难的不是技术,难的是业务。熟悉业务流程才是最难的。
其实搜索进来的每一个人的需求不一样,希望你能从我的这篇文章里面收获到。
建议还是看官方文档,更全面一些。
一、背景
1,收集nginx access error日志,nginx日志最开始是main日志,后来被我改成了json日志方便收集
2,收集php info error日志,php日志就是标准的
3,每一个php服务都是docker容器启动
4,每一个php容器服务里面都有一个nginx服务
5,需要收集日志的php服务大概30个
6,k8s集群三台节点
7,需要收集qa,dev环境日志,qa,dev其实就是k8s集群里面的两个namespaces
8,需要提取特定的字段
1.1 日志目录
每一个php容器服务都是这个日志结构
/var/log/nginx/access.log
/var/log/nginx/error.log
/var/www/html/storage/logs/lumen.log
/var/www/html/storage/autoLogs/sysError/lumen.log
1.2 思考点&解决方案
1,采集的Beat用哪个
filebeat:轻量级,cpu 内存小,咱们的需求只是单纯的采集数据。进程稳定。
2,Beat的部署方式
filebeat部署在k8s 节点宿主机,二进制部署
3,日志的采集方式
Php容器日志目录挂载到宿主机
4,qa,dev环境怎么区分
kibana区分用index
容器日志目录挂载到宿主机。
$env=qa,dev
$appname=php所有的服务名称
/data/service-logs/${env}/${appname}/{nginx,storage/{logs,autoLogs/sysError/}}
例如:wxx 服务的dev环境宿主机目录结构
/data/service-logs/dev/wxx/nginx/ 这个下面有access error日志
/data/service-logs/dev/wxx/storage/logs/ php info日志
/data/service-logs/dev/wxx/storage/autoLogs/sysError/ php error日志
5,怎么区分php服务
kibana:添加字段app_name
6,日志类型怎么区分
kibana:添加字段log_topics
二、集群服务器配置
我这里采用的是3节点,其实主要就是es集群。
这样的配置足够我这的需求了,你可以按照需求调整。
我这里大概每小时收集5万条数据。每天数据量大概是2G。
| ip | cpu | mem | 软件 |
| 192.168.31.61 | 4 | 8G | es,kibana,cerebro |
| 192.168.31.62 | 4 | 8G | |
| 192.168.31.63 | 4 | 8G |
三、部署服务
3.1 部署es
3.1.1 下载
cd /opt/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-linux-x86_64.tar.gz
3.1.2 配置
tar xf elasticsearch-7.12.1-linux-x86_64.tar.gz
cd /opt/elasticsearch-7.12.1/config
node1
vim elasticsearch.yml
cluster.name: dev-qa-es # 集群的名称
node.name: 192.168.31.61 # node1节点的名称
path.data: /data/elasticsearch/data # 数据目录
path.logs: /data/elasticsearch/log # 日志目录
network.host: 192.168.31.61 # 节点的ip 就是监听的地址
http.port: 9200 # es端口
discovery.seed_hosts: ["192.168.31.62", "192.168.31.63"] # 除自己之外的两个节点
cluster.initial_master_nodes: ["192.168.31.61", "192.168.31.62", "192.168.31.63"] # 所有的master
node2
cluster.name: dev-qa-es
node.name: 192.168.31.62
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/log
network.host: 192.168.31.62
http.port: 9200
discovery.seed_hosts: ["192.168.31.61", "192.168.31.63"]
cluster.initial_master_nodes: ["192.168.31.61", "192.168.31.62", "192.168.31.63"]
node3
cluster.name: dev-qa-es
node.name: 192.168.31.63
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/log
network.host: 192.168.31.63
http.port: 9200
discovery.seed_hosts: ["192.168.31.61", "192.168.31.62"]
cluster.initial_master_nodes: ["192.168.31.61", "192.168.31.62", "192.168.31.63"]3.1.3 配置jdk
1,因为elasticsearch是java写的,所以需要java环境。
2,可以自己手动在机器上面安装java。但是会造成这台机器上面的java环境固定。或者会对以前的java版本产生改变。
3,所以elasticsearch 7以上版本会自带jdk,所以我们只需要告诉elasticsearch使用自带的jdk即可。
其实主要控制es用不用自带java的 变量就俩 ES_JAVA_HOME JAVA_HOME
cd /opt/elasticsearch-7.12.1/bin
vim elasticsearch-env
...
