前言
传统的RDD相对于mapreduce和storm提供了丰富强大的算子。在spark慢慢步入DataFrame到DataSet的今天,在算子的类型基本不变的情况下,这两个数据集提供了更为强大的的功能。但也有些功能暂时无法使用。比如reduceByKey,在DataFrame和DataSet里是没有的。所以觉得有必要做一些梳理。
准备工作
测试数据,json格式:
{ "DEVICENAME": "test1", "LID": 170501310, "ADDRESS": "xxxx", "ID": 230001160 }
{ "DEVICENAME": "test2", "LID": 170501311, "ADDRESS": "xxxx", "ID": 230001161 }
{ "DEVICENAME": "test3", "LID": 170501310, "ADDRESS": "xxxx", "ID": 230001160 }
{ "DEVICENAME": "test4", "LID": 170501310, "ADDRESS": "xxxx", "ID": 230001160 }
{ "DEVICENAME": "test5", "LID": 170501310, "ADDRESS": "xxxx", "ID": 230001160 }
分别转化为DataFrame和DataSet,然后结合spark 算子之RDD一文中所罗列的主要算子,进行一一对比。
val session = SparkSession .builder() .appName("test") .master("local[*]") .getOrCreate() import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] df.show() ds.show() df.printSchema() ds.printSchema()
//
val path: String = "D:/test.txt";
case class data(DEVICENAME: String, LID: BigInt, ADDRESS: String, ID: BigInt)
得到的数据:
+-------+----------+---------+---------+
|ADDRESS|DEVICENAME| ID| LID|
+-------+----------+---------+---------+
| xxxx| test1|230001160|170501310|
| xxxx| test2|230001161|170501311|
| xxxx| test3|230001160|170501310|
| xxxx| test4|230001160|170501310|
| xxxx| test5|230001160|170501310|
+-------+----------+---------+---------+
结构:
root
|-- ADDRESS: string (nullable = true)
|-- DEVICENAME: string (nullable = true)
|-- ID: long (nullable = true)
|-- LID: long (nullable = true)
算子对比
filter
相比于RDD的filter算子,df和ds均提供了针对属性,表达式,自定义函数等过滤表达式。还提供了基本等价于filter的where算子。
def filter(session: SparkSession) { import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] df.filter(_.getLong(2) > 0).show() df.filter($"ID" > 0).show() df.filter("DEVICENAME == 'test1'").show() df.where("ID > 230001160").show() df.where($"ID" > 230001160).show() df.filter($"ID" > 0 || $"ID" < 0) ds.filter(_.ID > 0).show() ds.filter($"ID" > 0 || $"ID" > 0).show() ds.filter("DEVICENAME == 'test1'").show() ds.where("ID > 230001160").show() ds.filter(x => { x.ID > 230001160 && x.LID > 170501311 }).show() }
针对虚拟列的过滤,类似于having,但必须是计算完成的列:
df.groupBy("ID").filter($"avg(ID)" > 0).show()//编译不通过
df.groupBy("ID").avg("LID").filter($"avg(ID)" > 0).show()//错误
df.groupBy("ID").avg("ID").filter($"avg(ID)" > 0).show()
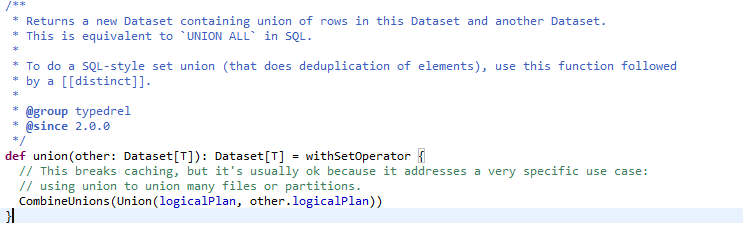
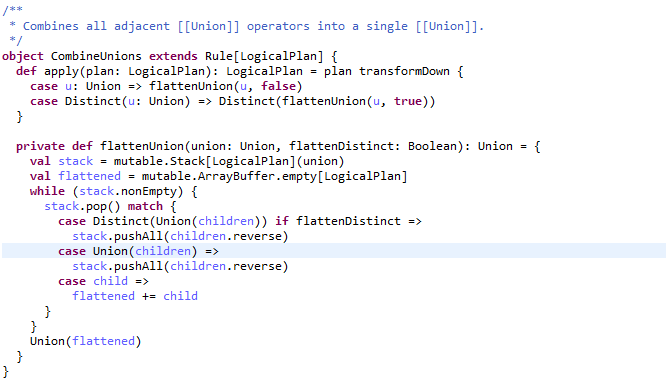
union
