今天收到一个任务,用 python 爬取招聘网站信息。招聘网址是这个:https://job.toutiao.com/s/JNcJSRo。打开之后自动跳转到了这里:https://job.bytedance.com/referral/pc/position?token=MzsxNTk0NDQzMDMxOTkzOzY3NzE1NjI2MDc2ODMyNTc4Njk7MA。
常规操作,先审查元素。每一个职位的 title 和职位描述是相同的 class,如果可以得到页面静态内容,就可以把招聘信息保存下来了。

import requests url = "https://job.bytedance.com/referral/pc/position?token=MzsxNTk0NDQzMDMxOTkzOzY3NzE1NjI2MDc2ODMyNTc4Njk7MA" headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'} resp = requests.get(url,headers=headers) print(resp.text)
打印的文本没有发现什么有用信息,很明显,这里的数据都是另外通过 POST 请求获取的。监听一下网络请求,发现了数据来源。
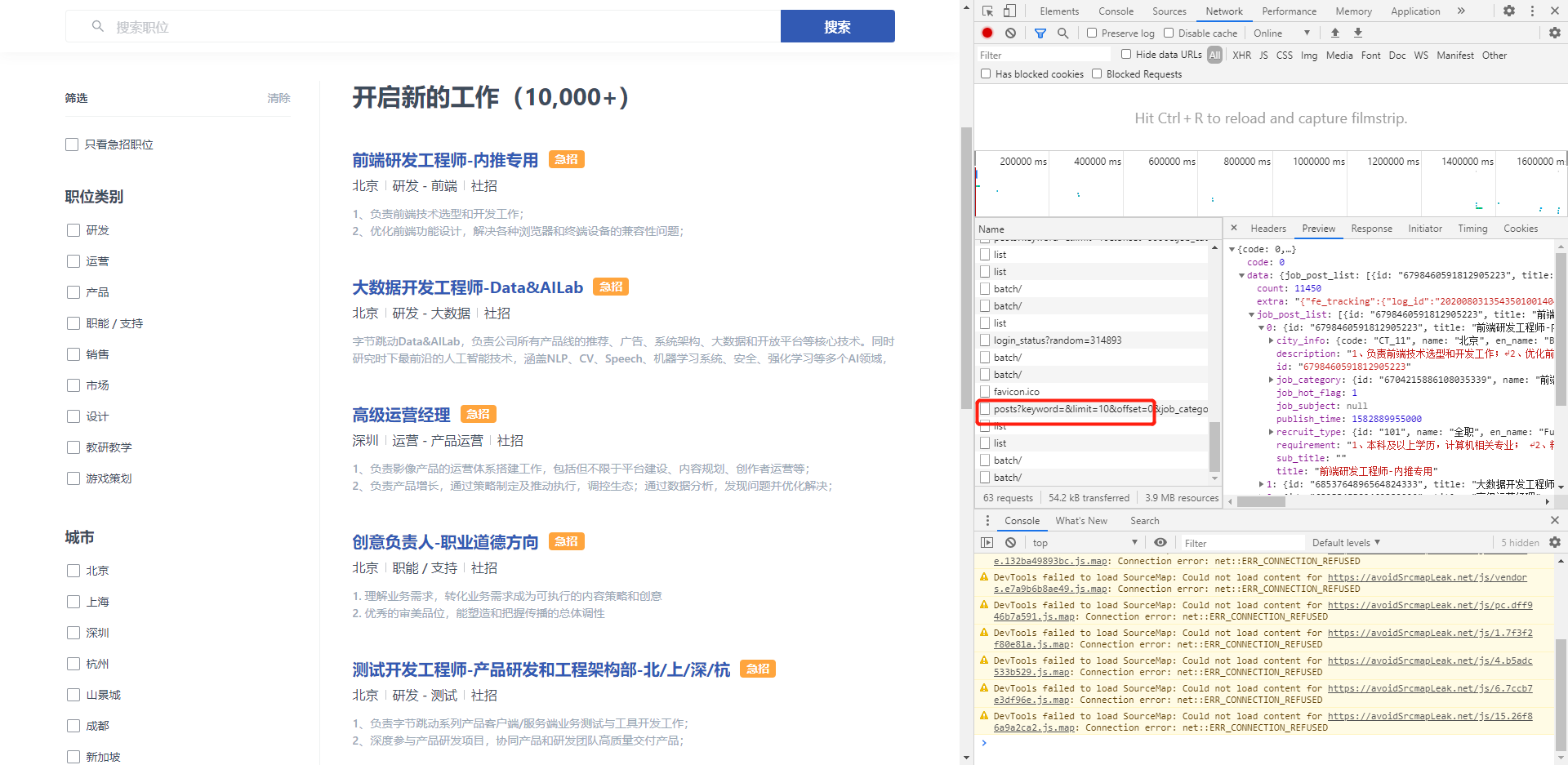
既然可以完整的看到需要的数据,模拟一个一样的请求不就可以了吗。分析后调整代码。
1 import requests 2 import json 3 4 def getJobData(): 5 url = "https://job.bytedance.com/api/v1/search/job/posts?keyword=&limit=10&offset=0&job_category_id_list=&location_code_list=&subject_id_list=&recruitment_id_list=&portal_type=1&portal_entrance=1&_signature=7ZAzMgAgEAgBrEgAxo1ege2QMyAALLC" 6 headers = { 7 'accept':'application/json, text/plain, */*', 8 'accept-encoding':'gzip, deflate, br', 9 'accept-language':'zh-CN', 10 'content-type':'application/json', 11 'cookie':'referral-token=MzsxNTk0NDQzMDMxOTkzOzY3NzE1NjI2MDc2ODMyNTc4Njk7MA; channel=referral; platform=pc; s_v_web_id=kddyb7ab_IRgnUvNC_fthm_45Io_9aFj_nBUcCkZP3U3c; device-id=6856593760391792135; TS01ab245c=015df6ccf27d7fed70cc0134a66cf6caed02d10578dff54bbbb38f2bec5d8d76af64ca121c34e7472fe6ab288bce53c5044a27abf2; SLARDAR_WEB_ID=bb0ff545-72f9-440a-9574-4ea5ae7bb74e; TS0170d300=015df6ccf28055e45208edcc51b025a5ed540a12f025e46e1d8699ecb874d4d16d0dfa4aefe40f75beea5c836bda606eb3839ed21b; atsx-csrf-token=9xQgHaOg5kY17BZGoxQXuM0_B9rT9S17F4ya-z6hxD4%3D', 