱,很难保证精确度。
多尺度目标检测是计算机视觉领域的一个基础且具有挑战性的课题。在图像金字塔(Image Pyramids)基础上构建的特征金字塔(Feature Pyramids)是基本的解决办法。这些金字塔是尺寸不变的,因此目标尺寸的变化是通过偏移其在金字塔中的级别来实现。除了可以表达高等级的语义信息,卷积网络更具鲁棒性,即使这样金字塔也同样被需要,因为它可以得到更加精确的结果,尤其是在多尺度检测上。金字塔结构的优势是其产生的特征每一层都是语义信息加强的,包括高分辨率的底层。
对图像金字塔的每一层都进行特征提取存在显而易见的局限性,首先运算耗时会增加4倍,而且训练深度网络非常耗显存,几乎没法用,即使用了也只能在测试(test)阶段用,而这又会导致训练/测试的不连续。因为这些原因Fast R-CNN 和Faster R-CNN默认的设置是不使用Featurized Image Pyramids。
SSD的处理方式
图像金字塔(Featurized Image Pyramid)并不是多尺度特征表示的唯一方式。CNN计算的时候本身就存在多级特征图(Feature Map Hierarchy),且不同层的特征图尺度就不同,形如金字塔结构。结构上虽然不错,但是前后层之间由于不同深度(depths)影响,语义信息差距太大,主要是高分辨率的低层特征很难有代表性的检测能力。
SSD方法在借鉴利用Featurized Image Pyramid上很值得一说,为了避免利用太低层的特征,SSD从偏后的Conv4_3开始,又往后加了几层,分别抽取每层特征,但是SSD对高分辨率的低层特征没有再利用,而这些层对检测小目标很重要。
本文的方法
本文中,作者利用了固有的多尺度和锥形层次结构的卷积网络来构造具有边际额外成本的金字塔网络,开发具有侧向连接(Skip Connector)的自顶向下的架构,用于在所有尺度上构建高级语义特征图,依靠一种通过自上而下的路径和横向连接将低分辨率但语义强的特征与高分辨率语义弱的特征结合在一起,这样就可以获得高分辨率,强语义的特征,有利于小目标的检测。这种结构是在CNN网络中完成的,和前文提到的基于图片的金字塔结构不同,而且完全可以替代它。

- (a):使用一个图像金字塔来构建一个特征金字塔。每个不同的图像尺寸上都需要单独计算特征,很慢
- (b):最近的检测系统已经选择使用单一尺寸的特征用于更快的检测。
- (c):重用卷积网络计算的金字塔特征等级,像Featurized Image Pyramid
- (d):本文提出的方法,Feature Pyramid Network(FPN),和(b),(c)一样快,但是更精确
简单总结下:
- (a):用图片金字塔生成特征金字塔
- (b):只在特征的最上层进行预测
- (c):特征层分层预测
- (d):FPN从高层携带信息传给低层,再分层预测,本文作者的创新之处就在于既使用了特征金字塔,又搞了分层预测。
特征金字塔结构
本论文的目标是利用CNN的金字塔层次结构特性(具有从低到高的语义),构建具有高级语义的特征金字塔。得到的特征金字塔网络(FPN)是通用的,但在论文中,作者先在RPN网络和Fast R-CNN中使用这一成果,也将其用在instance segmentation proposals中。
该方法将任意一张图片作为输入,以全卷积的方式在多个层级输出成比例大小的特征图,这是独立于CNN骨干架构(该论文中是ResNets)的。
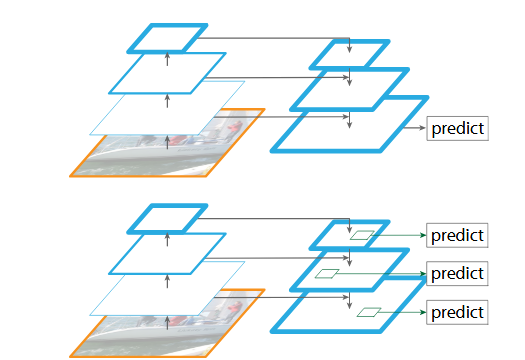
- Top:自上向下的带有侧连接(Skip Connections)的结构,预测发生在最好的一层
- Bottom:作者提出的模型跟这个相似,利用它作为一个特征金字塔,各个级别的预测都是独立的
自下而上的路径
CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出和原来大小一样,称为“相同网络阶段”(same network stage)。对于本文中的特征金字塔,作者为每个阶段定义一个金字塔级别,然后选择每个阶段的最后一层的输出作为特征图的参考集。这种选择是很自然的,因为每个阶段的最深层应该具有最强的特征。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2,C3,C4,C5},对应于Conv2,Conv3,Conv4,Conv5的输出,并且注意他们相对于输入图像具有{4,8,16,32}像素的步长。考虑到内存占用,没有将Conv1包含在金字塔中。
自上而下的路径和横向连接
自上而下的路径是如何去结合低层高分辨率的特征呢?方法就是,把更抽象,语义更强的高层特征图进行取样,然后把该特征横向连接(lateral connections)至前一层特征,因此高层特征得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同,这样做主要是为了利用低层的定位细节信息。
把高层特征做2倍上采样(最近邻上采样法),然后将其和对应的前一层特征结合(前一层要经过1*1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合的方式就是像素间的加法。重复迭代该过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加了一个1*1的卷积核来产生最粗略的特征图,最后,作者用3*3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。{C2,C3,C4,C5}层对应融合特征层为{P2,P3,P4,P5},对应的层空间尺寸是相通的。

