每一个变量都有数据类型,Go中的数据类型有:
- 简单数据类型:int、float、complex、bool和string
- 数据结构或组合(composite):struct、array、slice、map和channel
- 接口(interface)
当声明变量的时候,会做默认的赋0初始化。每种数据类型的默认赋0初始化的0值不同,例如int类型的0值为数值0,float的0值为0.0,string类型的0值为空"",bool类型的0值为false,数据结构的0值为nil,struct的0值为字段全部赋0。
其实函数也有类型,不过一般称之为返回类型。例如,下面的函数foo的返回类型是int:
func foo() int {
...CODE...
return INT_TYPE_VALUE
}
函数允许有多个返回值,它们使用逗号分隔,括号包围:
func foo() (int,bool)
Number类型
Integer
Integer类型是整型数据,例如3 22 0 1 -3 -22等。
Go中的Integer有以下几种细分的类型:
- int8,int16,int32,int64
- uint8,uint16,uint32,uint64
- byte
- rune
- int,uint
其中8 16 32 64表示该数据类型能存储的bit位数。例如int8表示能存储8位数值,所以这个类型占用1字节,也表示最大能存储的整型数共2^8=256个,所以int8类型允许的最大正数为127,允许的最小负数为-128,共256个数值。
uint中的u表示unsigned,即无符号整数,只保存0和正数。所以uint8能存储256个数的时候,允许的最小值为0,允许的最大值为255。
额外的两种Integer是byte和rune,它们分别等价于uint8(即一个字节大小的正数)、int32。从builtin包中的定义就可以知道:
$ go doc builtin | grep -E "byte|rune"
type byte = uint8
type rune = int32
byte类型后面会详细解释。
还有两种依赖于CPU位数的类型int和uint,它们分别表示一个机器字长。在32位CPU上,一个机器字长为32bit,共4字节,在64位CPU上,一个机器字长为64bit,共8字节。除了int和uint依赖于CPU架构,还有一种uintptr也是依赖于机器字长的。
一般来说,需要使用整型数据的时候,指定int即可,有明确的额外需求时再考虑是否换成其它整数类型。
在整数加上0前缀表示这是8进制,例如077。加上前缀0x表示这是16进制,例如0x0c,使用e符号可以表示这是一个科学计数法,如1e3 = 1000,6.023e23 = 6.023 x 10^23。
可以使用TYPE(N)的方式来生成一个数值,例如a := uint64(5)。实际上这是类型转换,将int类型的5转换成int64类型的5。
byte类型
Go中没有专门提供字符类型char,Go内部的所有字符类型(无论是ASCII字符还是其它多字节字符)都使用整数值保存,所以字符可以存放到byte、int等数据类型变量中。byte类型等价于uint8类型,表示无符号的1字节整数。
Go中的字符都使用单引号包围,例如'a'、'我',但单引号中包含了多个字符是错误的(如'aA'),因为字符类型就是一个字符。
例如,ASCII的字母a表示97。下面这种定义方式是允许的:
var a byte = 'A' // a=65
var b uint8 = 'a' // b=97
注意,字符必须使用单引号,且必须只能是单个字符。所以byte类型经常被称为character类型。
以下也都是允许的:
var a = 'A'
var a uint32 = 'A'
var a int64 = 'A'
所以,Integer类型当存储的是以单引号包围的字符时,它会将字符转换成它二进制值对应的数值。同样适用于unicode字符,它将用来存放各字节对应的二进制的数值:
var a int64 = '我' // a=25105
由于我在Go中占用3字节,所以保存到byte中是报错的:
var a byte = '我'
可以保存它的unicode字符的代码点:
var a byte = 'u0041' // a=65,代表的字符A
如果不知道代码点的值,可以将其以int类型保存并输出。
fmt.Printf("%d", '我') // 25105
如果想将byte值转换为字符,可以使用string()函数做简单的类型转换:
var a = 'A'
println(string(a)) // 输出:A
float和complex
float是浮点数(俗称小数),例如0.0 3.0 -3.12 -3.120等。
Go中的浮点数类型float有两种:float32和float64。
