年初转组,接触了一些新业务.
交接了一个数据统计系统,去年下半年开发完成,不再有新的需求.
emmmm,妥妥的一个遗留系统... ...
有对应文档但比较老,一些存储和细节记录在了原开发自己的笔记中.
最主要是bug累累,之前使用量和用户较少没有多少bug反馈,但随着今年用户增加基本每个月都会有一些bug.
该系统的简单架构如下:
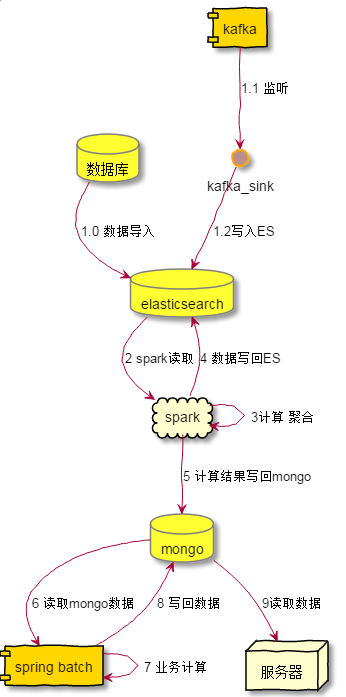
由一位同事单独完成,历时几个月,难以想象他经历了什么...但听闻他在开发过程中几乎崩溃了,自己完成了数据的获取,处理,聚合.
ES和spark的资源还是借用了其他组已经搭好的存储.
我们有专门的数据团队产出一些业务指标,但这位同事做这套系统的时候那边提供的帮助有限,差不是是无法获得数据源(日志)由他们提供,但如果数据库或其他存储里有数据源自己处理.
介于该系统的诸多问题,数据团队那边已经决定改为所需的指标都由他们提供,我们做一下对接的方式,现在正在进行中.
该文就来提一下我接手之后遇到的坑,以及一些处理方式.
遇到的问题
数据指标定义有误
这是一个非常尴尬的问题,维护一个系统最沮丧的莫过于,你发现他一开始做的就是错的.
数据系统产出的有趋势数据和汇总数据,趋势数据也就是每天的数据,而之前实现的时候汇总数据是趋势数据的累加.
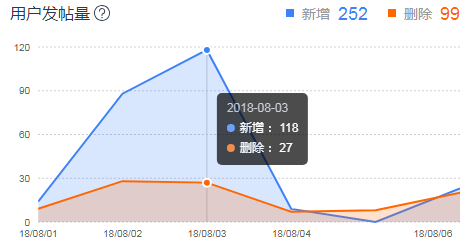
但现实场景下一些指标是无法累加的.
例如上述场景下帖子的删除是可恢复的,今天删除恢复后明天又进行了删除,趋势数据里表示的是两天删除数都是1,
累加是2,但看这两天的汇总数据实际上就删除了1次,但还是会显示2,这时候用户就会疑惑自己的帖子明明就少了一个但为什么这周期汇总的数据是2呢.
当然这里也可以提示用户是删除这个行为发生了2次,但显然在这个指标下汇总数据上用户更关注是结果.
其他的诸如被回帖的帖子数,同一个帖子被两天都被回复和这两天的汇总量之间是不能简单相加的.
要去重需要有历史数据支撑,但该系统的计算都是以天为单位,要扩展这个功能需要进行很大的改造.
最后还是放弃了,现在正在接入数据团队的结果.
系统稳定性问题
该系统上线后一直不是很稳定,上图的链路过长,且业务都由之前开发一人维护.
中间任何一环出了问题都会导致数据项的缺失或者数据不准确.
这里总结一些遇到的一些问题和解决办法.
spring batch挂了
这个是接手后最先遇到的,当时还没看到这个系统的全貌,只看到了这冰山一角.
上述的链路的依赖是时间,系统实际运行过程中常常会有spring batch在计算了但上游数据还没准备完的情况.
这种问题比较难发现,往往是某几个账号的数据项不准确了.(趋势数据大幅度掉落等)
但处理方式是比较简单的,定时任务追加了一次,每天跑两次定时任务进行计算.
spark job挂了
遇到过几次,主要是代码问题.
解决方式也就是登录控制台看一下报错log根据错误内容修改代码重新设置任务.
代码bug无法避免,想通过邮件告警的方式进行及时提醒,但对应平台的邮箱配置有问题,询问了几次没有解决最后也搁置了.
ES某个index数据被清空
这个就比较难受了,发现计算一个指标使用的index里的doc少了很多,导致趋势图直接断崖了.
但去检查该index的primary shard又是好的... ... ...
联系存储的运维看了下也没发现什么问题.
当务之急只能先导回数据,还好原始数据存储在了数据库内,最后用logstash导入恢复.
之后没有再出现这个问题.
kafka sink挂了
原开发是找了内网两台空闲的机器起了kafka connector来将数据导入到ES中.
而且这个细节只存在于原开发的笔记中,因为基本没有交接,当时这个出问题的导致数据缺失的时候瞎猫找死耗子弄了好久.
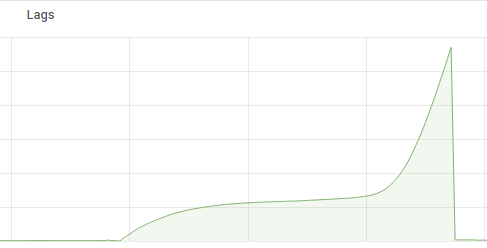
kafka当时已经接入了prometheus,配置了一下报警规则,这一块出现问题可以及时发现.
总结
现在回头想想,或许这套系统就不该做出来... ...
我们有独立的数据团队来做这些,当时因为对方无暇去做这个,整个项目就赶鸭子上架一样由一位开发搭建整个系统和整套流程.
重复了对方重复的工作不说,还做得更糟,数据团队也不免吐槽了这个一番.
其次,这套系统上了之后缺乏关注和维护,他就像鸡肋一样,舍不得丢,也不愿专人维护,就连原开发自己都苦恼不已.最后就这样挂到我头上.
除去吐槽,简单总结一下这套系统不合理之处:
- 以时间作为任务触发的条件.
这个上面也有提到,不管是多个spark任务,spring batch任务,还是整个流程,都是以时间作为任务触发的.
上游任务出现延迟就会出现问题,接手之后的处理是在白天再跑一次,但最开始设计应该用hook更为合适. - 缺少测试环境.
这套系统只有线上,batch可以本地跑,但除此之外没有ES和spark的内网环境,改了直接上线,验证线上数据. - 无法快速验证.
最开始所有的fix都需要跑至少一天的数据才能看出问题(且ES和spark的聚合没办法,一些任务都不带userId).之后在batch中加入了账号参数可以只跑一个账号的数据.
最后自己问题也不少,当初接手这套系统的时候没有了解他大体的结构.
只关注了spring batch和服务器一侧的实现,其他部分是在出现bug时才会去跟进发现.
并且自己掌握的技术能力有限,ES和spark的知识积累不够,现在也还在补这块的内容,自己身上有短板.
整个系统对于一个业务开发来说可以说是一个很好的学习机会了,这样的机会也来之不易.