金字塔结构中所有层级共享分类层(回归层),就像Featurized Image Pyramid中所做的,作者规定所哟特征图中的维度(通道数,表示为d)。作者在本文中设置d=256,因此所有额外的卷积层(比如P2)具有256通道输出,这些额外层没有用非线性,非线性会带来一些影响。
实际应用
本文方法在理论上在CNN中是通用的,作者将其首先应用到了RPN和Fast R-CNN中,应用中尽量做小幅度的修改。要想明白FPN如何应用在RPN和Fast R-CNN(合起来就是Faster R-CNN),首先要明白Faster R-CNN + Resnet-101结构。
Faster R-CNN + Resnet-101
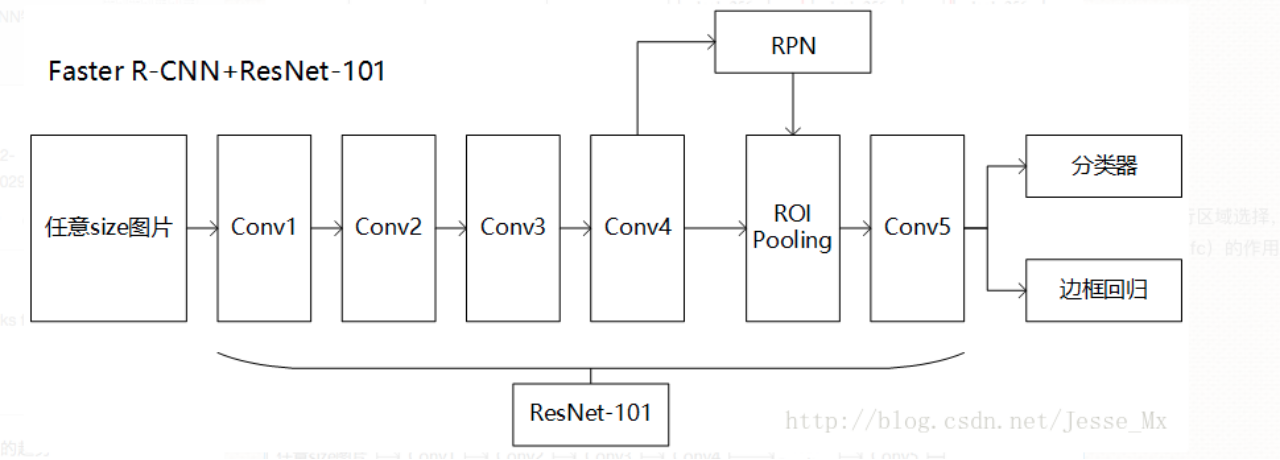
Faster R-CNN利用Conv1~Conv4-x的91层为共享卷积层,然后从Conv4-x的输出开始分叉,一路经过RPN网络进行区域选择,另一路直接连一个ROI Pooling层,把RPN的结果输入ROI Pooling层,映射成7*7的特征。然后经过Conv5-x的计算,这里Conv5-x起到原来全连接层(fc)的作用,最后经过分类器和边框回归得到最终的结果。
RPN中的特征金字塔网络
RPN是Faster R-CNN中用于区域选择的子网络,RPN是一个13*13*256的特征图上应用9种不同尺度anchor,本文另辟蹊径,把特征图弄成多尺度的,然后固定每种特征图对应的anchor尺寸,也就是说每一个金字塔层级应用了单尺度的anchor,{P2,P3,P4,P5}分别对应的anchor尺度为{32^2,64^2,128^2,256^2,512^2},当然目标不可能都是正方形,本文仍然使用三种比例{1:2,1:1,2:1},所以金字塔结构中共有15中anchors。(没有画完整,缺256^2,512^2)

训练中,把重叠率(IoU)高于0.7的作为正样本,低于0.3的作为负样本。特征金字塔网路之间有参数共享,其优秀表现使得所有层级具有相似的语义信息。具体性能在实验中评估。