是一种集合学习算法,可以用于分类,也可以用于回归
集合学习算法,就是把多个机器学习算法综合在一块,制造出一个更加大的模型的意思
集合算法有很多种:随机森林+梯度上升决策树等
为什么随机森林可以解决过拟合问题?
把不同的几棵决策树打包到一起,每棵树的参数都不相同,然后把每棵树预测的结果取平均值,这样既可以保留决策树们的工作成效,也可以降低过拟合的风险
随即森林的构建
#导入随机森林模型
from sklearn.ensemble import RandomForestClassifier
#载入红酒数据集
wine = datasets.load_wine()
#选择数据集的前两个特征
X = wine.data[:,:2]
y = wine.target
#将数据集拆分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y)
#设定随机森林有6棵树
forest = RandomForestClassifier(n_estimators=6,random_state=3)
#使用模型拟合数据
forest.fit(X_train,y_train)

【结果分析】:随机森林返回了包含其自身全部参数的信息
几个必要重要参数:
bootstrap 有放回抽样 指每次从样本空间中可以重复抽取同一个样本【因为样本在第一次抽取之后又放回了】
代表bootstrap sample
为什么要生成bootstrap sample数据集?
通过重新生成数据集可以让随机森林中的每一棵决策树在构建的时候彼此间有差异,再加上每棵树的结点都会去选择不同的样本特征,经过这两步后,可以确定随机森林中每棵树都不一样
max_features
算法不会让每棵决策树都生成最佳的节点,而是会在每个节点上随机选择一些样本特征,然后让其中之一有最好的拟合表现,在这里用max_features这个参数控制所选择的特征数量最大值的【不指定情况下,默认选择最大特征数量】
参数的设置:
- max_features 设置为样本全部特征数n_features意味着模型会在全部特征中筛选【即在特征选择这一步无随机性可言】
- 设为1,模型在数据特征选择上没有选择的余地【只能去寻找这1个被随机选出来的特征向量的阈值】
max_features越高,每棵树长的越像
越低,长的越不同,且因为特征太少,决策树们不得不制造更多节点来拟合数据
n_estimators
控制决策树的数量
如果用来进行回归分析——> 随机森林会把所有决策树预测的值取平均数
如果用来分类——> 把概率值平均【即投票】【如对x的分类,A说x 80%是1类,B说x 60%是2类===> 把这些概率取平均值,那边概率高,就分在哪类中】
用图形看看随机森林的分类表现
#定义图像中分区的颜色和散点图
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X[:,0].min() -1,X[:,0].max() +1
y_min,y_max = X[:,1].min() -1,X[:,1].max() +1
#用不同的背景色表示不同的分类
xx,yy = np.meshgrid(np.arange(x_min,x_max,.02),np.arange(y_min,y_max,.02))
z = forest.predict(np.c_[(xx.ravel(),yy.ravel())])
#将每个分类中的样本分配不同的颜色
z = z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx,yy,z,cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:,0],X[:,1],c=y,cmap=cmap_bold,edgecolor='k',s=20)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:RandomForest")
plt.show()
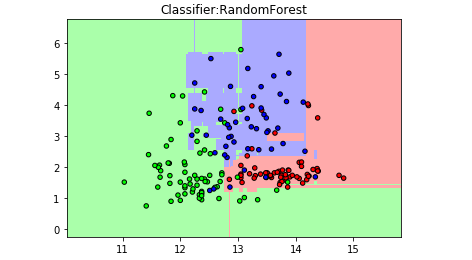
【结果分析】:分类更加细腻
优点
- 不要求对数据预处理
- 集成决策树所有优点,弥补了不足
- 支持并行处理【实现方式是n_jobs参数,记得此参数要和cpu内核数一致,多了无意义,n_jobs=-1,使用全部内核】
- 注意随机森林生成每棵树的方法是随机的,不同的random_state会导致模型完全不同,要固化其值
缺点
- 对于超高维数据集、稀疏数据集,线性模型更好
- 更消耗内存,速度慢,若要省内存+时间,用线性模型
实战——判断月薪是否>5万
导入数据集
下载:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/

载入数据集
#导入pandas库
import pandas as pd
#用pandas打开csv文件
data = pd.read_csv('adult.csv',header=None,index_col=False,names=['年龄','单位性质','权重','学历','受教育时长','婚姻状况','职业','家庭状况','种族','性别','资产所得','资产损失','周工作时长','原籍','收入'])
#为了方便显示,选取其中一部分数据
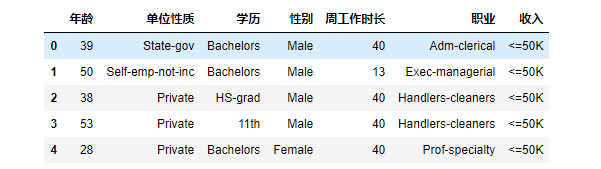
data_lite = data[['年龄','单位性质','学历','性别','周工作时长','职业','收入']]
#下面看一下前5行是不是想要的结果
display(data_lite.head())
用get_dummies处理数据【在现有数据集上建立虚拟变量,让数据集变成可用的格式】
data_dummies = pd.get_dummies(data_lite)
#对比样本原始特征和虚拟变量特征
print('原始:',list(data_lite.columns))
print('虚拟:',list(data_dummies.columns))

【结果分析】:get_dummies 把字符串类型的特征拆分开——> 以用1 0转换
data_dummies.head()

【结果分析】:从上图可以看出,新的数据集已经扩充到了46列
原因就是get_dummies 把原数据集的特征拆分成了好多列
现在,把各列分配给特征向量X,和分类标签y
#定义数据集的特征值
features = data_dummies.loc[:,'年龄':'职业_ Transport-moving']
#将特征数值赋值为X
X = features.values
#将收入大于50K作为预测目标
y = data_dummies['收入_ >50K'].values
#特征形态
print(X.shape)
#标签形态
print(y.shape)

【在上述代码中,让特征为‘年龄’这一列到‘职业_Transportion-moving’这一列,而标签是y是‘收入 _>50k’,如果大于50K,则y=1,反之y=0】
用决策树建模并预测
由上,数据集共有32561条样本数据,每条数据有44各特征值
#将数据集拆分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=0)
#以最大深度为5的随机森林拟合数据
go_dating_tree = tree.DecisionTreeClassifier(max_depth=5)
go_dating_tree.fit(X_train,y_train)
#得分
print(go_dating_tree.score(X_test,y_test))
0.7962166809974205
现在,把Mr.Z数据导入,预测
#将Mr. Z的数据输入
Mr_Z = [[37,40,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,1,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0]]
#使用模型预测
dating_dec = go_dating_tree.predict(Mr_Z)
#结果
if dating_dec == 1:
print('beyong 50K')
else:
print('no 50k')
no 50k
决策树和随机森林还有个功能:
可以帮助用户在数据集中对数据特征的重要性进行判断——》 可以通过这两个算法对高维数据进行分析,在诸多特征中保留最重要的,也便于对数据降维处理【后续详解】