1.ElasticSearch概述
1.1.概念
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用ava开发并 Lucene使用作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构 DB Engines的统计,在2016年1月, ElasticSearch已超过Solr,成为排名第一的搜索引擎类应用。
1.2.历史
多年前,一个叫做 Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于 Lucene工作会比较困难,所以Shay开始 Lucene抽象代码以便ava程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做"Compass"。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写 Compass库使其成为一个独立的服务叫做 Elasticsearch。
第一个公开版本出现在2010年2月,在那之后 ElasticsearchGithub已经成为上最受欢迎的项目之一,代码贡献者超过300人。一家主营 Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过 Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索......
1.3.ElasticSearch简介
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELKstack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。”Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用 Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou---type)和搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用 Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
GithubElasticsearch使用检索1300亿行的代码。
但是 Elasticsearch不仅用于大型企业,它还让像 DataDogKlout以及这样的创业公司将最初的想法变成可扩展的解决方案。
Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
Elasticsearch是一个基于Apache Lucene(TM)开源搜索引擎。无论在开源还是专有领域, Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是, Lucene只是一个库。想要使用它,你必须使用ava来作为开发语言并将其直接集成到你的应用中,更糟糕的是, Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏 Lucene的复杂性,从而让全文搜索变得简单。
1.4.Solr简介
Solr是 Apache下的一个顶级开源项目,采用ava开发,它是基于 Lucene的全文搜索服务器。Solr提供 Lucene了比更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在 Jetty TomcatServlet等这些容器中,Solr索引的实现方法很简单,用pT方法向olr服务器发送一个描述 Field XML Solrxml Solr HTTP get,solr及其内容的XML文档,Solr根据xml文档添加、删除、更新索引。Solr搜索只需要发送Htpget请求,然后对Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建U的功能,Solr提供了一个管理界面,通过管理界面可以查询solr的配置和运行情况。
