分布式系统如果保证接口的幂等性?
- 数据设置状态值
- 数据库设置唯一性
- 每个数据请求有唯一性标识
分布式session如何处理?
- tomcat+redis,TomcatRedisSessionManager,将所有部署的tomcat都将session存储到redis即可。使用方法不变,是Tomcat封装的类将session存储到了redis,依赖web容器
- spring session +redis:spring 将session存储到redis
分库分表
- 为什么要分库分表?表数据量达到上千万级别,数据库磁盘消耗高,QPS响应慢,需要通过分库分表来优化
- 分库分表中间件?中间件有client类型,proxy类型


什么是垂直分和水平分?

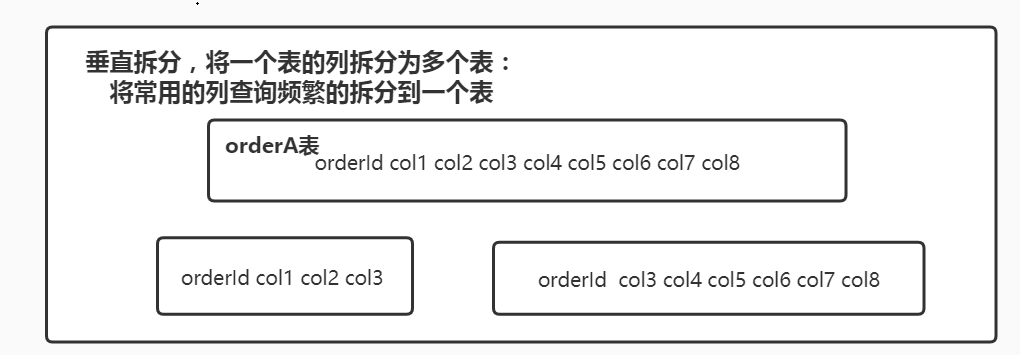
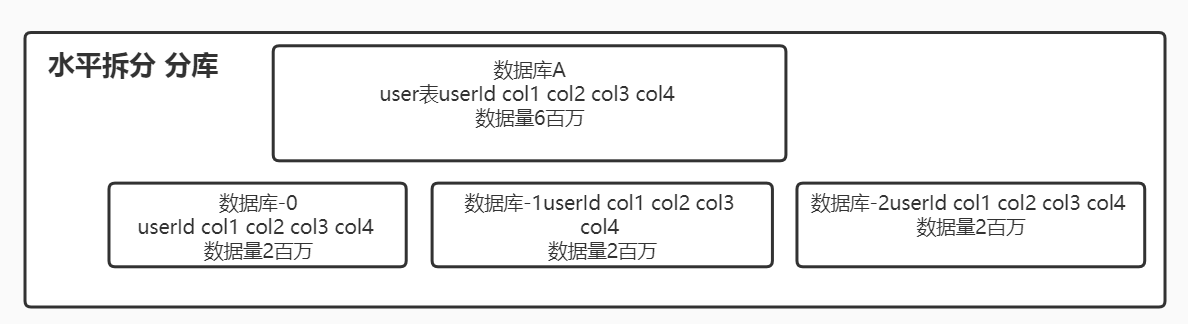

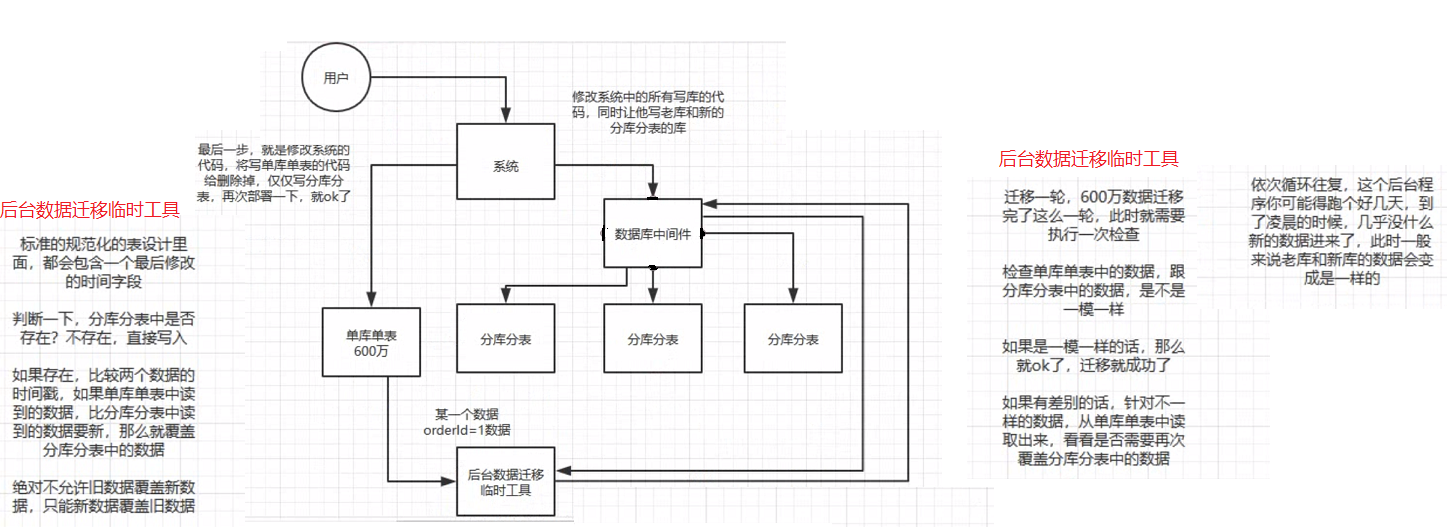
如何平滑的执行分库分表?
