
Problem:
- Kaggle 上的比赛,识别12种类型的植物,a dataset containing images of approximately 960 unique plants belonging to 12 species at several growth stages.
- Dataset:
- train/, test/ 分别包含训练集图片和测试集图片,train.csv和test.csv包含了图片名和其对应的种类标签。
流程:
1. Get Data
2. 预处理Cleaning Data
2.1 Masking green plant
假设所有植物都是绿色的,那么可以创建一个mask来除去除了绿色部分以外的图像(认为是背景)。
使用HSV,比起RGB更容易表示color range.
* HSV: Hue, Saturation, Value:色调(H),饱和度(S),明度(V).
* 为了除去noise,先blur image(模糊处理)。基本思路就是:在原始图像基础上创建HSV图像,创建一个基于绿色range的mask,将它转换成boolean mask,然后应用在原始图像上。
1. Gaussian blur除噪
2. RGB转换成HSV:cv2.cvtColor(rgb_image, cv2.COLOR_BGR2HSV)
3. 建立mask:
mask = cv2.inRange(hsv, lower_green, upper_green)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (11,11))
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
cv2.inRange:
-
- 第一个参数:hsv指的是原图
- 第二个参数:lower_red指的是图像中低于这个lower_red的值,图像值变为0
- 第三个参数:upper_red指的是图像中高于这个upper_red的值,图像值变为0
- 而在lower_red~upper_red之间的值变成255
cv2.getStructuringElement(): 定义结构元素(参考5,6)
cv2.morphologyEx(): 闭运算(参考7),先膨胀后腐蚀,一般用来填充黑色的小像素点。
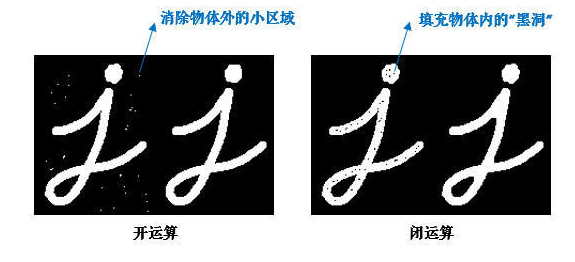 (参考8)
(参考8)
4. 应用boolean mask,得到无背景图像:
bMask = mask>0
2.2 Normalize Input 归一化
clearTrainImg = clearTrainImg / 255
2.3 Categories Labels 类别标签
将12个类别标签进行one-hot编码
1. 将字符类的标签(不连续的标签)进行编号:sklearn.preprocessing.LabelEncoder.transform(strlabel)
* 与文本处理不同,这里的编号和频次无关。
2. 对类别编号进行独热向量编码:keras.utils.np_utils.to_categorical(encodedStrLabel)
3. 建模 Model
3.1 数据分割
- train set中留出10%作为验证集。
- 由于数据不均衡,进行分层采样:stratify = trainlabel
sklearn.model_selection.train_test_split(traindata, trainlabel, /
test_size = 0.1, random_state = see, /
stratify = trainlabel)
3.2 Data generator
为防止过拟合,创建一个image generator,随机旋转、缩放、平移、翻转图像。
3.3 Create Model
方案一:keras序贯模型
- 6 CONV layers, 3 FC layers.
