1.各数据类型及其字节数
BYTE 1; char 1; short 2; int 4; double 8;
2.位序big和little及其转换
对于位序是big的数据我们在读取时要小心。通常,数据的位序都是Little,但在有些情况下可能会是big,二者的区别在于它们位序的顺序相反。一个位序为big的数据,如果我们想得到它的真实数值,需要将它的位序转换成Little即可。转换原理就是交换字节顺序,下面是转换代码(big->little):
int OnChangeByteOrder(int indata)
{
char ss[9];
char ee[8];
unsigned long val = unsigned long(indata);
ultoa(val, ss, 16);// 将十六进制的数(val)转到一个字符串(ss)中,itoa(val,ss,16);
int i;
int length = strlen(ss);
if (length != 8){
for (i = 0; i<8 - length; i++)
ee[i] = '0';
for (i = 0; i<length; i++)
ee[i + 8 - length] = ss[i];
for (i = 0; i<8; i++)
ss[i] = ee[i];
}
//****** 进行倒序
int t;
t = ss[0]; ss[0] = ss[6]; ss[6] = t;
t = ss[1]; ss[1] = ss[7]; ss[7] = t;
t = ss[2]; ss[2] = ss[4]; ss[4] = t;
t = ss[3]; ss[3] = ss[5]; ss[5] = t;
//****** 将存有十六进制数 (val) 的字符串 (ss) 中的十六进制数转成十进制数
int value = 0;
for (i = 0; i<8; i++){
int k;
if (ss[i] == 'a' || ss[i] == 'b' || ss[i] == 'c' || ss[i] == 'd' || ss[i] == 'e' || ss[i] == 'f')
k = 10 + ss[i] - 'a';
else
k = ss[i] - '0';
value = value + int(k*(int)pow((DOUBLE)16, 7 - i));
}
return(value);
}
3.shp文件的基本构成
shp文件,由于包含最主要的数据坐标数据,也叫主文件、坐标文件,由文件头和实体信息构成
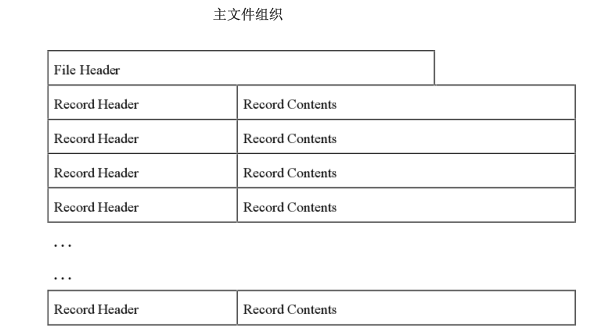
文件头是关于主文件的基本描述,包括版本号、文件长度等信息;实体信息是每一个图形的具体信息,也包括记录头和坐标内容。
4.shp头文件
头文件的结构如下,下面两表含义相同。
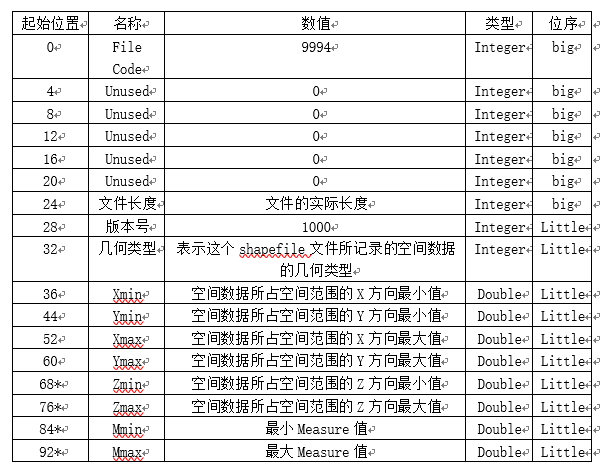

有值得说明的几点:
- 前9项都是int类型,位序是big;后8项都是double类型,位序是little,所以头文件的大小为 9 * 4 + 8 * 8 = 100。
- FileCode固定为9994,Version固定为1000。
- FileLength是指总文件长度,大小为 头文件长度 + (记录头长度 + 记录内容长度) * 记录数
- ShapeType为该shp文件图形的类型(1代表Point,3代表Polyline,5代表Polygon),更多的类型参考说明文件,目前每个 shape 文件被限定为只能包含上述类型的一种。
- Xmin,Ymin,Xmax,Ymax是空间范围的边界。
- Zmin,Zmax,Mmin,Mmxa一般用不到。
5.shp实体信息
shp实体信息分为记录头和记录内容。
5.1记录头

- RecordNumber代表当前记录的编号。每个记录的记录头都储存着记录号(Record Number)和记录内容长度(Content Length),位序都是big,类型是int,记录头的长度是 8 个字节,记录号从 1 开始。
- ContentLength代表当前记录内容的长度,不包括RecordNumber和ContentLength本身的长度,下面将以面状要素为例计算ContentLength的大小。
5.2记录内容
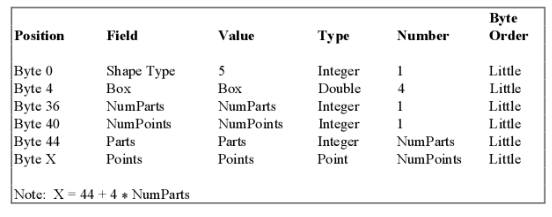
- ShapeType是指多边形的类型,Polygon是5。
- Box是double类型的数组,包含多边形的4个边界。
- NumParts代表Polygon的子环数,一个Polygon可能由多个环。
- Parts是一个int类型数组,数组元素个数等于NumParts,每个元素记录了每个子环的坐标在Points数组中的起始位置。
- Points记录Polygon的所有点,是Point类型,Point类型包含2个double类型(x,y均为double)。
不同的要素类型的记录内容不一样,本次以面状要素为例(Polygon,ShapeType为5),面状要素的记录内容如下:
