Redis 面试题
Q:Redis有哪些优势?
- 速度快,因为数据存在内存中
- 支持丰富数据类型,支持string,list,set,sorted set,hash
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
- 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
- 单线程,单进程,采用IO多路复用技术。
Q:哪些场景不适合使用Redis?
- 更新频繁的情景,对于更新频率过高的数据,频繁同步缓存中的数据会花费较多的时间。
- 一致性要求严格的情景,只要数据产生了副本,就一定会出现副本数据与原数据之间的差异;
- 读少的情景,对于读取非常少的系统而言,使用缓存就完全没有意义了,毕竟使用缓存的目的是为了读取数据更高效;
- 数据量很小的情况下,也没必要使用缓存了,因为数据库本身完全可以支持。
Redis数据结构
Q:Redis的存储结构是怎样的?
key-value键值对。
Q:Redis支持哪些数据结构?
string(字符串),hash(哈希),list(队列),set(集合)及 sorted set(有序集合)。其他的还有 bitmaps(位图),hyperloglog(可用于基数统计),GEO(地理位置定位) 等。
Q:Redis的数据结构,有哪些应用场景?
string,简单地get/set缓存。
hash,可以缓存用户资料。比如命令: hmset user1 name "lin" sex "male" age "25" ,缓存用户user1的资料,姓名为lin,性别为男,年龄25。
list,可以做队列。往list队列里面push数据,然后再pop出来。
set,set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。
zset,sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以用来做排行榜。
详情见:https://www.cnblogs.com/expiator/p/10274151.html
Q:Redis做计数器,可以使用哪些命令?
incr,做加一操作,是原子性的。
Q:Redis的数据结构,底层分别是由什么实现的?
(1)string:Redis自己构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。
(2)list:Redis的List,底层是ZipList,不满足ZipList就使用quicklist双向链表。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist ,即压缩列表 . 它将所有的元素紧挨着一起存储,分配的是一块连续的内存,由于内存是连续的,就减少了很多内存碎片和指针的内存占用,进而节约了内存。
当数据量比较多才会改成 quicklist. quickList就是一个标准的双向链表的配置,有head 有tail;
(3)hash:底层是zipList和hashTable。
当同时满足下面两个条件时,使用ziplist(压缩列表)编码: 列表保存元素个数小于512个; 每个元素长度小于64字节
不能满足这两个条件的时候使用 hashtable 编码。
hashtable 编码的哈希表对象底层使用字典数据结构,哈希对象中的每个键值对都使用一个字典键值对。
(4)set:底层是intset 和 HashTable。
intset 编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
hashtable 编码的集合对象使用 字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值则全部设置为 null。这里可以类比Java集合中HashSet 集合的实现,HashSet 集合是由 HashMap 来实现的,集合中的元素就是 HashMap 的key,而 HashMap 的值都设为 null。
当集合同时满足以下两个条件时,使用 intset 编码:集合对象中所有元素都是整数;集合对象所有元素数量不超过512。
不能满足这两个条件的就使用 hashtable 编码。
(5)sorted set:底层是 zipList 和 skipedList 。
skiplist 编码的有序集合对象使用 zset 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表:
字典的键保存元素的值,字典的值则保存元素的分值;跳跃表节点的 object 属性保存元素的成员,跳跃表节点的 score 属性保存元素的分值。
typedef struct zset{
//跳跃表
zskiplist *zsl;
//字典
dict *dice;
} zset;
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:保存的元素数量小于128;保存的所有元素长度都小于64字节。
不能满足上面两个条件的使用 skiplist 编码。
参考资料:https://www.cnblogs.com/ysocean/p/9102811.html
详情见:https://blog.csdn.net/Sqdmn/article/details/103634208
Q:为什么sorted set(有序集合)需要同时使用跳跃表和字典来实现?
使用字典,根据key查找value的复杂度是O(1),但是字典是以无序的方式来保存元素的,进行范围型操作会比较麻烦。
而跳跃表进行范围型操作会比较快。
因此sorted set(有序集合)需要同时使用跳跃表和字典来实现。
Q:讲一下SDS的存储结构?
struct sdshdr {
//记录buf数组中已使用字节的数量
//等于SDS所保存字符串的长度
int len;
//记录buf数组中未使用字节的数量
int free;
//字节数组,用于保存字符串。SDS遵循C字符串以空字符结尾的惯例。比如'R','e','d','i','s','\0'
char buf[];
}
Q:C字符串和SDS,有什么区别?
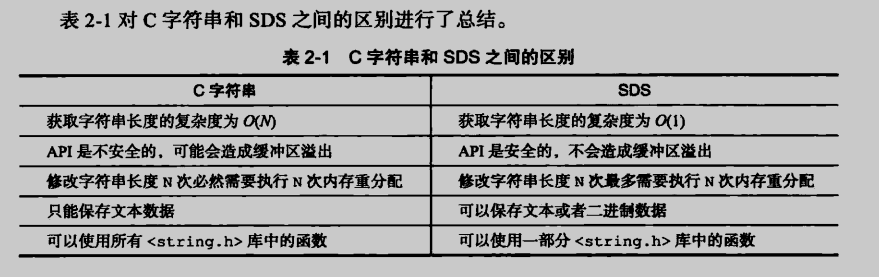
详情见: 《Redis设计与实现》
Q:对比C字符串,Redis的SDS有哪些优点?
(1)常数复杂度获取字符串的长度。因为SDS中的len字段就记录了字符串长度。
(2)杜绝缓冲区溢出。
(3)减少修改字符串长度时所需的内存重分配的次数。
(4)二进制安全。
(5)兼容部分C字符串的函数。
Redis持久化
Q:Redis怎么保证可靠性?
Q:Redis的持久化方式有哪些?有哪些优缺点?
一个可靠安全的系统,肯定要考虑数据的可靠性,尤其对于内存为主的redis,就要考虑一旦服务器挂掉,启动之后,如何恢复数据的问题,也就是说数据如何持久化的问题。
-
AOF,就是备份操作记录。AOF由于是备份操作命令,备份快,恢复慢。
AOF以独立日志的方式,记录了每次写入命令,重启时再重新执行AOF文件中的命令来恢复数据。AOF的工作流程包括:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)。
AOF持久化的优缺点如下:
优点:与RDB持久化可能丢失大量的数据相比,AOF持久化的安全性要高很多。通过使用everysec选项,用户可以将数据丢失的时间窗口限制在1秒之内。
缺点:AOF文件存储的是协议文本,它的体积要比二进制格式的”.rdb”文件大很多。AOF需要通过执行AOF文件中的命令来恢复数据库,其恢复速度比RDB慢很多。AOF在进行重写时也需要创建子进程,在数据库体积较大时将占用大量资源,会导致服务器的短暂阻塞。 -
RDB,就是备份所有数据,使用了快照。RDB恢复数据比较快。
RDB(Redis Database)是Redis默认采用的持久化方式,它以快照的形式将进程数据持久化到硬盘中。RDB会创建一个经过压缩的二进制文件,文件以“.rdb”结尾,内部存储了各个数据库的键值对数据等信息。RDB持久化的触发方式有两种:
手动触发:通过SAVE或BGSAVE命令触发RDB持久化操作,创建“.rdb”文件;
自动触发:通过配置选项,让服务器在满足指定条件时自动执行BGSAVE命令。
其中,SAVE命令执行期间,Redis服务器将阻塞,直到“.rdb”文件创建完毕为止。而BGSAVE命令是异步版本的SAVE命令,它会使用Redis服务器进程的子进程,创建“.rdb”文件。BGSAVE命令在创建子进程时会存在短暂的阻塞,之后服务器便可以继续处理其他客户端的请求。总之,BGSAVE命令是针对SAVE阻塞问题做的优化,Redis内部所有涉及RDB的操作都采用BGSAVE的方式,而SAVE命令已经废弃.
