1.创建数据库
CREATE DATABASE database_name
2.删除数据库
DROP DATABASE database_name
3.选择数据库
USE database_name
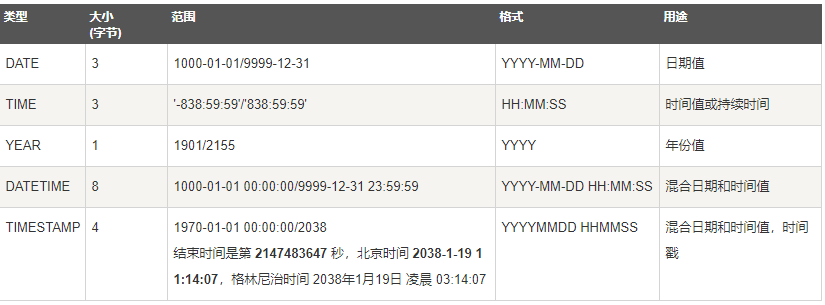
4.数据类型
(1)数值类型

(2)日期和时间类型
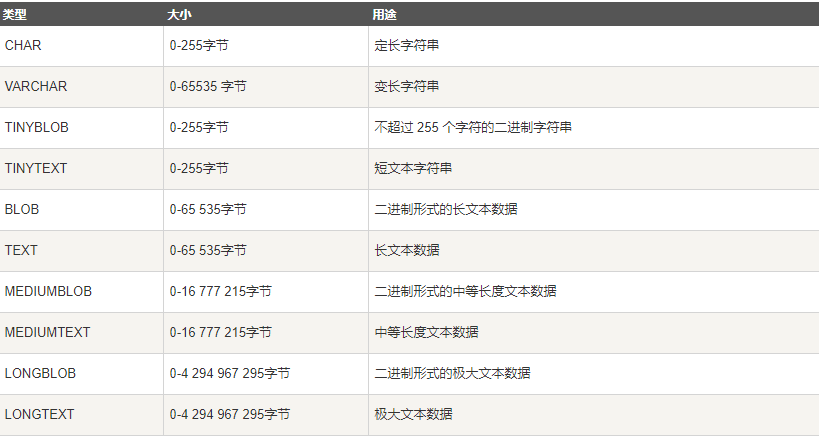
(3)字符串类型
5.创建数据表
CREATE TABLE table_name (column_name column_type)
6.删除数据表
DROP TABLE table_name
7.更新数据表信息
(1)添加表字段
ALTER TABLE table_name ADD new_column DATATYPE
使用FIRST关键字可以将新增列的顺序调整至数据表的第一列
ALTER TABLE table_name ADD new_column DATATYPE FIRST
使用AFTER关键字可以将新增列调整至数据表的指定列之后
ALTER TABLE table_name ADD new_column DATATYPE AFTER old_column
(2)删除表字段
ALTER TABLE table_name DROP old_column
(3)修改表字段类型
ALTER TABLE table_name MODIFY column_name NEW_DATATYPE
(4)修改字段名称
ALTER TABLE table_name CHANGE old_column_name new_column_name DATATYPE
8.插入数据
INSERT INTO table_name (column1, column2,column3...columnN)
VALUES
(value1, value2, value3...valueN);
9.查询数据
SELECT column1, column2, column3...columnN FROM table_name
(1)使用*可以替代字段名,SELECT语句会返回表的所有字段
例:SELECT * FROM table_name
(2)可以使用WHERE语句来包含任何条件
例:SELECT * FROM table_name WHERE column=1
(3)可以使用LIMIT属性设定返回的记录数
例:返回查询结果的前三条记录
SELECT * FROM table_name LIMIT 3
例:返回查询结果的第三条记录
SELECT * FROM table_name LIMIT 2,1 (2指的是第几条数据(从0开始计数),1指的是从2开始返回几条数据)
(4)可以使用OFFSET指定开始查询的偏移量,默认情况下偏移量为0
例:SELECT * FROM table_name LIMIT 2 OFFSET 3 等于 SELECT * FROM table_name LIMIT 2,3
10.更新数据
UPDATE table_name SET column1=value1, column2=value2
WHERE condition
11.删除数据
DELECE FROM table_name
WHERE condition
12.LIKE子句
LIKE子句中使用%号来表示任意字符,其的效果类似正则表达式中的*,如果没有使用%,那么LIKE的效果等价于=
SELECT * FROM table_name
WHERE column1 LIKE %condtion%
13.UNION
SELECT column1, column2, column3...columnN FROM table_a
[WHERE condition]
UNION [ALL | DISTINCT]
SELECT column1, column2, column3...columnN FROM table_b
[WHERE condition]
UNION的作用的连接两个查询结果集
DISTINCT的作用是对两个结果集进行去重处理,默认情况下已经是DISTINCT的结果了
ALL的作用的不对两个结果集进行去重处理
14.ORDER BY
SELECT * FROM table_name
ORDER BY column1 [ASC | DESC]
ASC:将结果集按column1升序排列,默认情况下使用升序排序
DESC:将结果集按column1降序排列
15.GROUP BY
把数据按照指定列(可以是一列或者多列)进行分组,通常和计算函数COUNT()还有SUM(),AVG()等求值函数一起使用
例:根据column1将数据进行分组,并且统计每种数据的记录数
SELECT column1, COUNT(*) FROM table_name
GROUP BY column1
WITH ROLLUP可以将GROUP BY的统计结果集基础上再做相同的统计(SUM,AVG....)
例:假设有下面这样一张表 name=姓名,website=网站,access_count=访问记录
| name | website | access_count |
| 张三 | 百度 | 3 |
| 李四 | 新浪 | 5 |
| 王五 | 淘宝 | 4 |
| 张三 | 新浪 | 2 |
| 李四 | 百度 | 1 |
| 王五 | 搜狐 | 4 |
| 赵六 | 搜狐 | 5 |
执行如下代码:
SELECT name, SUM(access_count) FROM table_name
GROUP BY name WITH ROLLUP
得到:
| name | SUM(access_count) |
| 张三 | 5 |
| 李四 | 6 |
| 王五 | 8 |
| 赵六 | 5 |
| NULL | 24 |
16.INNER JOIN
INNER JOIN被称为内连接或者等值连接,获取两个表中字段匹配关系的记录
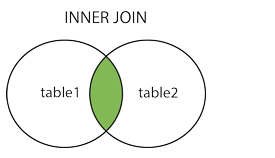
例:SELECT table1.column1, table1.column1, table2.column3 FROM table1
INNER JOIN table2
ON condition
17.LEFT JOIN
LEFT JOIN被称为左连接,获取左边所有记录,右表没有的记录补为NULL
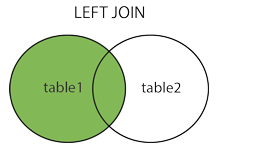
例:SELECT table1.column1, table1.column2, table2.column3 FROM table1
LEFT JOIN table2
ON condition
18.RIGHT JOIN
RIGHT JOIN被称为右连接,获取右边所有数据,左表没有的记录补为NULL

例:SELECT table1.column1, table2.column2, table2.column3 FROM table1
RIGHT JOIN table2
ON condition