- 前两个卷积层包含64个卷积核,第三四个128个卷积核,第五六个256个卷积核。
- 每两个卷积层后接一个max池化层。
- 每两个卷积层后使用一个dropout layer(10% btw CONV Layers, 50% btw FC layers)
- 在每一层之间,使用batch normalization layer。
方案二:keras Xception模型
base_model = Xception(weights='imagenet', input_shape=(img_size, img_size, 3), include_top=False) x = base_model.output x = GlobalAveragePooling2D()(x) x = Dropout(0.5)(x) x = Dense(1024, activation='relu')(x) x = Dropout(0.5)(x) predictions = Dense(12, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions) model.compile(optimizer='Adadelta', loss='categorical_crossentropy', metrics=['accuracy']) model.fit_generator(datagen.flow(train_img, train_label, batch_size=batch_size), steps_per_epoch=len(train_img)//batch_size, epochs=100, verbose=1) model.save_weights('Xception.h5')
3.4 Fit Model
方案一:CNN
1 from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, CSVLogger 2 3 # learning rate reduction 4 learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc', 5 patience=3, 6 verbose=1, 7 factor=0.4, 8 min_lr=0.00001) 9 10 # checkpoints 11 filepath="./drive/DataScience/PlantReco/weights.best_{epoch:02d}-{val_acc:.2f}.hdf5" 12 checkpoint = ModelCheckpoint(filepath, monitor='val_acc', 13 verbose=1, save_best_only=True, mode='max') 14 filepath="./drive/DataScience/PlantReco/weights.last_auto4.hdf5" 15 checkpoint_all = ModelCheckpoint(filepath, monitor='val_acc', 16 verbose=1, save_best_only=False, mode='max') 17 18 # all callbacks 19 callbacks_list = [checkpoint, learning_rate_reduction, checkpoint_all]
1 # fit model 2 hist = model.fit_generator(datagen.flow(trainX, trainY, batch_size=75), 3 epochs=35, validation_data=(testX, testY), 4 steps_per_epoch=trainX.shape[0], callbacks=callbacks_list)


Total params: 3,320,396 Trainable params: 3,317,580 Non-trainable params: 2,816 _________________________________________________________________ Epoch 1/35 57/57 [==============================] - 139s 2s/step - loss: 2.6670 - acc: 0.2442 - val_loss: 6.4567 - val_acc: 0.2400 Epoch 00001: val_acc improved from -inf to 0.24000, saving model to ./model/weights.best_01-0.24.hdf5 Epoch 00001: saving model to ./model/weights.last_auto4.hdf5 Epoch 2/35 57/57 [==============================] - 137s 2s/step - loss: 1.8978 - acc: 0.4061 - val_loss: 1.7727 - val_acc: 0.5053 Epoch 00002: val_acc improved from 0.24000 to 0.50526, saving model to ./model/weights.best_02-0.51.hdf5 Epoch 00002: saving model to ./model/weights.last_auto4.hdf5 Epoch 3/35 57/57 [==============================] - 137s 2s/step - loss: 1.5648 - acc: 0.4727 - val_loss: 1.4101 - val_acc: 0.5916 Epoch 00003: val_acc improved from 0.50526 to 0.59158, saving model to ./model/weights.best_03-0.59.hdf5 Epoch 00003: saving model to ./model/weights.last_auto4.hdf5 Epoch 4/35 57/57 [==============================] - 137s 2s/step - loss: 1.3839 - acc: 0.5357 - val_loss: 1.9968 - val_acc: 0.5305 Epoch 00004: val_acc did not improve from 0.59158 Epoch 00004: saving model to ./model/weights.last_auto4.hdf5 Epoch 5/35 57/57 [==============================] - 137s 2s/step - loss: 1.2802 - acc: 0.5673 - val_loss: 