所以一条记录(Polygon)的ContentLength(字节数)大小为:
4 + 4 * 8 + 4 + 4 + NumParts * 4 + NumPoints * 2 * 8 ,不包括RecordNumber和ContentLength本身的长度,ContentLength实际值为字节数的一半,后面FileLength也是字节数的一半。所以ContentLength = ContentLength/2。
6.shp读取的C++函数代码:
void readShp(void)
{
//****打开坐标文件
CFileDialog fDLG(true);
if (fDLG.DoModal() != IDOK)
return;
filename = fDLG.GetPathName();
FILE* m_ShpFile_fp = fopen(filename, "rb");
if (m_ShpFile_fp == NULL) {
MessageBox("Open File Failed");
exit(0);
}
CGeoMap* map = new CGeoMap(); //创建地图对象
CGeoLayer* layer = new CGeoLayer();//新建图层
//****定义读取坐标文件头的变量
int i;
int FileCode = -1;
int Unused = -1;
int FileLength = -1;
int Version = -1;
int ShapeType = -1;
double Xmin;
double Ymin;
double Xmax;
double Ymax;
double Zmin;
double Zmax;
double Mmin;
double Mmax;
//****读取坐标头文件
fread(&FileCode, sizeof(int), 1, m_ShpFile_fp); //从m_ShpFile_fp里面的值读到Filecode里面去,每次读一个int型字节的长度,读取一次
FileCode = OnChangeByteOrder(FileCode); //将读取的FileCode的值转化为十进制的数
for (i = 0; i<5; i++)
fread(&Unused, sizeof(int), 1, m_ShpFile_fp);
fread(&FileLength, sizeof(int), 1, m_ShpFile_fp);//读取FileLength
FileLength = OnChangeByteOrder(FileLength); //将FileLength转化为十进制的数
fread(&Version, sizeof(int), 1, m_ShpFile_fp); //读取Version的值
fread(&ShapeType, sizeof(int), 1, m_ShpFile_fp);//读取ShapeType的值
fread(&Xmin, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Xmin里面去,每次读取一个double型字节长度,读取一次
fread(&Ymin, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Ymin里面去,每次读取一个double型字节长度,读取一次
fread(&Xmax, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Xmax里面去,每次读取一个double型字节长度,读取一次
fread(&Ymax, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Ymax里面去,每次读取一个double型字节长度,读取一次
CRect rect(Xmin, Ymin, Xmax, Ymax);
layer->setRect(rect); //设置图层的边界
fread(&Zmin, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Zmin里面去,每次读取一个double型字节长度,读取一次
fread(&Zmax, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Zmax里面去,每次读取一个double型字节长度,读取一次
fread(&Mmin, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Mmin里面去,每次读取一个double型字节长度,读取一次
fread(&Mmax, sizeof(double), 1, m_ShpFile_fp);//从m_ShpFile_fp里面的值读到Mmax里面去,每次读取一个double型字节长度,读取一次
//****读取坐标文件头的内容结束
//****读取面状目标的实体信息
int RecordNumber;
int ContentLength;