Solr是基 lucene于开发企业级搜索服务器,实际上就是封装了 lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于web-serviceAPl接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引也可以通过提出查找请求,并得到返回结果。
1.5.Lucene简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。 Lucene是一套用于全文检索和搜寻的开源程式库,由 Apache软件基金会支持和提供。 Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在ava开发环 Lucene境里是一个成的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费aa信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。那什么是全文搜索引擎?
全文搜索引擎是名副其实的搜索引擎,国外具代表性的有 Google FastAIITheWeb AltaVista Inktomi、 Teoma、 WiseNut等,国内著名的有百度( Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序( Indexer),俗称蜘蛛"( Spider)程序或“机器人”( Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如 Lycos引擎。
1.6.ElasticSearch和Solr比较
-
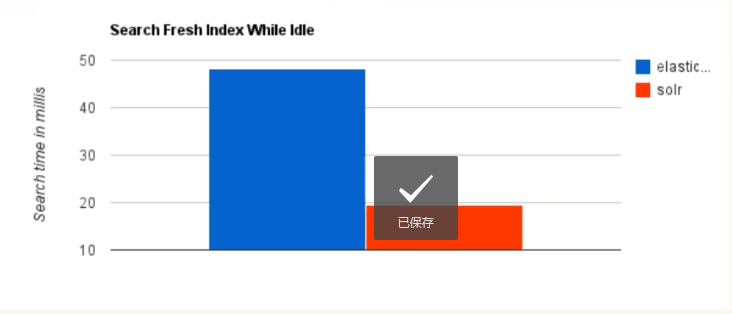
当单纯的对已有数据进行搜索时,Solr更快
-
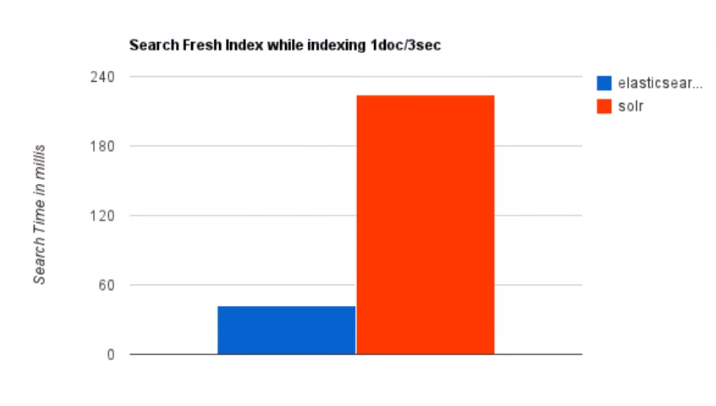
当实时建立索引时,Solr会产生IO阻塞,查询性能较差,ElasticSearch具有明显的优势
-
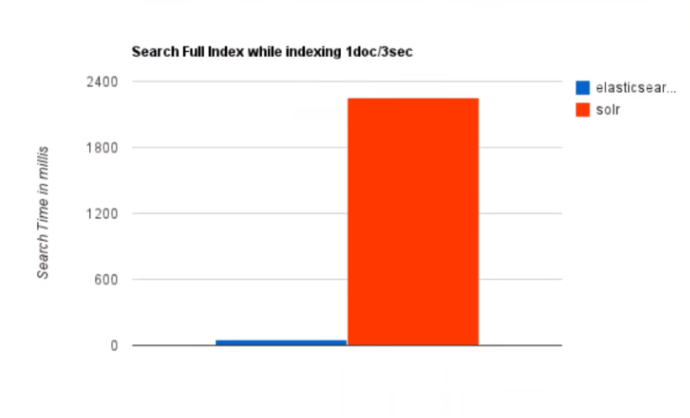
随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化
1.7. ElasticSearch VS Solr 总结
1、es基本是开箱即用(解压就可以用!),非常简单Solr安装略微复杂一丢丢!
2、Solr利用 Zookeeper进行分布式管理,而 Elasticsearch自身带有分布式协调管理功能。
3、Solr支持更多格式的数据,比如SON、XML、CSV,而 Elasticsearch仅支持json文件格式
4、Solr官方提供的功能更多,而 Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑-!
5、Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于 facebook新浪等搜索。
- Solr是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
2.ElasticSearch的安装
下载地址:https://www.elastic.co/cn/downloads/
开箱即用(解压缩即可)
目录熟悉:

启动在bin目录找elasticsearch.bat
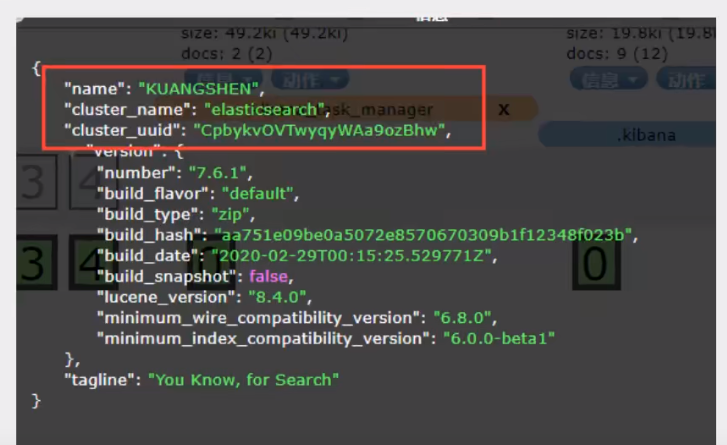
访问http://127.0.0.1:9200/出现下面及成功
{
"name" : "LAPTOP-4SG20D23",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "eiCaEXlhTPCnuEEXpelSdw",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
3.ElasticSearch-Head安装
下载地址:https://github.com/mobz/elasticsearch-head
在Github下载解压包,开箱即用!