- 启动多个线程读取原始数据到数据中间件中
- 双写迁移方案:
-
分库分表之后全局唯一ID如何生成(主键自增ID)?
- 全局表:生成主键ID的全局数据库A,每次都去数据库A里面得到主键ID,然后再去其他数据库insert 数据。瓶颈:单库,适用于 并发量小,数据大的情况,每秒最高并发最大为几百的合适。
- uuid :本地生成,不基于数据库,存储空间大,字段太长,做为主键性能差
- 利用redis的incr原子性操作自增
- MySQL多实例主键自增 :优点:解决了单点问题,缺点:确定了步长 无法再次扩容
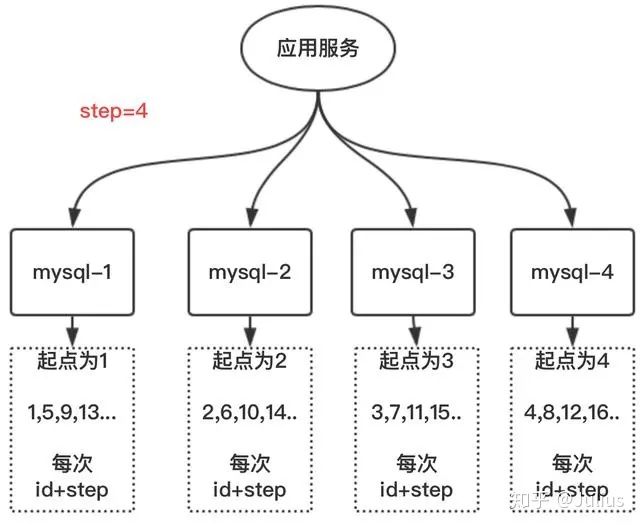
5.雪花算法(snowflake) :整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。缺点:强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
什么是读写分离?为什么要有读写分离?
数据库一般 请求 2000/s,大于该请求就会出现磁盘高,性能瓶颈。大部分是读大于写,针对这个问题可以通过一个 主库挂多个从库,从库读数据,支持更高的并发
如何实现读写分离?
住库将变更写到binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己的relay log中,从库的SQL线程从relay log中读取binlog,然后执行binlog日志中的内容,在自己本地在执行一遍SQL,这样就完成了从库和主库的数据是一样的。
Mysql主从复制原理?