RDB持久化的优缺点如下:
优点:RDB生成紧凑压缩的二进制文件,体积小,使用该文件恢复数据的速度非常快;
缺点:RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
无法保证最近一次快照后的数据。所以RDB持久化没办法做到实时的持久化。 -
RDB-AOF混合持久化:
Redis从4.0开始引入RDB-AOF混合持久化模式,这种模式是基于AOF持久化构建而来的。用户可以通过配置文件中的“aof-use-rdb-preamble yes”配置项开启AOF混合持久化。Redis服务器在执行AOF重写操作时,会按照如下原则处理数据:
像执行BGSAVE命令一样,根据数据库当前的状态生成相应的RDB数据,并将其写入AOF文件中;
对于重写之后执行的Redis命令,则以协议文本的方式追加到AOF文件的末尾,即RDB数据之后。
通过使用RDB-AOF混合持久化,用户可以同时获得RDB持久化和AOF持久化的优点,服务器既可以通过AOF文件包含的RDB数据来实现快速的数据恢复操作,又可以通过AOF文件包含的AOF数据来将丢失数据的时间窗口限制在1s之内。
参考资料: https://www.nowcoder.com/issue/tutorial?tutorialId=94&uuid=d96fa15a169c44e9a94dda690f27da28
Q:AOF文件过大,怎么处理?
会进行AOF文件重写。
1.随着AOF文件越来越大,里面会有大部分是重复命令或者可以合并的命令
2.重写的好处:减少AOF日志尺寸,减少内存占用,加快数据库恢复时间。
执行一个 AOF文件重写操作,重写会创建一个当前 AOF 文件的体积优化版本。
详情见: https://blog.csdn.net/stevendbaguo/article/details/82855726
Q:讲一下AOF重写的过程。
AOF文件重写的具体过程分为几步:
首先,根据当前Redis内存里面的数据,重新构建一个新的AOF文件,
然后,读取当前Redis里面的数据,写入到新的AOF文件里面,
最后,重写完成以后,用新的AOF文件覆盖现有的AOF文件.
另外,因为AOF在重写的过程中需要读取当前内存里面所有的键值数据,再生成对应的一条指令进行保存。
而这个过程是比较耗时的,对业务会产生影响。
所以Redis把重写的过程放在一个后台子进程里面来完成,
这样一来,子进程在做重写的时候,主进程依然可以继续处理客户端请求。
最后,为了避免子进程在重写过程中,主进程的数据发生变化,
导致AOF文件和Redis内存中的数据不一致的问题,Redis还做了一层优化。
就是子进程在重写的过程中,主进程的数据变更需要追加到AOF重写缓冲区里面。
等到AOF文件重写完成以后,再把AOF重写缓冲区里面的内容追加到新的AOF文件里面
Q:讲一下Redis的事务
先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令。如果想放弃这个事务,可以使用DISCARD命令。
Redis事务无法回滚,那怎么处理?
Q:怎么设置Redis的key的过期时间?
key的的过期时间通过EXPIRE key seconds命令来设置数据的过期时间。返回1表明设置成功,返回0表明key不存在或者不能成功设置过期时间。
Redis过期策略
Q:Redis的过期策略有哪些?
惰性删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key,并按照key不存在去处理。
惰性删除,对内存不太好,已经过期的key会占用太多的内存。
定期删除:每隔一段时间,就会对Redis进行检查,主动删除一批已过期的key。
定期删除的策略,默认情况下Redis每秒检测10次, 检测的对象是所有设置了过期时间的键集合,每次从这个集合中随机检测20个键查看他们是否过期,如果过期就直接删除,如果过期的key比例超过1/4,那就把上述操作重复一次(贪心算法)。同时为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过25ms。
逻辑记忆:为什么要删除?过期了没用了,要删除,得用过期删除策略。
谐音联想记忆:过惰,过除人
Q:为什么Redis不使用定时删除?
定时删除,就是在设置key的过期时间的同时,创建一个定时器,让定时器在过期时间来临时,立即执行对key的删除操作。
定时删除,会占用CPU,影响服务器的响应时间和性能。
Redis内存淘汰
Q:Redis 的内存淘汰机制都有哪些?
当前已用内存超过maxmemory限定时,会触发主动清理策略,也就是Redis的内存回收策略。
LRU、TTL。
noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息,此时Redis只响应读操作。
volatitle-lru:根据LRU算法删除设置了超时属性的键,知道腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略。
allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
allkeys-random:随机删除所有键,知道腾出足够空间为止。
volatitle-random:随机删除过期键,知道腾出足够空间为止。
volatitle-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略
更详细的策略如下:
volatile-lru:从已设置过期时间的key中,移出最近最少使⽤的key进⾏淘汰
allkeys-lru:当内存不⾜以容纳新写⼊数据时,在键空间中,移除最近最少使⽤的key(这个是最常⽤的)
volatile-ttl:从已设置过期时间的key中,移出将要过期的key
volatile-random:从已设置过期时间的key中,随机选择key淘汰
allkeys-random:从key中随机选择key进⾏淘汰
no-eviction:禁⽌淘汰数据。当内存达到阈值的时候,新写⼊操作报错
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使⽤的数据淘汰(LFU(Least
Frequently Used)算法,也就是最频繁被访问的数据将来最有可能被访问到)
allkeys-lfu:当内存不⾜以容纳新写⼊数据时,在键空间中,移除最不经常使⽤的key。
Q:手写一下LRU算法 。
主从模式、哨兵模式
Q:Redis的搭建有哪些模式?