下载完毕进入cmd
- 执行npm install下载模块
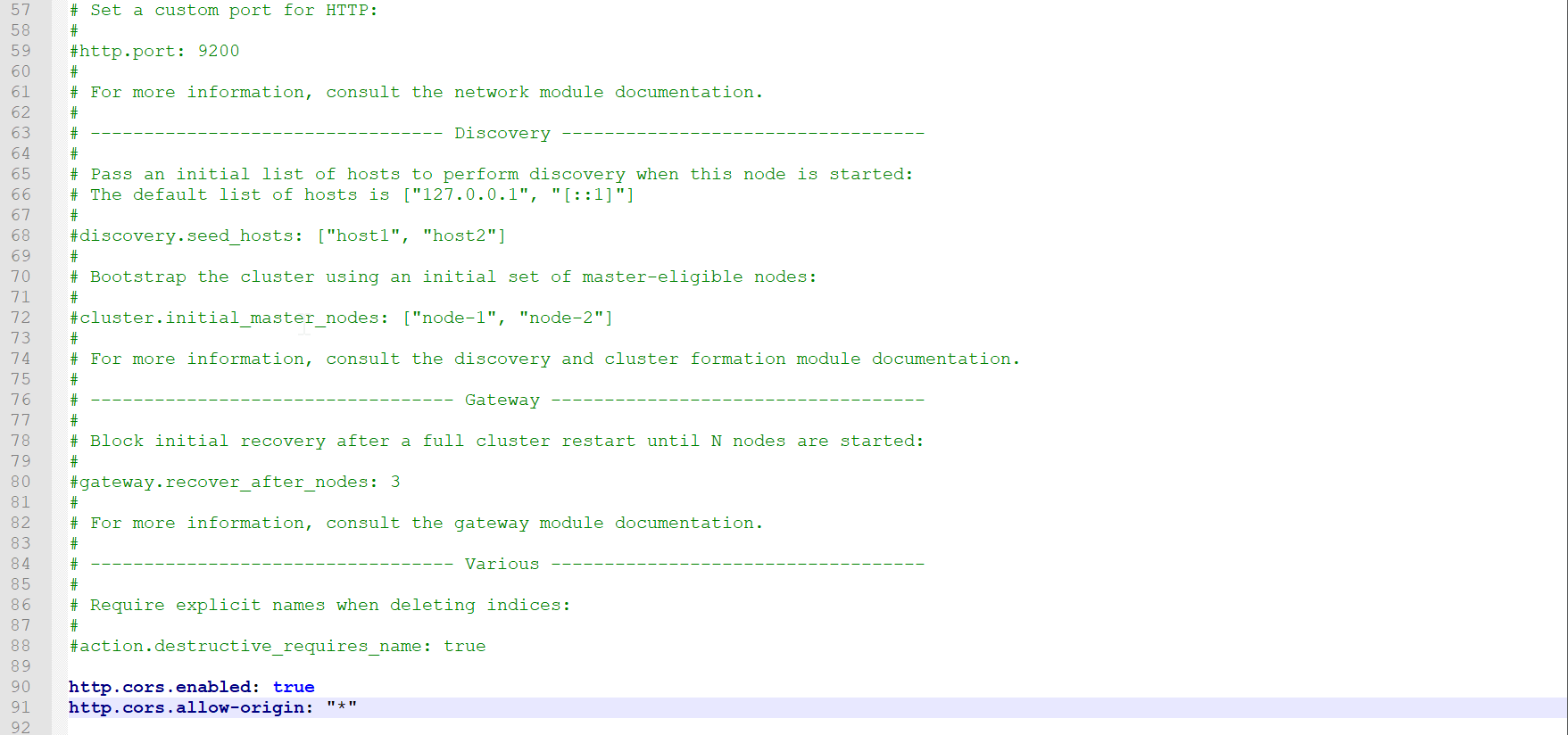
- 这里存在跨域问题,我们需要修改ES->config->elasticsearch.yml文件加上
http.cors.enabled: true
http.cors.allow-origin: "*"
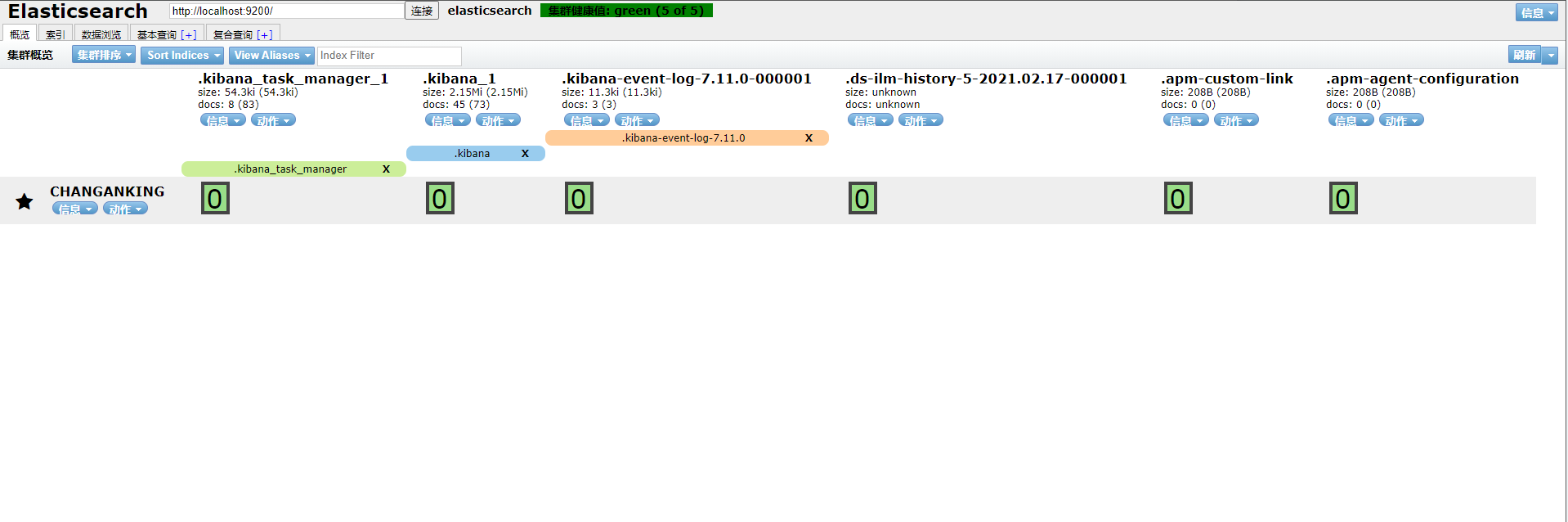
- 运行 npm run start
- 打开 http://localhost:9100/
- 加载完毕
4.Kibana安装
下载地址:https://www.elastic.co/cn/downloads/
开箱即用!
启动在bin目录找kibana.bat
访问 http://localhost:5601
启动起来是英文的,需要国际化的话找到config目录修改 kibana.yml 在后面添加i18n.locale: "zh-CN"
启动成功!
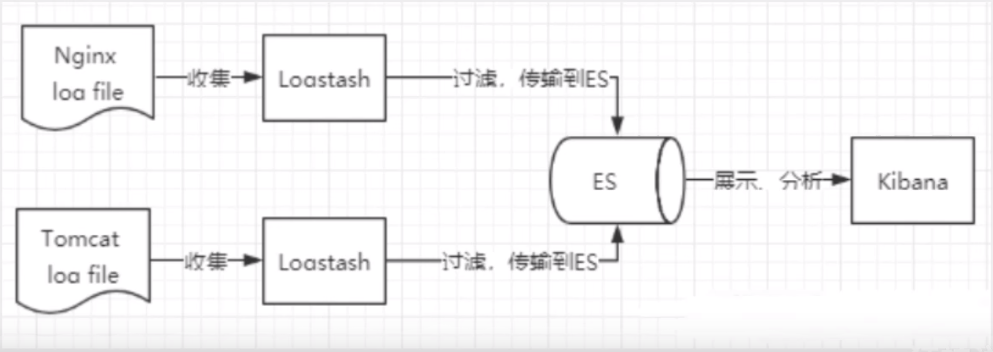
5.了解ELK
ELK是Elasticsearch、 Logstash、 Kibana三大开源框架首字母大写简称。市面上也被成为 Elastic Stack.其中 Elasticsearch是一个基于 Lucene、分布式、通过 Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用 Elasticsearch作为底层支持框架,可见 Elasticsearch提供的搜索能力确实强大市面上很多时候我们简称为es。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/M/redis/elasticsearch/kafka等)。 Kibanaelasticsearch可以将的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性并非唯一性。
6.ElasticSearch核心概念
- 索引(数据库)
- 字段类型(mapping)
- 文档(documents)
6.1.概述
在前面的学习中,我们已经掌握了e是什么,同时也把es的服务已经安装自动,那么心是如何去存储数据,数据结构是什么,那么心是如何去存储数据,数据结构是什么,又是如何实现发现的呢
集群,节点,素引,类型,文档,分片,映时是什么
6.2.elasticsearch是面向文档,关系行数据库和elasticsearch客观的时优!一切都是JSON
easticsearch(集期中可以包含多个素引数据库),每个素引中可以包含多个类型(每),每个类型下又包含多个文档(行),每个文档中义包含多个字段(列)。
6.3.物理设计:
elasticsearch在后台把年个索引划分成多个分片,每份分为可以在集群中的不同服务器间迁移,一个人就是一个集群,默认的集群名称就是elasticsearch。
6.4.逻辑设计:
一个类型中,包含多个文档,比如说文档1,文档2,当我们索引一篇文档时,可以通过这样的一名顺序找到它:索引>类型>文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串。
6.5.文档 (就类似于MySQL中一个表的一条条数据)
之前说elasticsearch是面向文档的,那么意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含keyralue!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!(就是一个JSON对象,FastJson进行转换!)