1.3310 - val_acc: 0.6042 Epoch 00005: val_acc improved from 0.59158 to 0.60421, saving model to ./model/weights.best_05-0.60.hdf5 Epoch 00005: saving model to ./model/weights.last_auto4.hdf5 Epoch 6/35 57/57 [==============================] - 137s 2s/step - loss: 1.1244 - acc: 0.6234 - val_loss: 1.9959 - val_acc: 0.4737 Epoch 00006: val_acc did not improve from 0.60421 Epoch 00006: saving model to ./model/weights.last_auto4.hdf5 Epoch 7/35 57/57 [==============================] - 136s 2s/step - loss: 0.9713 - acc: 0.6744 - val_loss: 1.0211 - val_acc: 0.6653 Epoch 00007: val_acc improved from 0.60421 to 0.66526, saving model to ./model/weights.best_07-0.67.hdf5 Epoch 00007: saving model to ./model/weights.last_auto4.hdf5 Epoch 8/35 57/57 [==============================] - 137s 2s/step - loss: 0.8747 - acc: 0.6980 - val_loss: 1.2936 - val_acc: 0.5958 Epoch 00008: val_acc did not improve from 0.66526 Epoch 00008: saving model to ./model/weights.last_auto4.hdf5 Epoch 9/35 57/57 [==============================] - 136s 2s/step - loss: 0.8478 - acc: 0.7149 - val_loss: 1.8586 - val_acc: 0.5368 Epoch 00009: val_acc did not improve from 0.66526 Epoch 00009: saving model to ./model/weights.last_auto4.hdf5 Epoch 10/35 57/57 [==============================] - 137s 2s/step - loss: 0.7773 - acc: 0.7485 - val_loss: 1.2088 - val_acc: 0.6337 Epoch 00010: val_acc did not improve from 0.66526 Epoch 00010: ReduceLROnPlateau reducing learning rate to 0.0004000000189989805. Epoch 00010: saving model to ./model/weights.last_auto4.hdf5 Epoch 11/35 57/57 [==============================] - 137s 2s/step - loss: 0.6556 - acc: 0.7811 - val_loss: 0.7743 - val_acc: 0.7474 Epoch 00011: val_acc improved from 0.66526 to 0.74737, saving model to ./model/weights.best_11-0.75.hdf5 Epoch 00011: saving model to ./model/weights.last_auto4.hdf5 Epoch 12/35 57/57 [==============================] - 137s 2s/step - loss: 0.6052 - acc: 0.7906 - val_loss: 0.5163 - val_acc: 0.8126 Epoch 00012: val_acc improved from 0.74737 to 0.81263, saving model to ./model/weights.best_12-0.81.hdf5 Epoch 00012: saving model to ./model/weights.last_auto4.hdf5 Epoch 13/35 57/57 [==============================] - 137s 2s/step - loss: 0.5896 - acc: 0.8044 - val_loss: 0.7790 - val_acc: 0.7242 Epoch 00013: val_acc did not improve from 0.81263 Epoch 00013: saving model to ./model/weights.last_auto4.hdf5 Epoch 14/35 57/57 [==============================] - 136s 2s/step - loss: 0.5546 - acc: 0.8112 - val_loss: 0.4168 - val_acc: 0.8611 Epoch 00014: val_acc improved from 0.81263 to 0.86105, saving model to ./model/weights.best_14-0.86.hdf5 Epoch 00014: saving model to ./model/weights.last_auto4.hdf5 Epoch 15/35 57/57 [==============================] - 137s 2s/step - loss: 0.5266 - acc: 0.8241 - val_loss: 0.4183 - val_acc: 0.8505 Epoch 00015: val_acc did not improve from 0.86105 Epoch 00015: saving model to ./model/weights.last_auto4.hdf5 Epoch 16/35 57/57 [==============================] - 137s 2s/step - loss: 0.5353 - acc: 0.8196 - val_loss: 0.4565 - val_acc: 0.8400 Epoch 00016: val_acc did not improve