主从模式、哨兵模式、Cluster(集群)模式。
最好是用集群模式。
详情见:https://new.qq.com/omn/20180126/20180126G00THE.html
主从模式:一主多从,读写分离。主节点写,从节点读,主从模式的弊端是如果master挂了,服务器只能进行读功能。
哨兵模式:
1.可以解决主从模式的弊端:master挂掉之后不能提供写功能。
2.哨兵模式是建立在主从模式的
3.当master挂掉之后,会自动从slave中选一个作为master。若master重新启动,master则会转化为现有的master下的一个slave
4.当slave切换时,会通过发布订阅方式,将slave所对应的master更改
5.因为哨兵也是一个进程,所以也有挂掉的可能,需要配置多个哨兵互相监督。一个哨兵可以监督多个主从数据库。同样,一个主从数据库可以被多个哨兵监督。
集群模式:
1.自动将数据进行分片,每个master上放一部分数据提供内置的高可用支持,部分master不可用时,还是可以继续工作的。
2.支撑N个redis master node,每个master node都可以挂载多个slave node。
3.高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave切换成master。
Q:讲一下Redis主从复制的过程。(Redis是怎么同步数据的?讲一下Redis的同步机制)
从机发送SYNC(同步)命令,主机接收后会执行BGSAVE(异步保存)命令备份数据。
主机备份后,就会向从机发送备份文件。主机之后还会发送缓冲区内的写命令给从机。
当缓冲区命令发送完成后,主机执行一条写命令,就会往从机发送同步写入命令。
更详细的步骤见: https://www.cnblogs.com/expiator/p/9881989.html
Q:Redis主从同步,是全量同步,还是部分同步?
redis主从数据同步可以分为全量同步和部分同步。
每个redis启动时都会生成一个随机字符串RID(replication ID ),从节点怎么判断需要同步多少呢?
通过偏移量offset来确定。主节点每次有数据写入,都会在offset上加上写入的字节长度,所以从节点通过比较RID和offset就能确定需要同步多少数据。
部分同步:
1.从节点保存的主节点RID与主节点的RID一致(相同)时,从节点非第一次同步,通过offset把这部分需要同步的数据放入缓冲区,然后异步同步到从节点。
(谐音记忆:同步,同"部"。ID相"同","部"分同步)
全量同步:
1.当从节点第一次启动,进行数据同步时,是全量同步的。
2.当从节点保存的主节点RID与主节点的RID不一致时,说明主节点可能宕机或重启过啥的,数据已经不一致了,所以需要重新全量同步,同时删除掉旧的数据。
3.当部分同步需要同步的数据超过了缓存区的大小限制时,采用全量同步。
详情见: https://blog.csdn.net/zhujuntiankong/article/details/122938306
Q:讲一下Redis哨兵机制。
下面是Redis官方文档对于哨兵功能的描述:
监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。
自动故障转移(Automatic Failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
配置提供者(Configuration Provider):客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址。
通知(Notification):哨兵可以将故障转移的结果发送给客户端。
Redis集群
Q:你用过的Redis是多主多从的,还是一主多从的?集群用到了多少节点?用到了多少个哨兵?
集群模式。三主三从。
Q:你们的Redis采用的是哪个版本?
3.0及以上。支持集群。
Q:Redis采用多主多从的集群模式,各个主节点的数据是否一致?
各个主节点的数据不会一样。每个主节点,负责一部分哈希槽的数据。
查询的时候,如果当前节点没有对应的key数据, Redis会转发到对应的节点上进行查询。
Q:Redis集群有哪些特性?
master和slaver。主从复制。哨兵模式。
Q:Redis集群会提供读写分离么?