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
6.6.类型
类型是文档的逻輯容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如ηame映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么 elasticsearch是怎么做的呢?
elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形,但是 elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子
6.7.索引
就是数据库!
索引是腴射类型的容器, elasticsearch中的索引是一个非常大的文档集合,索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
一个集群至少有一个节点,而一个节点就是一个 elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard又称主分片)构成的,每个主分片会有一个副本( replica shard,又称复制分片)
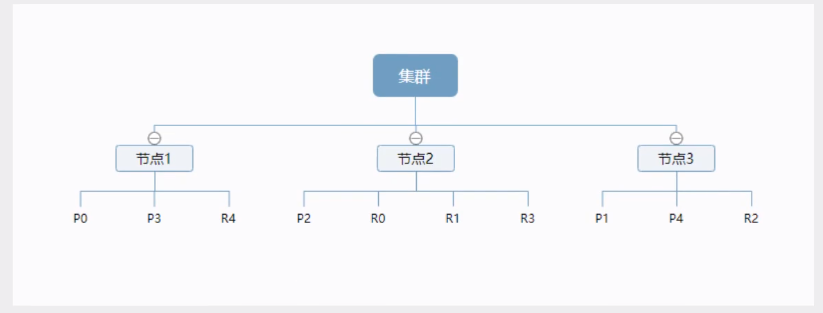
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个 Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得 elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
6.8.倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用 Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
https://blog.csdn.net/andy_wcl/article/details/81631609
例如,现在有两个文档,每个文档包含内容:

为了创建到倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
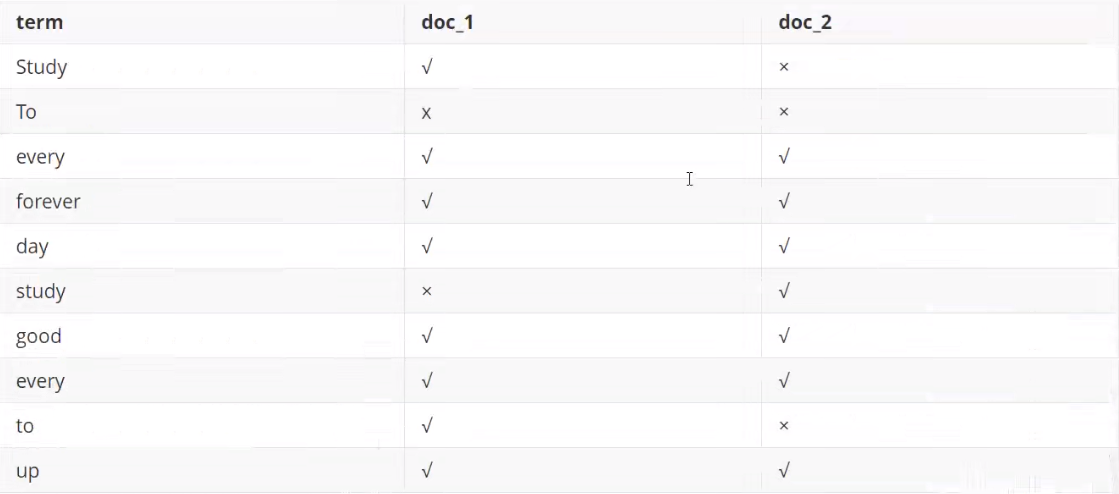
现在,我们试图搜索to forever ,只需要查看包含每个词条的文档score

两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
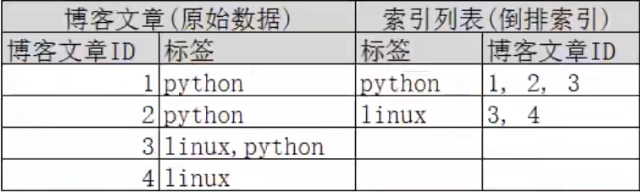
如果要搜索含有 python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章D即可。完全过滤掉无关的所有数据,提高效率!