ES_HOME=`dirname "$SCRIPT"`
# now make ES_HOME absolute
ES_HOME=`cd "$ES_HOME"; pwd`
while [ "`basename "$ES_HOME"`" != "bin" ]; do
ES_HOME=`dirname "$ES_HOME"`
done
ES_HOME=`dirname "$ES_HOME"`
ES_JAVA_HOME=/opt/elasticsearch-7.12.1/jdk # 我只是添加了一个ES_JAVA_HOME变量,下面的if判断会判断这个变量。
# now set the classpath
ES_CLASSPATH="$ES_HOME/lib/*"
# now set the path to java
if [ ! -z "$ES_JAVA_HOME" ]; then # 会判断这个变量是否为空 !不为空 走下面的代码
JAVA="$ES_JAVA_HOME/bin/java" # 这样java环境就有了
JAVA_TYPE="ES_JAVA_HOME"
elif [ ! -z "$JAVA_HOME" ]; then
# fallback to JAVA_HOME
echo "warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME" >&2
JAVA="$JAVA_HOME/bin/java"
JAVA_TYPE="JAVA_HOME"
else
# use the bundled JDK (default)
if [ "$(uname -s)" = "Darwin" ]; then
# macOS has a different structure
JAVA="$ES_HOME/jdk.app/Contents/Home/bin/java"
else
JAVA="$ES_HOME/jdk/bin/java"
fi
JAVA_TYPE="bundled JDK"
fi
...3.1.4 启动es
elasticsearch 7以后的版本都自带启动脚本,只需要执行一下就行
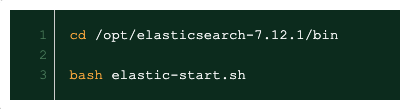
3.1.5 检查es集群
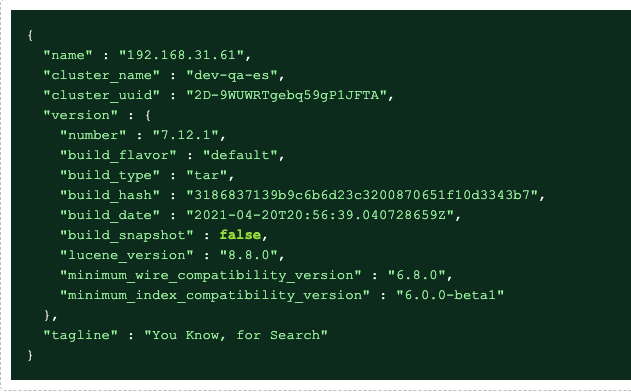
访问三个节点的其中一个的 9200端口 :http://192.168.31.61:9200/
查看一些接口:http://192.168.31.61:9200/_cat
查看index:http://192.168.31.61:9200/_cat/indices
3.2 部署cerebro
cerebro是一个es的监控工具,类似于es的插件一样。可以同时监控多个集群。
cd /opt/
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.zip
unzip cerebro-0.9.4.zip
cd cerebro-0.9.4vim conf/application.confhosts = [
{
host = "http://192.168.31.61:9200" # es地址
name = "dev-qa-es" # 集群名称
headers-whitelist = [ "x-proxy-user", "x-proxy-roles", "X-Forwarded-For" ]
}
]启动cd binnohup ./cerebro 2>&1 &3.2.1 访问
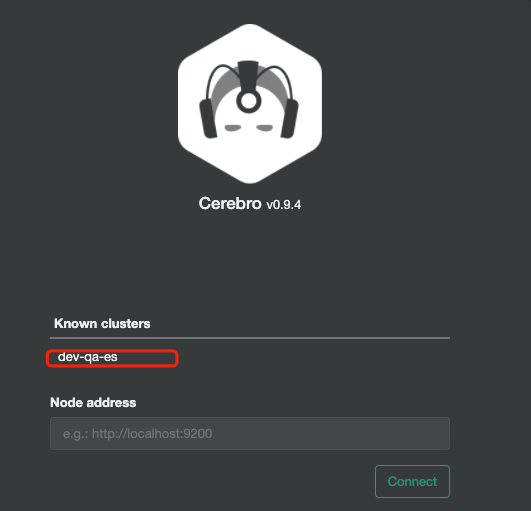
可以看到es集群的一些常用的信息
http://192.168.31.61:9000

3.3 Kibana
3.3.1 下载
cd /opt/
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-linux-x86_64.tar.gz3.3.2 配置
cd /opt/
tar xf kibana-7.12.1-linux-x86_64.tar.gz
配置
cd /opt/kibana-7.12.1
vim config/kibana.yml
server.port: 5601 # 监听端口
server.host: "192.168.31.61" # 监听地址
elasticsearch.hosts: ["http://192.168.31.61:9200", "http://192.168.31.62:9200", "http://192.168.31.63:9200"] # es hosts
i18n.locale: "zh-CN"3.3.3 启动&访问
cd /opt/kibana-7.12.1-linux-x86_64/bin
nohup su - kibana -c "/opt/kibana-7.12.1-linux-x86_64/bin/kibana" & # 前提是需要新建好kibana用户访问:http://192.168.31.61:5601
3.4 部署filebeat
3.4.1 下载
cd /opt/
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.12.1-linux-x86_64.tar.gz
tar xf filebeat-7.12.1-linux-x86_64.tar.gz3.4.2 目录规划
/data/service-logs/{dev,qa}/$appname/{nginx,storage/{logs,autoLogs/sysError}}
$env=qa,dev
$appname=php所有的服务名称
/data/service-logs/${env}/${appname}/{nginx,storage/{logs,autoLogs/sysError/}}