12 'env':'undefined', 13 'origin':'https://job.bytedance.com', 14 'portal-channel':'referral', 15 'portal-platform':'pc', 16 'referer':'https://job.bytedance.com/referral/pc/position?token=MzsxNTk0NDQzMDMxOTkzOzY3NzE1NjI2MDc2ODMyNTc4Njk7MA', 17 'sec-fetch-dest':'empty', 18 'sec-fetch-mode':'cors', 19 'sec-fetch-site':'same-origin', 20 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36', 21 'website-path':'referral', 22 'x-csrf-token':'9xQgHaOg5kY17BZGoxQXuM0_B9rT9S17F4ya-z6hxD4=' 23 } 24 data={ 25 'keyword':'', 26 'limit':10000, 27 'offset':0, 28 'job_category_id_list':[], 29 'location_code_list':[], 30 'subject_id_list':[], 31 'recruitment_id_list':[], 32 'portal_type':1, 33 'portal_entrance':1, 34 '_signature':'7ZAzMgAgEAgBrEgAxo1ege2QMyAALLC' 35 } 36 param = json.dumps(data) 37 resp = requests.post(url=url,data=param,headers=headers) 38 # 知道为啥打印这个 status 吗? 39 print(resp.status_code) 40 job_data = resp.json() 41 job_list = job_data["data"]["job_post_list"] 42 return job_list 43 44 def saveFile(): 45 fi = open('job.bytedance.data.txt','r+',encoding='utf-8') 46 jobs = getJobData() 47 print("共有职位:" + str(len(jobs)) + " 个") 48 for i in range(len(jobs)): 49 city = jobs[i]["city_info"]["name"] 50 title = jobs[i]["title"] 51 desc = jobs[i]["description"] 52 requirement = jobs[i]["requirement"] 53 fi.write(city + "-" + title + " 【职位描述】 " + desc + " 【职位要求】 " + requirement + " ") 54 55 saveFile()
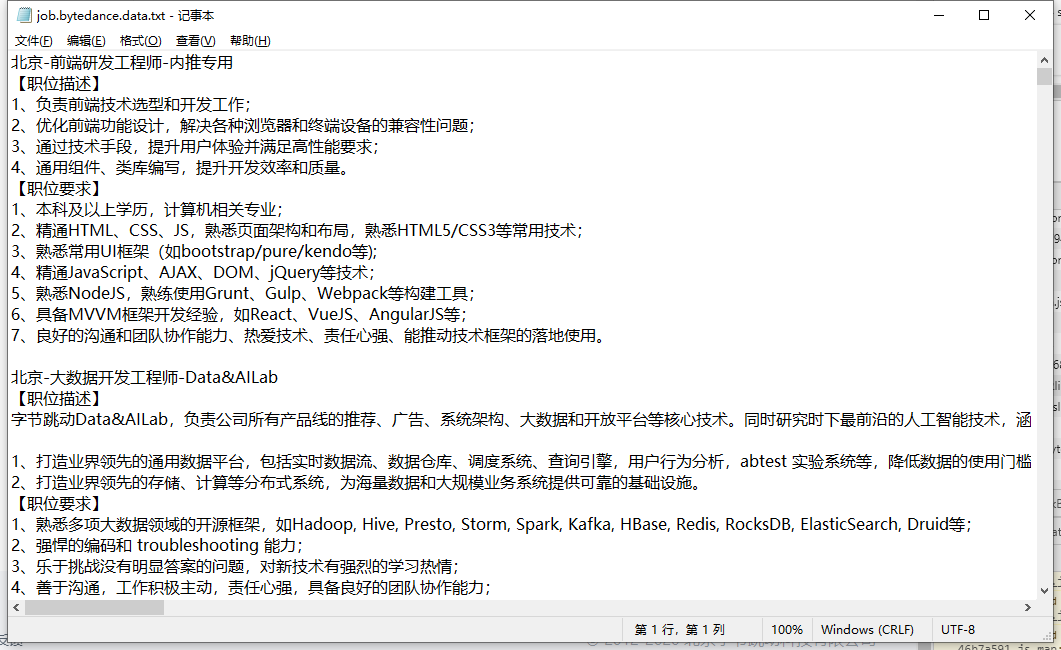
保存下来的文件有10.5Mb,网页上有1000个分页,每页10条信息,所以直接将请求参数 limit 改成了10000。
10000个职位,我的天!
然而没有一个职位属于我。
?
??
???
继续失业吧。