complex表示复数类型(虚数),有complex64和complex128。
浮点数在计算机系统中非常复杂,对于学习来说,只需将其认为是数学中的一种小数即可。但以下几个注意点需要谨记心中:
- 浮点数是不精确的。例如
1.01-0.99从数学运算的角度上得到的值是0.02,但实际上的结果是0.020000000000000018(python运算的结果),在Go中会将其表示为+2.000000e-002。这个结果是一种极限趋近于我们期待值的结果。 - float32的精度(7个小数位)低于float64(15个小数位),所以float64类型的值比float32类型的值更精确。
- 因为浮点数不精确,所以尽量不要对两个浮点数数进行等值
==和不等值!=比较,例如(3.2-2.8) == 0.4返回Flase。如果非要比较,应该通过它们的减法求绝对值,再与一个足够小(不会影响结果)的值做不等比较,例如abs((3.2-2.8)-0.4) < 0.0002返回True。
一般来说,在程序中需要使用浮点数的时候都使用float64类型,不仅因为精确,更因为几乎所有包中需要float参数的类型都是float64。
在Go的数学运算中,默认取的是整型数据,如果想要得到浮点数结果,必须至少让运算的一方写成浮点数格式:
var a := 3/2 // a得到截断的整数:a=1
var b := 3/2.0 // b为浮点数b=+1.500000e+000
var c := 3 + 2.0 // c为浮点数
string类型
Go中的string用于保存UTF-8字符序列,它是动态大小的。对于字母和英文字母,它占用一个字节,对于其它unicode字符,按需占用2-4个字节。例如中文字符占用3个字节。
Go中的string类型要使用双引号或反引号包围,它们的区别是:
- 双引号是弱引用,其内可以使用反斜线转义符号,如
ab cd表示ab后换行加cd - 反引号是强引用,其内任何符号都被强制解释为字面意义,包括字面的换行。也就是所谓的裸字符串。
func main() {
println("abc
def")
println(`ABC
DEF`)
}
上面的结果将输出:
abc
def
ABC
DEF
不能使用单引号包围,单引号包围的表示它的二进制值转换成十进制的数值。例如字母对应的是ASCII码。这个在前面byte类型中介绍过。所以,使用单引号包围的字符实际上是整数数值。例如'a'等价于97。
string的底层是byte数组,每个string其实只占用两个机器字长:一个指针和一个长度。只不过这个指针在Go中完全不可见,所以对我们来说,string是一个底层byte数组的值类型而非指针类型。
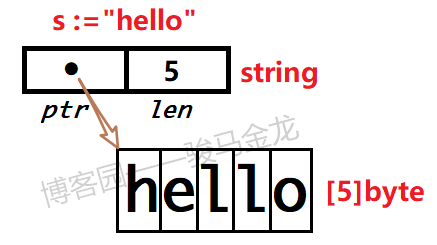
所以,可以将一个string使用append()或copy()拷贝到一个给定的byte slice中,也可以使用slice的切片功能截取string中的片段。
func main() {
var a = "Hello Gaoxiaofang"
println(a[2:3]) // 输出:l
s1 := make([]byte,30)
copy(s1,a) // 将字符串保存到slice中
println(string(s1)) // 输出"Hello Gaoxiaofang"
}
字符串串接
使用加号+连接两段字符串:"Hello" + "World"等价于"HelloWorld"。
可以通过+的方式将多行连接起来。例如:
str := "Beginning string "+
"second string"
字符串连接+操作符强制认为它两边的都是string类型,所以"abcd" + 2将报错。需要先将int类型的2转换为字符串类型(不能使用string(2)的方式转换,因为这种转换方式不能跨大类型转换,只能使用strconv包中的函数转换)。
另一种更高效的字符串串接方式是使用strings包中的Join()函数,它可以在缓冲中将字符串串接起来。
字符串长度
使用len()取字节数量(不是字符数量)。
例如len("abcde")返回5,size(我是中国人)返回15。
字符串截取
可以将字符串当作数组,使用索引号取部分字符串(按字节计算),索引号从0开始计算,如"abcd"[1]。
从字符串取字符的时候,需要注意的是index按字节计算而非按字符计算。两种取数据方式:
"string"[x]
"string"[x:y]
第一种方式将返回第(x+1)个字节对应字符的二进制数值,例如字母将转换为ASCII码,unicode将取对应字节的二进制转换为数值。
第二种方式将返回第(x+1)字节到第y字节中间的字符,Go中采取"左闭右开"的方式,所以所截取部分包括index=x,但不包括index=y。
例如:
func main() {
println("abcde"[1]) // (1).输出"98"
println("我是中国人"[1]) // (2).输出"136"
println("abcde"[0:2]) // (3).输出"ab"
println("我是中国人"[0:3]) // (4).输出"我"
println("abcde"[3:4]) // (5).输出"d"
}
分析每一行语句:
- (1).取第2个字节的二进制值,即字符b对应的值,其ASCII为98
- (2).取第2个字节的二进制值,因为中文占用3个字节,所以取第一个字符"我"的第二个字节部分,转换为二进制值,为136
- (3).取第1个字节到第3个字节(不包括)中间的字符,所以输出"ab"
- (4).取前三个字节对应的字符,所以输出"我"
- (5).取第4个字节对应的字符,所以输出d
字符串遍历
字符串是字符数组,如果字符串中全是ASCII字符,直接遍历即可,但如果包含了多字节字符,则可以[]rune(str)转换后后再遍历。
package main
import "fmt"
func main() {
str := "Hello 你好"
r := []rune(str) // 8
for i := 0; i < len(r); i++ {
fmt.Printf("%c", r[i])
}
}
字符串比较
可以使用< <= > >= == !=对字符串进行比较,它将一个字符一个字符地比对。字母以A-Za-z的ASCII方式排列。
// 字符串比较
println("a" < "B") // false
// 数值比较,不是字符串比较
println('a' == 97) // true
修改字符串
字符串是一个不可变对象,所以对字符串s截取后赋值的方式s[1]="c"会报错。
要想修改字符串中的字符,必须先将字符串拷贝到一个byte slice中,然后修改指定索引位置的字符,最后将byte slice转换回string类型。
例如,将"gaoxiaofang"改为"maoxiaofang":
s := "gaoxiaofang"
bs := []byte(s)
bs[0] = 'm' // 必须使用单引号
s = string(bs)
println(s)
注意修改字符的时候,必须使用单引号,因为它是byte类型。
布尔类型(bool)
bool类型的值只有两种:true和false。
有3种布尔逻辑运算符:&& || !,分别别是逻辑与,逻辑或,取反。
func main() {
println(true && true) // true
println(true && false) // false
println(true || true) // true
println(true || false) // true
println(!true) // false
}
Go是一门非常严格的怨言,在使用==进行等值比较的时候,要求两边的数据类型必须相同,否则报错。如果两边数据类型是接口类型,则它们必须实现相同的接口函数。如果是常量比较,则两边必须是能够兼容的数据类型。
在printf类的函数的格式中,占位符%t用于代表布尔值。
布尔类型的变量、函数名应该以is或Is的方式开头来表明这是一个布尔类型的东西。例如isSorted()函数用于检测内容是否已经排序,IsFinished()用于判断是否完成。
type关键字:类型别名
可以使用type定义自己的数据类型,例如struct、interface。
还可以使用type定义类型的别名。例如,定义一个int类型的别名INT:
type INT int
这样INT类型的底层数据结构还是int类型。可以将它和int一样使用:
var a INT = 5
type中可以一次性声明多个别名:
type (
CT int
IT int32
DT float32
)
获取数据类型
reflect包的TypeOf(),或者Printf/Sprintf的"%T"。
package main
import (
"reflect"
"fmt"
)
type IT int32
func main() {
var a IT = 322
var b = 22
fmt.Println(reflect.TypeOf(a)) // main.IT
fmt.Println(reflect.TypeOf(b)) // int
fmt.Println(fmt.Sprintf("%T", a)) // main.IT
}
数据类型的大小
unsafe包的Sizeof()查看变量或常量所属数据类型占用空间的大小。
package main
import (
"unsafe"
"fmt"
)
type IT int32
func main() {
var a IT = 322
var b = 22
fmt.Println(unsafe.Sizeof(a)) // 4
fmt.Println(unsafe.Sizeof(b)) // 8
}