答案:主要是为了提升同级的比较效率的。
借用我在博客上另外一篇 Vue 2 渲染过程的图
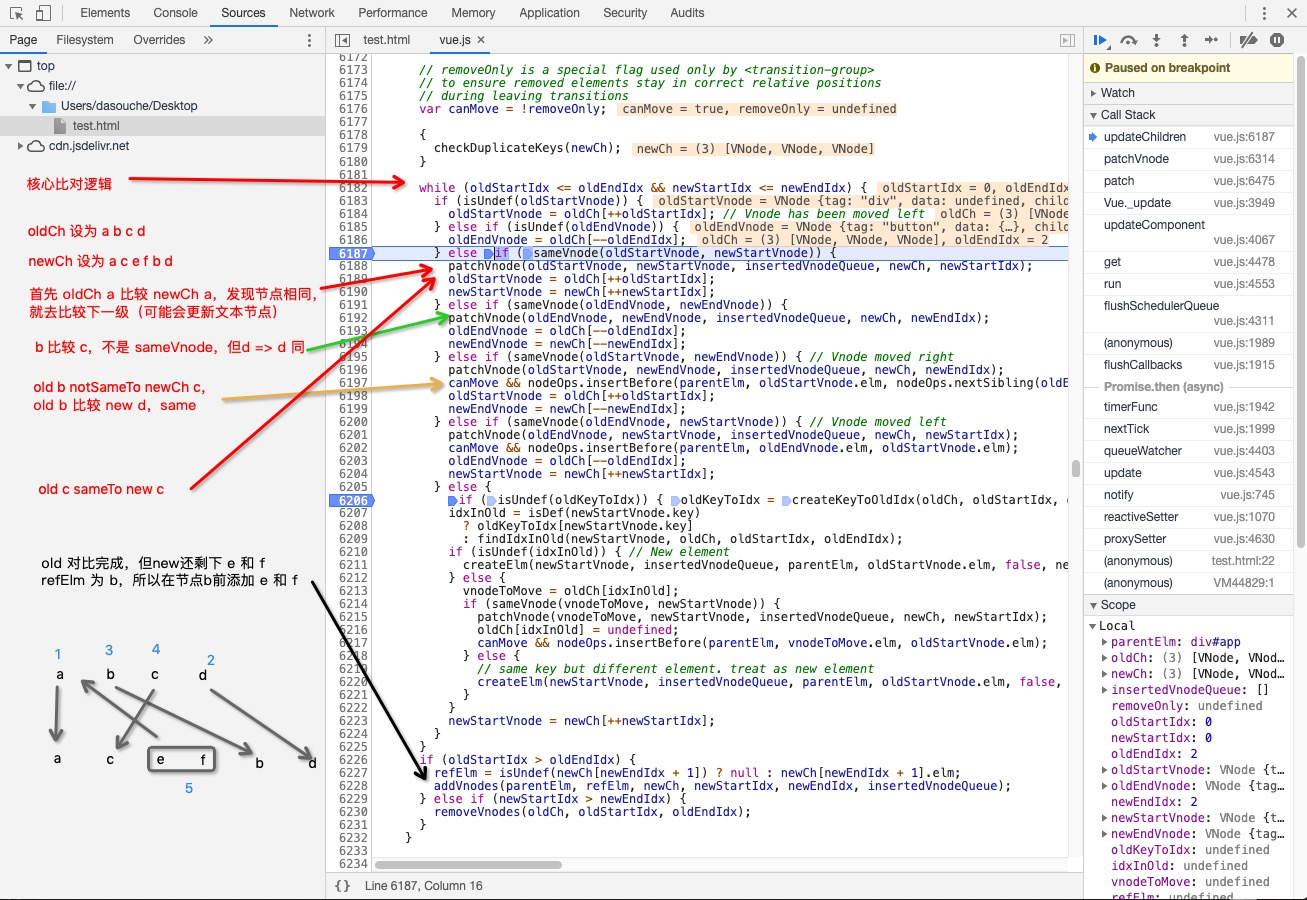
其中核心比对逻辑就是新老节点头对头,头对尾,尾对头,尾对尾,都判定非 sameVnode,则拿着 key 去比对,若其中有被判定为 sameVnode,则复用节点。反之需要删除后再添加新节点。
function sameVnode(a, b) {
// key,tag,isComment相同,并且data都不为空,并且节点类型不是input
return (
a.key === b.key && (
(
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
) || (
isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)
)
)
)
}
那么有个问题,能复用节点一定就快吗?不一定,设你需要渲染 10w 条列表数据
<li v-for="item in list" :key="item.id">{{ item.name }}</li>
list = [
{
id: 1,
name: 1
},
......
{
id: 100000,
name: 100000
}
]
若不写 key,新老节点的 key 都是 undefined 相同。tag ,isComment相同,且 data 不为空。那li 节点也都被判定为 sameVnode,只需要迭代替换文本节点就可以了。
但若写了 key,新老节点部分 key 不相同。判定为 sameVnode 的部分照样去替换文本节点,然而 key 不相同的部分还得创建/删除 DOM 节点,花销自然比不写 key 大。
但这种场景只适用于简单的无状态组件,vue 还是推荐使用 key,这是因为开发中遇到的大多数场景,都有自己的状态。