switch (ShapeType) {
case 5: { //polygon
while ((fread(&RecordNumber, sizeof(int), 1, m_ShpFile_fp) != 0)) { //从第一个开始循环读取每一个Polygon
fread(&ContentLength, sizeof(int), 1, m_ShpFile_fp); //读取ContentLength
RecordNumber = OnChangeByteOrder(RecordNumber); //转换为10进制
ContentLength = OnChangeByteOrder(ContentLength);
//****记录头读取结束
//****读取记录内容
int shapeType; //当前Polygon几何类型
double Box[4]; //当前Polygon的上下左右边界
int NumParts; //当前Polygon所包含的子环的个数
int NumPoints; //当前Polygon所包含的点的个数
int *Parts; //当前Polygon所包含的子环的起点在NumPoints的编号
fread(&shapeType, sizeof(int), 1, m_ShpFile_fp);
for (i = 0; i < 4; i++) //读Box
fread(Box + i, sizeof(double), 1, m_ShpFile_fp);
fread(&NumParts, sizeof(int), 1, m_ShpFile_fp); //表示构成当前Polygon的子环的个数
fread(&NumPoints, sizeof(int), 1, m_ShpFile_fp);//表示构成当前Polygon所包含的坐标点个数
Parts = new int[NumParts]; //记录了每个子环的坐标在Points数组中的起始位置
for (i = 0; i < NumParts; i++)
fread(Parts + i, sizeof(int), 1, m_ShpFile_fp);
int pointNum;
CGeoPolygon* polygon = new CGeoPolygon();
polygon->circleNum = NumParts; //设定多边形的点数
//****读取面中子环
for (i = 0; i < NumParts; i++) {
if (i != NumParts - 1) pointNum = Parts[i + 1] - Parts[i];//每个子环的长度 ,非最后一个环
else pointNum = NumPoints - Parts[i]; //最后一个环
double* PointsX = new double[pointNum]; //用于存放读取的点坐标x值;
double* PointsY = new double[pointNum]; //用于存放y值
CGeoPolyline* polyline = new CGeoPolyline(); //每个环实际上就是首尾坐标相同的Polyline
polyline->circleID = i;
for (int j = 0; j < pointNum; j++) {
fread(PointsX + j, sizeof(double), 1, m_ShpFile_fp);
fread(PointsY + j, sizeof(double), 1, m_ShpFile_fp);
double a = PointsX[j];
double b = PointsY[j];
CPoint* point = new CPoint(a, b);
polyline->AddPoint(point); //把该子环所有的点添加到一条链上
}
CPoint pt1 = polyline->pts[0]->GetCPoint();
CPoint pt2 = polyline->pts[polyline->pts.size() - 1]->GetCPoint();
if (pt1 != pt2) { //若首位点不一致
CString str;
str.Format("%d数据首尾点不一致", RecordNumber);
polyline->pts.push_back(p1);
}
polygon->AddCircle(polyline); //将polyline链添加到对应polygon中
delete[] PointsX;
delete[] PointsY;
}
//****一个面的某个子环循环结束,同时该子环已加入到polygon
layer->AddObject((CGeoObject*)polygon); //将该polygon加入到图层中
delete[] Parts;
}
map->AddLayer(layer);
}
break;
case 1://point
break;
case 3://polyline
break;
default:
break;
}
}
下一篇博客介绍dbf文件的读取。