from 0.86105 Epoch 00016: saving model to ./model/weights.last_auto4.hdf5 Epoch 17/35 57/57 [==============================] - 136s 2s/step - loss: 0.5198 - acc: 0.8213 - val_loss: 0.3826 - val_acc: 0.8568 Epoch 00017: val_acc did not improve from 0.86105 Epoch 00017: ReduceLROnPlateau reducing learning rate to 0.00016000000759959222. Epoch 00017: saving model to ./model/weights.last_auto4.hdf5 Epoch 18/35 57/57 [==============================] - 137s 2s/step - loss: 0.4561 - acc: 0.8409 - val_loss: 0.3909 - val_acc: 0.8716 Epoch 00018: val_acc improved from 0.86105 to 0.87158, saving model to ./model/weights.best_18-0.87.hdf5 Epoch 00018: saving model to ./model/weights.last_auto4.hdf5 Epoch 19/35 57/57 [==============================] - 136s 2s/step - loss: 0.4215 - acc: 0.8557 - val_loss: 0.3398 - val_acc: 0.8779 Epoch 00019: val_acc improved from 0.87158 to 0.87789, saving model to ./model/weights.best_19-0.88.hdf5 Epoch 00019: saving model to ./model/weights.last_auto4.hdf5 Epoch 20/35 57/57 [==============================] - 136s 2s/step - loss: 0.4329 - acc: 0.8463 - val_loss: 0.3847 - val_acc: 0.8674 Epoch 00020: val_acc did not improve from 0.87789 Epoch 00020: saving model to ./model/weights.last_auto4.hdf5
利用CNN训练模型的时候发现,在kaggle kernel上的结果很好,初始acc就达到0.97,但在本地电脑和Linux服务器上的结果就很差,初始acc只有0.06,在本地电脑上训练,acc可以慢慢增长,在第一轮训练到四分之一的时候达到0.6,但在服务器上的结果一直在0.1上下徘徊,后来将参数steps_per_epoch改为(train_size/batch_size)后,效果变好一点,如上,最高的val_acc达到0.91(第34、35轮)。原因可能是kaggle的kernel里加载了之前训练过的模型,事实上要训练一个表现不错的CNN模型需要花很久,所以fine-tune,如加载imagenet的模型权重(已经具有不错的信息抽取能力)可以提高训练效率。Kera的应用模块Application提供了带有预训练权重的Keras模型,这些模型可以用来进行预测、特征提取和finetune。方案二就是利用Xception来进行训练。
方案二:Xception
部分结果:
Epoch 1/100 267/267 [==============================] - 213s 798ms/step - loss: 1.9894 - acc: 0.3535 - val_loss: 2.9473 - val_a Epoch 00001: val_acc improved from -inf to 0.49474, saving model to ./model_Xception/weights.best_01-0.49.hdf5 Epoch 00001: saving model to ./model_Xception/weights.last_auto4.hdf5 Epoch 2/100 267/267 [==============================] - 202s 755ms/step - loss: 1.0212 - acc: 0.6881 - val_loss: 2.3308 - val_a Epoch 00002: val_acc improved from 0.49474 to 0.65053, saving model to ./model_Xception/weights.best_02-0.65.hdf5 Epoch 00002: saving model to ./model_Xception/weights.last_auto4.hdf5 Epoch 3/100 267/267 [==============================] - 201s 753ms/step - loss: 0.6963 - acc: 0.7791 - val_loss: 0.6494 - val_a Epoch 00003: val_acc improved from 0.65053 to 0.80000, saving model to ./model_Xception/weights.best_03-0.80.hdf5 Epoch 00003: saving model to ./model_Xception/weights.last_auto4.hdf5 Epoch 4/100 267/267 [==============================] - 201s 752ms/step - loss: 0.5558 - acc: 0.8252 - val_loss: 1.6157 - val_a Epoch 00004: val_acc did not improve from 0.80000 Epoch 00004: saving model to ./model_Xception/weights.last_auto4.hdf5 Epoch 5/100 267/267 [==============================] - 200s 751ms/step - loss: 0.4825 - acc: 0.8448 - val_loss: 0.4034 - val_a Epoch 00005: val_acc improved from 0.80000 to 0.87158, saving model to ./model_Xception/weights.best_05-0.87.hdf5 Epoch 00005: saving model to ./model_Xception/weights.last_auto4.hdf5 Epoch 6/100 267/267 [==============================] - 200s 751ms/step - loss: 0.4225 - acc: 0.8636 - val_loss: 0.4724 - val_a Epoch 00006: val_acc did not improve from 0.87158 Epoch 00006: saving model to ./model_Xception/weights.last_auto4.hdf5 Epoch 7/100 144/267 [===============>..............] - ETA: 1:31 - loss: 0.4090 - acc: 0.8685
