1.MapReduce原理
分而治之,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce)
问题1:1000副扑克牌少哪一张牌(去掉大小王)
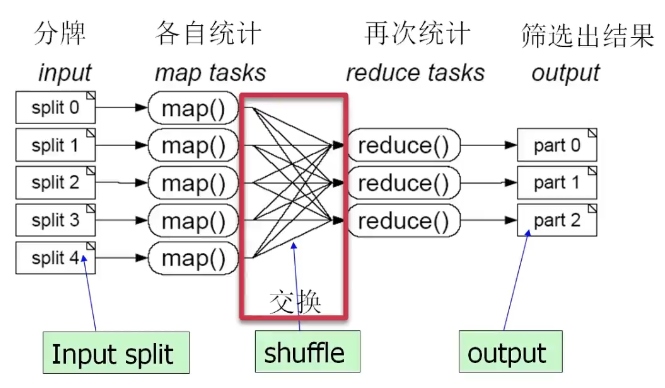
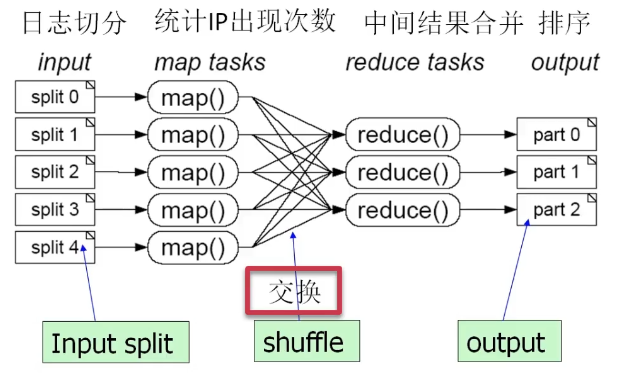
问题2:100GB的网站访问日志文件,找出访问次数最多的IP地址
- 将日志进行切分(比如按时间)
- 各自统计各IP的访问次数
- 进行归约,通过IP值进行Hash映射(相同IP归到同一个reduce)
- 排序结果
2.MapReduce的运行流程
基本概念
- Job & Task
- 一个Job是一个任务(作业),每个Job可分为多个Task,Task分为MapTask和ReduceTask
- JobTracker(master管理节点)
- 作业调度(先到先服务、公平调度器)
- 分配任务、监控任务执行进度(TaskTracker需要给出状态更新)
- 监控TaskTracker状态(是否出现故障)
- TaskTacker
- 执行任务
- 汇报任务状态
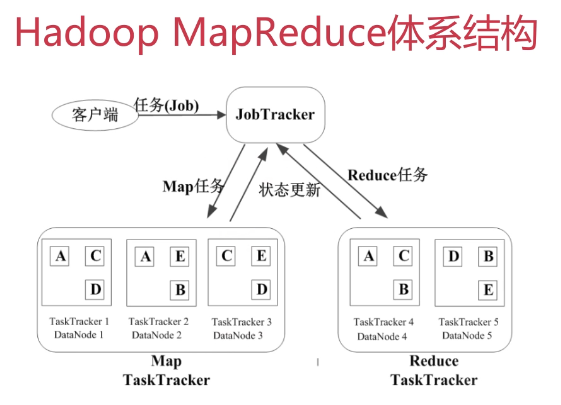
- 客户端提交Job,JobTracker将其置于候选队列
- JobTracker在适当的时候进行调度,选择一个Job,将其拆分多个Map任务和Reduce任务,分发给TaskTracker来做
- 在实际的部署中,TaskTracker和HDFS中的DataNode是同一种物理结点(这样可保证计算跟着数据走,读取数据的开销最小,移动计算代替移动数据)
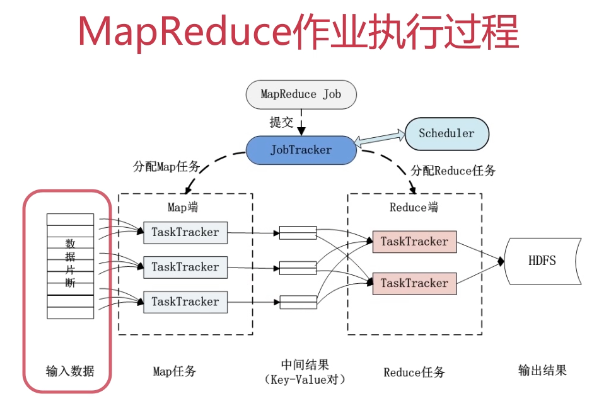
- 任何Job过来都是先交到JobTracker里,采用一定调度策略分配Map任务和Reduce任务(可多轮)
- 输入数据进行分片,按照一定规则分给TaskTracker,分配Map任务
- 任务好了之后,产生中间结果(Key-Value对)
- (Key-Value对)根据一些映射规则进行交换,再到Reduce端进行Reduce任务
- 运算完之后,数据结果写回到HDFS中
MapReduce的容错机制
- 重复执行(Job、硬件或者数据问题)(重复4次还是失败以后放弃执行)
- 推测执行(某个结点算的特别慢会再找一个TaskTracker做同样的事情,谁先算完终止另一个)(保证不会因为某一两个TaskTracker的故障导致效率很低)