例如:wxx 服务的dev环境宿主机目录结构
/data/service-logs/dev/wxx/nginx/ 这个下面有access error日志
/data/service-logs/dev/wxx/storage/logs/ php info日志
/data/service-logs/dev/wxx/storage/autoLogs/sysError/ php error日志
3.4.3 服务日志挂载到宿主机
1,更改php服务容器的yaml文件的volumeMounts
比如这个dev环境的wxx服务
volumeMounts:
- mountPath: /var/log/nginx
name: pod-nginx-log
- mountPath: /var/www/html/storage/logs
name: pod-storage-logs
- mountPath: /var/www/html/storage/autoLogs/sysError
name: pod-storage-autologs
volumes:
- hostPath:
path: /data/service-logs/dev/wxx/nginx
type: ""
name: pod-nginx-log
- hostPath:
path: /data/service-logs/dev/wxx/storage/logs
type: ""
name: pod-storage-logs
- hostPath:
path: /data/service-logs/dev/wxx/storage/autoLogs/sysError
type: ""
name: pod-storage-autologs3.4.4 nginx json格式输出
更改nginx.conf
加入json格式定义
log_format access_json_log escape=json '{"@timestamp":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"body_bytes_sent":"$body_bytes_sent",'
'"request_time":"$request_time",'
'"http_host":"$http_host",'
'"request_length":"$request_length",'
'"upstream_response_length":"$upstream_response_length",'
'"upstream_response_time":"$upstream_response_time",'
'"request_body":"$request_body",'
'"upstream_status":"$upstream_status",'
'"status":"$status",'
'"request":"$request",'
'"request_method":"$request_method",'
'"http_referrer":"$http_referrer",'
'"http_x_forwarded_for":"$http_x_forwarded_for",'
'"http_user_agent":"$http_user_agent"}';
access_log /var/log/nginx/access.log access_json_log;3.4.5 php info日志提取匹配
原始日志:其实就是filebeat支持正则表达式,只要你能匹配出你想要的日志内容就行

我们提取[2021-07-05 13:00:00] 到下一个[2021-07-05 13:01:00] 中间的内容
所以匹配就可以写成,
multiline.pattern: '^[' # 其实就是以[开头的行
multiline.negate: true
multiline.match: aftermultiline.negate: truemultiline.match: after这俩就是控制满足匹配之前的还是之后的,官方文档:https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
3.4.5 php error日志提取匹配
原始日志:

我们提取2021-07-05 15:00:00 到下一个 2021-07-05 15:01:00
multiline.pattern: '^[0-9]{4}-[0-9]{2}-' # 以日期开头
multiline.negate: true
multiline.match: after总结:各种不同的日志 可以用不同的正则表达式去匹配出来。
3.4.6 我的filebeat配置
cd /opt/k8s/efk/filebeat-7.12.1-linux-x86_64/
服务太多我只展示了一个服务的配置。其他的都是一样的
vim filebeat.yml
filebeat.inputs:
#########################################################################
#### 日志收集 ####
# 一个项目为一个#组,一个组里有4个收集规则
# collectLogStart
############################## operation-api ##############################
- type: log
enabled: true # 启用输入
encoding: utf-8 # 字符编码
paths:
- /data/service-logs/dev/operation-api/nginx/access.log # 日志路径
