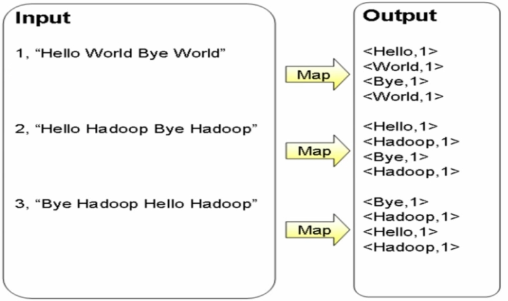
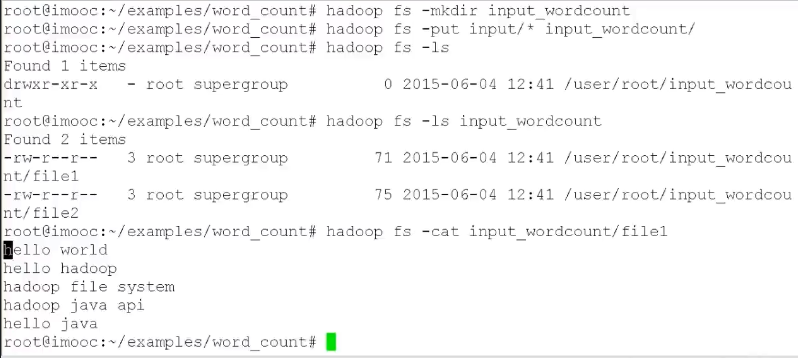
计算文件中出现每个单词的频数,输入结果按照字母顺序进行排序

Map过程(切分,中间结果:Key-Value)
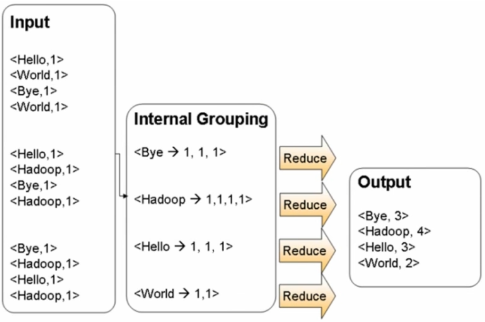
Reduce过程(合并、归约后经过Hash,所有单词放在同一个结点)
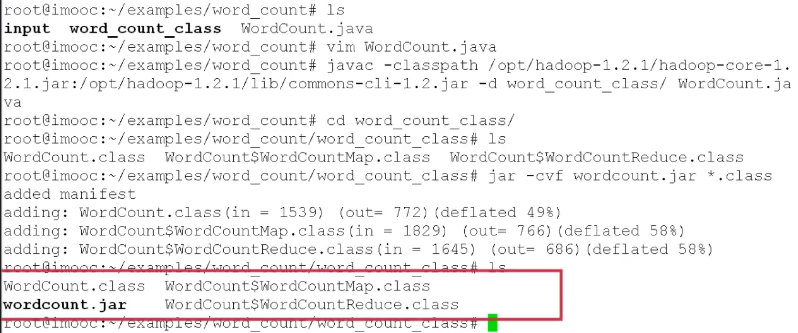
步骤:
- 编写WordCount.java,包含Mapper类和Reduce类
- 编译WordCount.java,javac -classpath
- 打包jar -cvf WordCount.jar classes/*
- 作业提交 hadoop jar WordCount.jar WordCount input output
WordCount.java
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCount { public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> { private final IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer token = new StringTokenizer(line); while (token.hasMoreTokens()) { word.set(token.nextToken()); context.write(word, one); } } } public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(WordCount.class); job.setJobName("wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordCountMap.class); job.setReducerClass(WordCountReduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }


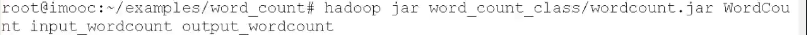


案例:利用MapReduce进行排序
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class Sort { public static class Map extends Mapper<Object, Text, IntWritable, IntWritable> { private static IntWritable data = new IntWritable(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); data.set(Integer.parseInt(line)); context.write(data, new IntWritable(1)); } } public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { private static IntWritable linenum = new IntWritable(1); public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { for (IntWritable val : values) { context.write(linenum, key); linenum = new IntWritable(linenum.get() + 1); } } } public static class Partition extends Partitioner<IntWritable, IntWritable> { @Override public int getPartition(IntWritable key, IntWritable value, int numPartitions) { int MaxNumber = 65223; int bound = MaxNumber / numPartitions + 1; int keynumber = key.get(); for (int i = 0; i < numPartitions; i++) { if (keynumber < bound * i && keynumber >= bound * (i - 1)) return i - 1; } return 0; } } /** * @param args */ public static void main(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage WordCount <int> <out>"); System.exit(2); } Job job = new Job(conf, "Sort"); job.setJarByClass(Sort.class); job.setMapperClass(Map.class); job.setPartitionerClass(Partition.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }