简述
pod的横向自动伸缩
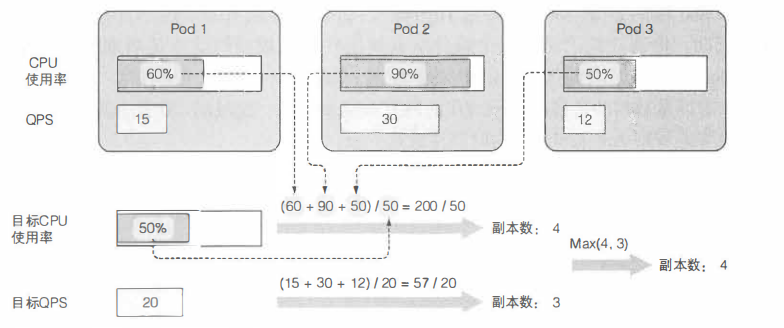
获取pod度量
计算所需的 pod 数量
更新被伸缩资源的副本数



• Deployment
• ReplicaSet
• ReplicationController
• StatefulSet
目前也只有这些对象可以附着Autoscaler。
基于CPU使用率创建HPA
创建deployment 资源 apiVersion: extensions/vlbetal kind: Deployment metadata: name: kubia spec: replicas: 3 #手动设置(初始)想要的副本数为3 template: metadata: name: kubia labels: app: kubia spec: containers: - image: luksa/kubia:vl name: nodejs resources: requests: cpu: 100m #每个pod请求100毫核的CPU 创建了Deployment之后, 为了给它的pod 启用横向自动伸缩 , 需要创建一个 HorizontalpodAutoscaler (HPA)对象, 并把它指向该Deployment。 $ kubectl autoscale deploymen七kubia --cpu-percent=30 --min=l --max=5 这会帮你创建 HPA对象,并将叫作kubia的Deployment设置为伸缩目标。你还设置了pod的目标 CPU使用率为30%, 指定了副本的最小和最大数量。Autoscaler会持续调整副本的数量 以使CPU使用率接近30%, 但它永远不会调整到少于1个或者多于5个。 提示:一定要确保自动伸缩的目标是Deployinent 而不是底层的 ReplicaSet。 这样才能确保预期的副本数量在应用更新后继续保持(记着 Deployment 会给每个应用版本创建一个 新的 ReplicaSet)。 手动伸缩也是同样的道理。
修改一个已有 HPA 对象的目标度量值
可能你 开始设置的目标值30 有点太低了,我们把它提高到 你将使用 kubectl edit 命令来完成这项工作。文本编辑器打开之后,把 targetAverageUtilization 字段改为 60,
正如大多数其他资源 样,在你修改资源之后, Autosca er 控制器会检测到这一变更,并执行相应动作 也可以先删除 HPA 资源再用新的值创建一个,因为删除HPA 资源只会禁用目标资源的自动伸缩(本例中为 Deployment ,而它的伸缩规模会保持在删除资源的时刻 在你为 Deployment 创建一个新的 HPA 资源之后,自动伸缩过程就会继续进行
... spec: maxReplicas: 5 metrics: - type: Resource resource: name: cpu targetAverageUtilization:30 ...
如上所示, metrics 字段允许你定义多个度量供使用。在代码清单中使用了单个度量。每个条目都指定相应度量的类型一一本例中为一个 Resource 度量。可以在HPA 对象中使用三种度量:
Resurce 量类型
pods 度量类型
... spec: metrics: - type: Pods resource: metricName: qps targetAverageValue:100 ...
Object 度量类型
... spec: maxReplicas: 5 metrics: - type: Object resource: metricname: latencyMillis #度量名称 target: #autoscale 从中获取度量的特定对象 apiVersion: extensions/vlbetal kind: Ingress name: frontend targetValue: 20 scaleTargetRef: #autoscale 将要管理的可伸缩资源 apiVersion: extensions/vlbetal kind: Deployment name: kubia ...
该例中 HPA 被配置为使用 Ingress 对象 frontend 的 latencyMillis 度量,目标值为 20 。HPA 会监控该 Ingress 度量,如果该度量超过了目标值太多autoscaler 便会对 kubia Deployment 资源进行扩容了。
pod 的纵向自动伸缩
集群节点的横向伸缩
Cluster Autoscaler负责在由于节点资源不足, 而无法调度某pod到已有节点时,自动部署新节点。它也会在 节点长时间使用率低下的情况下下线节点。
从云端基础架构请求新节点
归还节点
节点也可以手动被标记为不可调度并排空。 不涉及细节, 这些工作可用以下 kubectl 命令完成: • kubectl cordon <node> 标记节点为不可调度(但对其上的 pod不做任何事)。 • kubectl drain <node> 标记节点为不可调度, 随后疏散其上所有pod。 两种情形下, 在你用 kubectl uncordon <node> 解除节点的不可调度状态之前, 不会有新 pod被调度到该节点。
$ kubectl create pdb kubia-pdb --selector=app=kubia --min-available=3 poddisruptionbudget "kubia-pdb" created
现在获取这个pod 的YAML文件, 如以下代码清单所示。

也可以用 一个百分比而非绝对数值来写minAvailable字段。 比方说,可以指定60%带app=kubia标签的pod应当时刻保持运行。注意从Kubemetes 1. 7开始podDismptionBudget资源也支持maxUnavailable。如果当很多pod不可用而想要阻止pod被剔除时,就可以用maxUnavailable字段而不是minAvailable。