elasticsearchLucene的索引和的索引对比
在 elasticsearch中,索引(库)个词被频繁使用,这就是术语的使用。在 elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个 elasticsearch索引是由多个索引组成的。别问为什么,谁让 elasticsearchLucene使用作为底层呢!如无特指,说起索引都是指 elasticsearch的索引。
6.9.ik分词器
什么是分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如”我爱江城”会被分为”我”、”爱”、”江”、”城”、这显然是不符合要求的,所以我们需要安装中文分词器来解决这个问题。
iK提供了两个分词算法: ik_smart和 ik_max_word,其中 ik_smart为最少切分, ik_max_word为最细粒度划分!
安装ik分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
下载完毕放到elasticSearch插件中即可!
elasticsearch-7.11.0plugins elasticsearch的插件目录
重启es就发现它加载了插件

elasticsearch-plugin可以直接使用命令来查看加载的插件
使用Kibana测试
- 最小分词器 ik_smart
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
- 最细粒度划分 ik_max_word
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
- 自定义词典
GET _analyze
{
"analyzer": "ik_smart",
"text": "武汉说Java"
}
{
"tokens" : [
{
"token" : "武汉",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "说",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "java",
"start_offset" : 3,
"end_offset" : 7,
"type" : "ENGLISH",
"position" : 1
}
]
}
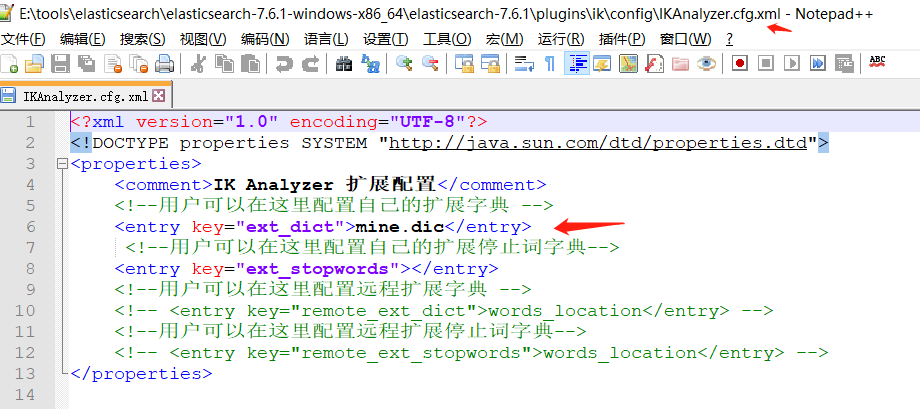
这时候武汉说Java 就被分开了,不是我们要的效果我们需要自己手动加到ik分词器字典中!