不提供。
slave充当副本,不对外提供读、写服务,只作为故障转移使用。
哈希槽
Q:Redis集群数据分片的原理是什么?(Redis集群使用的是什么算法?)
Redis数据分片原理是哈希槽(hash slot)。
Redis 集群有 16384 个哈希槽。 每一个 Redis 集群中的节点都承担一个哈希槽的子集。
Q: Redis是怎么进行水平扩容的?
Redis的哈希槽让在集群中添加和移除节点非常容易。
在Redis集群中新增加一个主节点,主要是会重新分片,需要给新增的节点指派哈希槽。
例如,如果我想添加一个新节点 D,Redis会让我从节点 A,B, C 移动一些哈希槽到节点 D。同样地,如果我想从集群中移除节点 A,我只需要移动 A 的哈希槽到 B 和 C。 当节点 A 变成空的以后,我就可以从集群中彻底删除它。 因为从一个节点向另一个节点移动哈希槽并不需要停止操作,所以添加和移除节点,或者改变节点持有的哈希槽百分比,都不需要任何停机时间(downtime)。
Q:讲一下一致性Hash算法。
一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环, 我们对key进行哈希计算,使用哈希后的结果对2^32取模,
hash环上必定有一个点与这个整数对应。依此确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
比如,集群有四个节点 Node A、B、C、D,增加一台节点 Node X。Node X 的位置在 Node B 到 Node C 直接,那么受到影响的仅仅是 Node B 到 Node X 间的数据,它们要重新落到 Node X 上。
所以一致性哈希算法对于容错性和扩展性有非常好的支持。
参考资料: https://blog.csdn.net/qq_21125183/article/details/90019034
Q:为什么Redis Cluster分片不使用Redis一致性Hash算法?
一致性哈希算法也有一个严重的问题,就是数据倾斜。
如果在分片的集群中,节点太少,并且分布不均,一致性哈希算法就会出现部分节点数据太多,部分节点数据太少。也就是说无法控制节点存储数据的分配。
Q:集群的拓扑结构有没有了解过?集群是怎么连接的?
无中心结构。Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
Redis集群通信
Q:Redis集群中的各个节点发送和接收消息,有哪些类型?
MEET消息:发送者会向接收者发送MEET消息,请求接收者加入发送者当前所处的集群。
PING消息:集群里每个节点,每隔一秒钟就会随机选出5个节点,对这5个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。
PONG消息:当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送 者确认这条MEET消息或者PING消息已到达,接收者会向发送者返回一条PONG 消息。另外,一个节点也可以通过向集群广播自己的PONG消息来让集群中的其他 节点立即刷新关于这个节点的认识,例如当一次故障转移操作成功执行之后,新的主节点会向集群广播一条PONG消息,以此来让集群中的其他节点立即知道这个节 点已经变成了主节点,并且接管了已下线节点负责的槽。
FAIL消息:当一个主节点A判断另一个主节点B已经进人FAIL状态时,节点A 会向集群广播一条关于节点B的EAI工消息,所有收到这条消息的节点都会立即将 节点B标记为已下线。
PUBLISH消息:当节点接收到一个PUBLISH命令时,节点会执行这个命令,并向 集群广播一条PUB工ISH消息,所有接收到这条PUBLISH消息的节点都会执行相同 的PUBLISH命令。
Q:讲一下Redis集群的通信协议。
Redis集群,采用Gossip协议进行通信。
其中Gossip协议,由MEET、PING、PONG三种消息实现。
Redis缓存 面试题
Q:缓存雪崩是什么?
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。这就是缓存雪崩。
怎么预防缓存雪崩?
解决方法:在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
Q:缓存雪崩怎么处理?
- 修改数据放入缓存的时间,或修改数据在缓存中的过期时间;
- 让缓存数据永不过期;
- 互斥锁,由高并发转换成低并发,保护DB;
- 热点隔离,实时热点发现系统;
- 水平扩容数据库,压力平摊,保护DB;
- 提前压测,得出阈值,限流处理,保护服务与DB;
参考资料: https://blog.csdn.net/javahome_laohei/article/details/123724004
Q:缓存穿透是什么?
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
Q:怎么解决缓存穿透?
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存
储系统的查询压力。
另外也有一个更为简单粗暴的方法, 如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。
Q:讲一下布隆过滤器。
布隆过滤器的主要是由一个很长的二进制向量和若干个(k个)散列映射函数组成。因为每个元数据的存储信息值固定,而且总的二进制向量固定。所以在内存占用和查询时间上都远远超过一般的算法。当然存在一定的不准确率(可以控制)和不容易删除样本数据。
布隆过滤器的优点: 大批量数据去重,特别的占用内存。但是用布隆过滤器(Bloom Filter)会非常的省内存。
布隆过滤器的特点:当布隆过滤器说某个值存在时,那可能就不存在,如果说某个值不存在时,那肯定就是不存在了。
布隆过滤器的应用场景:新闻推送(不重复推送)。解决缓存穿透的问题。
Q:什么是缓存与数据库双写一致问题?
Q:如何保证缓存与数据库的一致性?
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存。
先更新数据库,再删除缓存。
Q:缓存与数据库的更新,会出现哪些问题?
1.更新DB或更新缓存两个步骤,因为无法保证原子性,只要有一个失败,都会导致数据不一致。
2.并发场景,并发写或并发读写场景导致数据不一致。
Q:先更新数据库,再更新缓存,会有什么问题?
如果同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
Q:先删除缓存,再更新数据库,会有什么问题?
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
Q:先更新数据库,再删除缓存,会有什么问题?怎么解决?
如果第一步的先更新数据库成功了,但是在第二步的删除缓存失败了,那么就会出现数据库是新数据,而缓存是旧数据,数据不一致。
怎么解决呢?延迟双删。
异步重试。删除缓存失败,那就多重试几次。
可以通过MQ重试,把需要缓存的redis的key发到MQ,MQ消费者取出缓存,并删除缓存。
详细的解决方案,见: https://www.cnblogs.com/rjzheng/p/9041659.html
Redis分布式锁 面试题
Redis分布式锁, 参数资料:https://blog.csdn.net/lisu061714112/article/details/120464096
Q:什么场景用Redis分布式锁?什么场景用zookeeper分布式锁?
如果你的实际业务场景,更需要的是保证数据高可用性。那么请使用AP类型的分布式锁,比如:redis,它是基于内存的,性能比较好,但有丢失数据的风险。
如果你的实际业务场景,更需要的是保证数据一致性。那么请使用CP类型的分布式锁,比如:zookeeper,它是基于磁盘的,性能可能没那么好,但数据一般不会丢。
参考资料:https://blog.csdn.net/lisu061714112/article/details/120464096
Q:Redis如何实现分布式锁?
使用set key value ex nx 命令。
当key不存在时,将 key 的值设为 value ,返回1。若给定的 key 已经存在,则setnx不做任何动作,返回0。
当setnx返回1时,表示获取锁,做完操作以后del key,表示释放锁,如果setnx返回0表示获取锁失败。
详细的命令如下:
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds:设置失效时长,单位秒
PX milliseconds:设置失效时长,单位毫秒
NX:key不存在时设置value,成功返回OK,失败返回(nil)
XX:key存在时设置value,成功返回OK,失败返回(nil)。
示例如下:
set name fenglin ex 100 nx
详情见:https://blog.csdn.net/qq_30038111/article/details/90696233
Q:为什么不先set nx,然后再使用expire设置超时时间?
我们需要保证setnx命令和expire命令以原子的方式执行,否则如果客户端执行setnx获得锁后,这时客户端宕机了,那么这把锁没有设置过期时间,导致其他客户端永远无法获得锁了。
Q:使用Redis分布式锁,key和value分别设置成什么?
value可以使用json格式的字符串。
示例:
{
"count":1,
"expireAt":147506817232,
"requestId":22224,
"mac":"28-D2-44-0E-0D-9A",
"threadId":14
}
Q:Redis实现的分布式锁,如果某个系统获取锁后,宕机了怎么办?
系统模块宕机的话,可以通过设置过期时间(就是设置缓存失效时间)解决。系统宕机时锁阻塞,过期后锁释放。
Q:如果线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间,这时候redis会自动释放线程A加的锁,
其他线程B就能拿到锁,怎么处理这种问题?