其它:
加载之前训练的模型继续训练:
1 base_model = Xception(weights=None, input_shape=(ScaleTo, ScaleTo, 3), include_top=False) 2 x = base_model.output 3 x = GlobalAveragePooling2D()(x) 4 x = Dropout(0.5)(x) 5 x = Dense(1024, activation='relu')(x) 6 x = Dropout(0.5)(x) 7 predictions = Dense(num_classes, activation='softmax')(x) 8 9 model = Model(inputs=base_model.input, outputs=predictions) 10 model.load_weights('./model_Xception/weights.best_07-0.89.hdf5') 11 model.compile(optimizer='Adadelta', 12 loss='categorical_crossentropy', 13 metrics=['accuracy'])
4. 评估模型
4.1 从文档加载模型
1. 利用numpy.savez将训练时的分割后数据保存,以备后用:
np.savez('Data.npz', trainX=trainX, testX=testX, trainY=trainY, testY=testY)
2. 加载数据、训练好的模型权重:此处的数据和模型要按照训练时的处理
# compile model model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) d = np.load("./Data.npz") # d = dict(zip(("trainY","testY","testX", "trainX"), (data[k] for k in data))) trainX = d['trainX'] testX = d['testX'] trainY = d['trainY'] testY = d['testY'] #print(trainX.shape, testX.shape, trainY.shape, testY.shape) model.load_weights('./model/weights.best_35-0.91.hdf5') predY = model.predict(testX) np.savez('cnn_predY.npz', y = predY) print(model.evaluate(trainX, trainY)) # Evaluate on train set print(model.evaluate(testX, testY)) # Evaluate on test set
3. 输出结果:
4275/4275 [==============================] - 35s 8ms/step [0.2199308500791851, 0.9174269007102788] 475/475 [==============================] - 4s 8ms/step [0.23087565186776612, 0.9094736845869767]
4.2 混淆矩阵
from sklearn.metrics import confusion_matrix confusionMTX = confusion_matrix(trueY, predYClasses)
方案一:CNN
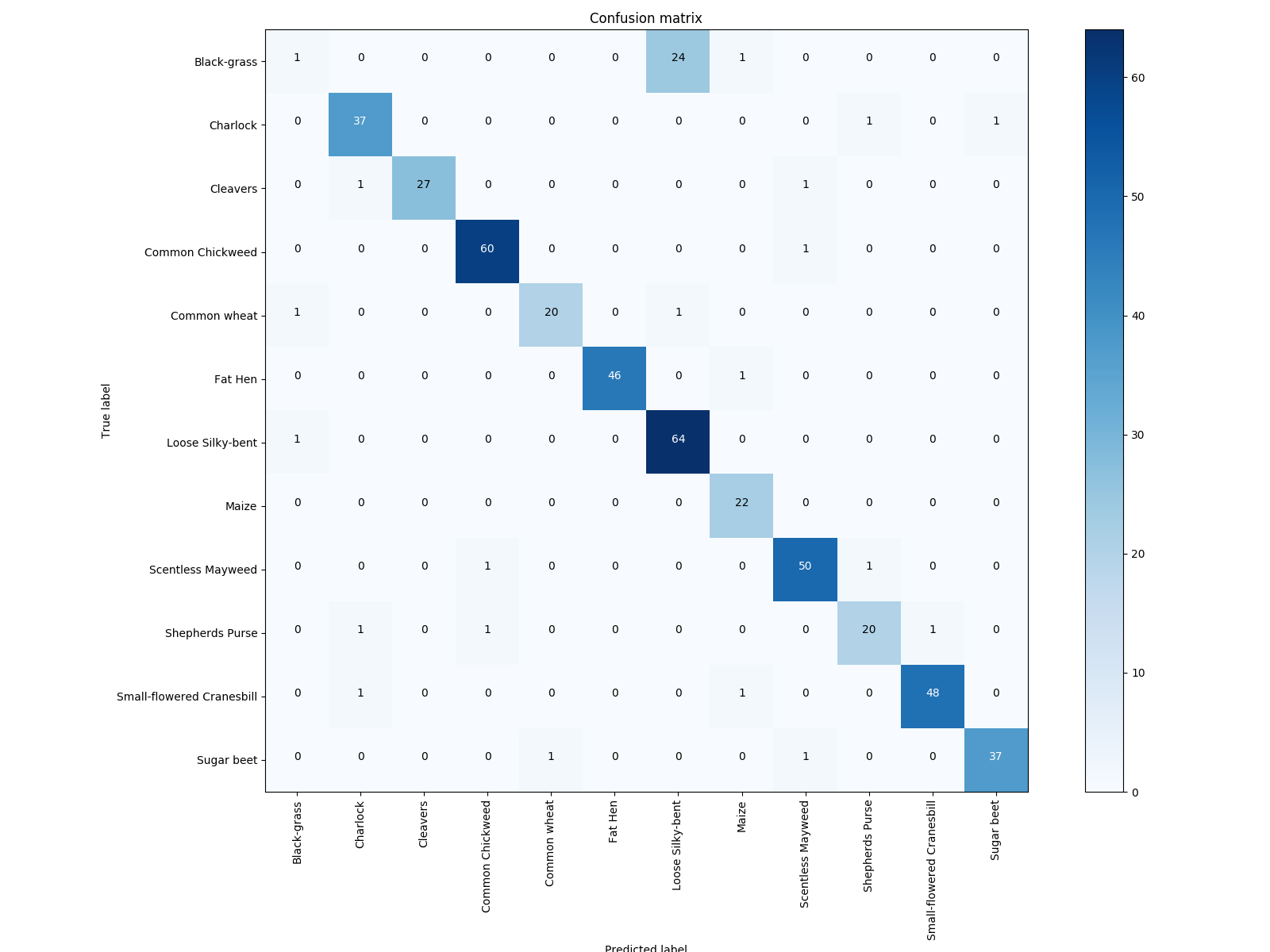
4.3 Get results
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.load_weights('./model/weights.best_35-0.91.hdf5')
# prediction
pred = model.predict(clearTestImg)
# Write result to file
predNum = np.argmax(pred, axis=1)
le_classes = np.load('plantLabelEncoder_classes.npz')
predStr = le_classes['arr_0']
res = {'file': testId, 'species': predStr[predNum]}
res = pd.DataFrame(res)
res.to_csv("res.csv", index=False)
—————————————————————————————————
参考:
1. https://www.kaggle.com/gaborvecsei/plant-seedlings-fun-with-computer-vision
2. https://blog.csdn.net/yeahDeDiQiZhang/article/details/79541040
3. https://www.kaggle.com/gaborvecsei/plants-t-sne
4. https://www.kaggle.com/nikkonst/plant-seedlings-with-cnn-and-image-processing
5. 形态学处理 https://blog.csdn.net/sunny2038/article/details/9137759
6. opencv中的cv2.getStructuring(): https://blog.csdn.net/u012193416/article/details/79312972
7. python opencv入门 形态学转换 (13):https://blog.csdn.net/tengfei461807914/article/details/76242362
8. https://www.jianshu.com/p/05ef50ac89ac