打开ik分词器目录config ,创建自己的 mine.dic 配置文件
添加词语 武汉说
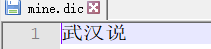
重启es,重新运行
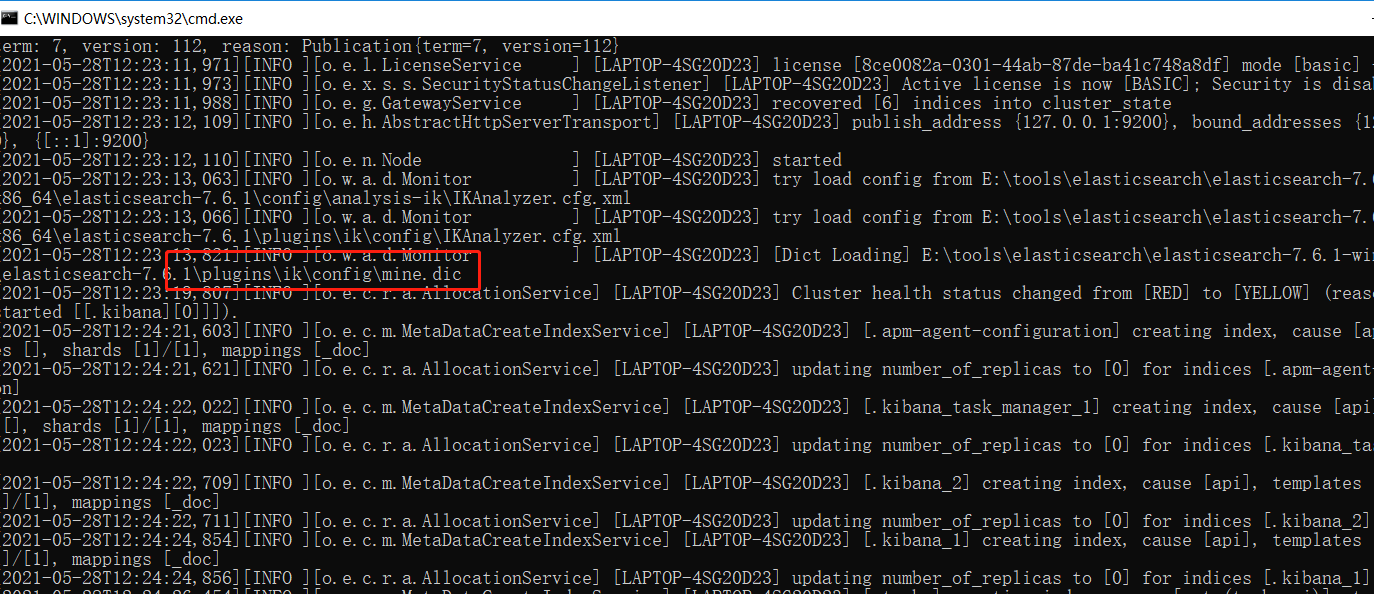
{
"tokens" : [
{
"token" : "武汉说",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "java",
"start_offset" : 3,
"end_offset" : 7,
"type" : "ENGLISH",
"position" : 1
}
]
}
{
"tokens" : [
{
"token" : "武汉说",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "java",
"start_offset" : 3,
"end_offset" : 7,
"type" : "ENGLISH",
"position" : 1
}
]
}
7.REST
7.1什么是REST风格
REST是一种软件架构风格,或者说是一种规范,其强调HTTP应当以资源为中心,并且规范了URI的风格;规范了HTTP请求动作(GET/PUT/POST/DELETE/HEAD/OPTIONS)的使用,具有对应的语义。
资源(Resource):
在REST中,资源可以简单的理解为URI,表示一个网络实体。比如,/users/1/name,对应id=1的用户的属性name。既然资源是URI,就会具有以下特征:名词,代表一个资源;它对应唯一的一个资源,是资源的地址。
表现(Representation):
是资源呈现出来的形式,比如上述URI返回的HTML或JSON,包括HTTP Header等;
REST是一个无状态的架构模式,因为在任何时候都可以由客户端发出请求到服务端,最终返回自己想要的数据,当前请求不会受到上次请求的影响。也就是说,服务端将内部资源发布REST服务,客户端通过URL来定位这些资源并通过HTTP协议来访问它们。
例如:
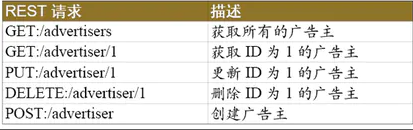
从上图可以看出请求路径相同但请求方式不同,所代表的业务操作也不同,例如,/advertiser/1这个请求,带有GET、PUT、DELETE三种不同的请求方式,对应三种不同的业务操作。
虽然REST看起来还是很简单的,实际上我们往往需要提供一个REST框架,让其实现前后端分离架构,让开发人员将精力集中在业务上,而并非那些具体的技术细节。实际工作中,一般采用基于SSM(Spring+SpringMVC+Mybatis)框架实现REST风格的软件架构。
7.2基本Rest命令说明