属于锁超时的问题。
如果达到了超时时间,但业务代码还没执行完,需要给锁自动续期。
获取锁之后,自动开启一个定时任务,每隔10秒钟,自动刷新一次过期时间。这种机制在redisson框架中,有个比较霸气的名字:watch dog,即传说中的看门狗。
Q:Redis分布式锁如何删除锁?
Q:设置缓存失效时间,那如果前一个线程把这个锁给删除了呢?
Q:如果加锁和解锁之间的业务逻辑执行的时间比较长,超过了锁过期的时间,执行完了,又删除了锁,就会把别人的锁给删了。怎么办?
这两个属于锁超时的问题。
可以将锁的value设置为Json字符串,在其中加入线程的id或者请求的id,在删除之前,get一下这个key,判断key对应的value是不是当前线程的。只有是当前线程获取的锁,当前线程才可以删除。
Q:Redis分布式锁,怎么保证可重入性?
可以将锁的value设置为Json字符串,在其中加入线程的id和count变量。
当count变量的值为0时,表示当前分布式锁没有被线程占用。
如果count变量的值大于0,线程id不是当前线程,表示当前分布式锁已经被其他线程占用。
如果count变量的值大于0,线程id是当前线程的id,表示当前线程已经拿到了锁,不必阻塞,可以直接重入,并将count变量的值加一即可。
这种思路,其实就是参考了ReentrantLock可重入锁的机制。
Q:Redis做分布式锁,Redis做了主从,如果设置锁之后,主机在传输到从机的时候挂掉了,从机还没有加锁信息,如何处理?
可以使用开源框架Redisson,采用了redLock。
Q:讲一下Redis的redLock。
RedissonRedLock加锁过程如下:
(1)循环向所有的redisson node节点加锁,假设节点数为N,例子中N等于5。
(2)如果在N个节点当中,有N/2 + 1个节点加锁成功了,那么整个RedissonRedLock加锁是成功的。
(3) 如果在N个节点当中,小于N/2 + 1个节点加锁成功,那么整个RedissonRedLock加锁是失败的。
(4) 如果中途发现各个节点加锁的总耗时,大于等于设置的最大等待时间,则直接返回失败。
使用Redlock算法,确实能解决多实例场景中,假如master节点挂了,导致分布式锁失效的问题。
参考资料:https://blog.csdn.net/lisu061714112/article/details/120464096
IO多路复用
Q:什么是IO多路复用?
IO多路复用(IO Multiplexing)一种同步IO模型,单个进程/线程就可以同时处理多个IO请求。一个进程/线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出cpu。
多路是指网络连接,复用指的是同一个进程/线程。
一个进程/线程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程/线程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
参考资料: https://blog.csdn.net/m0_51319483/article/details/124264619
Q:IO多路复用,有哪些实现方式?
select、poll、epoll
Q:Redis采用的是哪一种IO多路复用方式?
epoll。
Q:select、poll、epoll的区别?
| select | poll | epoll | |
|---|---|---|---|
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024 | 无上限 | 无上限 |
| fd拷贝 | 每次调用selec拷贝 | 每次调用poll拷贝 | fd首次调用epoll_ctl拷贝,每次调用epoll_wait不拷贝 |
| 工作效率 | 轮询O:(n) | 轮询:O(n) | 回调:O(1) |
详情见: https://blog.csdn.net/wteruiycbqqvwt/article/details/90299610
Redis限流
Q:使用 Redis设计一个限流的功能。
限流涉及的最主要的就是滑动窗口。
第一种: 使用Redis的 zset。
使用一个zset,当每一次请求进来的时候,value保持唯一,可以用UUID生成,而score可以用当前时间戳表示,因为score我们可以用来计算当前时间戳之内有多少的请求数量。而zset数据结构也提供了range方法让我们可以很轻易的获取到2个时间戳内有多少请求。
第二种:使用Redis的 list。
依靠Java的定时任务,定时往令牌桶List中加入新的令牌(使用List的rightPush方法),当然令牌也需要唯一性,这里还是用UUID生成令牌。
每访问一次请求的时候,可以从Redis中获取一个令牌,如果拿到令牌了,那就说明没超出限制,而如果拿不到,则结果相反。
详情见: https://zhuanlan.zhihu.com/p/439093222
参考资料:
《Redis设计与实现》
《Redis设计与实现》的笔记: https://www.cnblogs.com/expiator/p/10428655.html