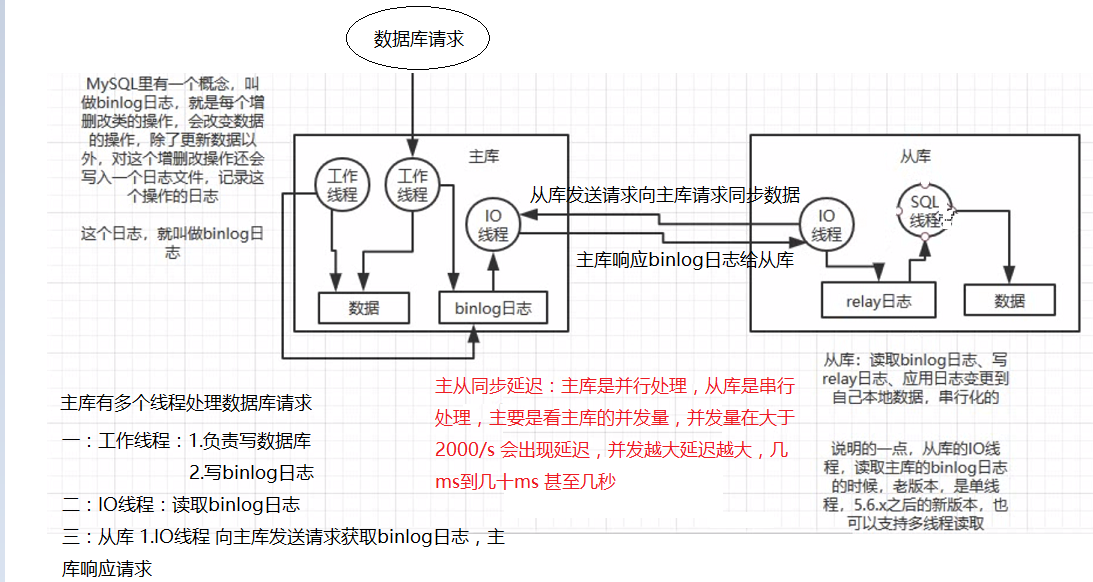
1. 主库对所有DDL和DML产生的日志写进binlog;
2. 主库生成一个 log dump 线程,用来给从库I/O线程读取binlog;
3. 从库的I/O Thread去请求主库的binlog,并将得到的binlog日志写到relay log文件中;
4. 从库的SQL Thread会读取relay log文件中的日志解析成具体操作,将主库的DDL和DML操作事件重放。
关于DDL和DML
SQL语言共分为四大类:查询语言DQL,控制语言DCL,操纵语言DML,定义语言DDL。
DQL:可以简单理解为SELECT语句;
DCL:GRANT、ROLLBACK和COMMIT一类语句;
DML:可以理解为CREATE一类的语句;
DDL:INSERT、UPDATE和DELETE语句都是;
Mysql主从同步的延时问题?
现象:从库同步主库数据的过程是串行化的,主库是并行的操作,在从库上会串行(顺序)执行。由于从库从主库拷贝日志然后串行执行SQL的特点,在高并发场景下,从库的数据一定会比主库慢一些,有延时,写入的主库数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
1.MySQL的主从复制都是单线程的操作,主库对所有DDL和DML产生的日志写进binlog,由于binlog是顺序写,所以效率很高。Slave的SQL Thread线程将主库的DDL和DML操作事件在slave中重放。DML和DDL的IO操作是随即的,不是顺序的,成本高很多。
2.由于SQL Thread也是单线程的,当主库的并发较高时,产生的DML数量超过slave的SQL Thread所能处理的速度,或者当slave中有大型query语句产生了锁等待那么延时就产生了。
常见原因:Master负载过高、Slave负载过高、网络延迟、机器性能太低、MySQL配置不合理。
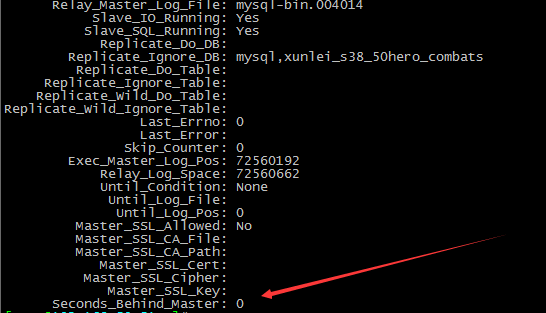
主从延迟排查方法?
通过监控 show slave status 命令输出的Seconds_Behind_Master参数的值来判断:
NULL:表示io_thread或是sql_thread有任何一个发生故障;
0:该值为零,表示主从复制良好;
正值:表示主从已经出现延时,数字越大表示从库延迟越严重。
解决从库复制延迟的问题?
1. 优化网络
2. 升级Slave硬件配置
3. Slave调整参数,关闭binlog,修改innodb_flush_log_at_trx_commit参数值
4. 升级MySQL版本到5.7,使用并行复制:从库开启多个线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这就是库级别(基于库的)的并行
主库突然宕机日志没有写到binlog(数据丢失问题)?
主库突然宕机日志没有写到binlog,那么主库就丢失了这条数据如何解决?
半同步复制(semi-sync复制):主库写入binlog日志之后,强制立即将数据同步到从库,从库将日志写入本地的relay log之后,返回一个ack给主库,主库收到从库ack请求(需要等待至少一个从库接收到并写到relay log中才返回结果给客户端),才认为是写操作完成了。 半同步复制提高了数据的安全性,同时它也造成了一个TCP/IP往返耗时的延迟。(所以写库失败,需要重试解决丢失数据问题)
relay-log(中继日志)
存储所有主库TP过来的binlog事件主库binlog,记录主库发生过的修改事件。