tail_files: true # true 从文件的末尾读取,false 从开头读取文件
json.keys_under_root: true # json解码
json.overwrite_keys: true # json解码
fields: # 额外增加字段
app_env: "dev"
app_name: "operation-api"
log_topics: "nginx-access"
fields_under_root: true # 增加的字段是否为顶级key
- type: log
enabled: true
encoding: utf-8
paths:
- /data/service-logs/dev/operation-api/nginx/error.log
tail_files: true
fields:
app_env: "dev"
app_name: "operation-api"
log_topics: "nginx-error"
fields_under_root: true
- type: log
enabled: true
encoding: utf-8
paths:
- /data/service-logs/dev/operation-api/storage/logs/lumen*.log
multiline.pattern: '^['
multiline.negate: true
multiline.match: after
tail_files: true
fields:
app_env: "dev"
app_name: "operation-api"
log_topics: "php-logs"
fields_under_root: true
- type: log
enabled: true
encoding: utf-8
paths:
- /data/service-logs/dev/operation-api/storage/autoLogs/sysError/lumen*.log
multiline.pattern: '^[0-9]{4}-[0-9]{2}-'
multiline.negate: true
multiline.match: after
tail_files: true
fields:
app_env: "dev"
app_name: "operation-api"
log_topics: "php-errlogs"
fields_under_root: true
############################## operation-api ##############################
# collectLogEnd
################################### 日志收集配置 ########################
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
# 自定义index
setup.template.name: "zm-log"
setup.template.pattern: "zm-log-*"
setup.template.overwrite: true
setup.template.enabled: true
setup.ilm.enabled: false # 这个配置至关重要,是关于ilm生命周期。可以查看官方文档。这个是关闭自带的,然后使用自定义的。
output.elasticsearch:
hosts: ["192.168.31.61:9200","192.168.31.62:9200","192.168.31.63:9200"]
loadbalance: true # 开启负载
pipelines: # 有关filebeat使用pipeline 我后期单独写一篇文章:https://www.cnblogs.com/fanfanfanlichun/p/14977166.html
- pipeline: "extract-traceid-pipeline"
when.contains:
log_topics: "php-errlogs"
indices: # index的配置,这个配置就是说当app_env=qa的时候用index: "zm-log-qa-%{+yyyy.MM.dd-000001}"
- index: "zm-log-qa-%{+yyyy.MM.dd-000001}"
when.contains:
app_env: "qa"
- index: "zm-log-dev-%{+yyyy.MM.dd}-000001"
when.contains:
app_env: "dev"
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
- drop_fields: # 这个是丢弃哪些key
fields: ["host.mac","host.ip","host.os.name"]3.4.7 启动
nohup /opt/k8s/efk/filebeat-7.12.1-linux-x86_64/filebeat -e -c /opt/k8s/efk/filebeat-7.12.1-linux-x86_64/filebeat.yml >/dev/null 2>&1 &3.5 访问kibana
http://192.168.31.61:5601
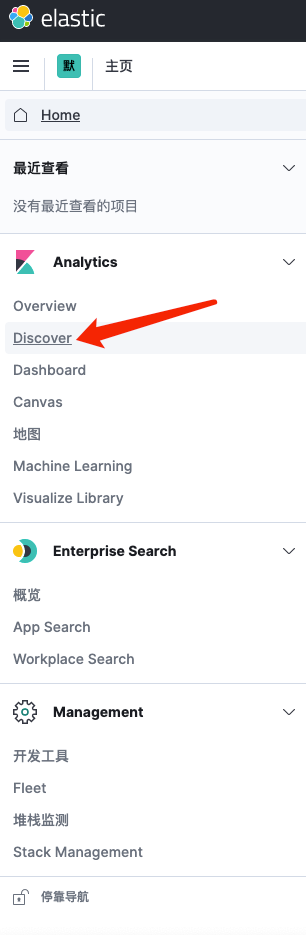

3.5.1 字段解释
app_name:服务名称
log_topics:nginx-access nginx-error php-info php-error
四、总结
1,其实我这个是按照我这边的业务场景配置的,希望对你有益。
2,官方文档才是最好的。
3,有问题留言,我会及时回复。
共同成长。共同进步。