使用上并没有区别 。但ds和df的union算子有所优化,效率更高。RDD直接将两个RDD相加。而ds和df则中间调用了CombineUnions函数,关键字combine,Combines all adjacent [[Union]] operators into a single [[Union]].先将邻近的分区合并,避免多余的网络传输。
intersect except
求 交集 差集
rdd intersection subtract
df/ds intersect except
import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] val df2 = df.filter($"ID" > 230001160) df.intersect(df2).show() println("===================") df.except(df2).show()
结果:
+-------+----------+---------+---------+
|ADDRESS|DEVICENAME| ID| LID|
+-------+----------+---------+---------+
| xxxx| test2|230001161|170501311|===================
+-------+----------+---------+---------+
|ADDRESS|DEVICENAME| ID| LID|
+-------+----------+---------+---------+
| xxxx| test3|230001160|170501310|
| xxxx| test1|230001160|170501310|
| xxxx| test5|230001160|170501310|
| xxxx| test4|230001160|170501310|
+-------+----------+---------+---------+
distinct dropDuplicates
去重。df/ds提供了新的去重算子dropDuplicates。传统的distinct 只能对元素全量去重,dropDuplicates可以针对元素的某一个或者多个属性进行去重。
import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] df.distinct().show() df.dropDuplicates().show() val array = Array("ID","LID") val seq = Seq("ID","LID") df.dropDuplicates("ID","LID").show() df.dropDuplicates(array).show() df.dropDuplicates(seq).show()
select selectExpr drop
选择器。select可以选择某列或某几列,selectExpr 可以使用条件表达式选择某列或某几列。drop 可以选择屏蔽某列或某几列。
import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] df.drop("ID").show()//删掉ID这一列 df.select("ID", "ADDRESS").show()//选择ID,ADDRESS df.select($"ID", $"ADDRESS",$"ADDRESS" as "NEWNAME").show()//将ADDRESS重命名 ds.select($"ID", $"ID" + 1 as "NEWNAME").show()//将ID进行计算并重命名 ds.selectExpr("ID", "ID + 1 as NEWNAME","abs(ID - 230001165)").show()
withColumn withColumnRenamed
withColumn新增一个列,但是有一个局限性,是当前df/ds中,且存在的列。既然是新增列,当然列名不能相同。
withColumnRenamed 相当于重命名。
两个功能都显得有些鸡肋。
import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] val rowDF = session.sparkContext.parallelize(1 to df.count().toInt).toDF("ID") df.withColumn("ID",df("ID") + 1).show()//名字相同,等于只做+1操作 df.withColumn("ID2",df("ID")).show()//值相同,列名不同,新增一列 df.withColumn("ID3",df("ID")+1).show()//值相同,列名不同,新增一列 df.withColumn("ID",rowDF("ID")).show()//报错 df.withColumnRenamed("ID", "NEWID").show()
groupBy
groupBy与RDD的groupBy区别较大。前面讲到,groupBy对(K,V)对的RDD经过处理后,变成 [key,{key:value1,key:value2}]。而df/ds经过groupBy操作后,变成了RelationalGroupedDataset对象。必须经过后续操作,才能继续使用。后续操作具体主是聚合函数。
groupBy本意就是分组,那么分组过后进行聚合显得当然是合情合理。
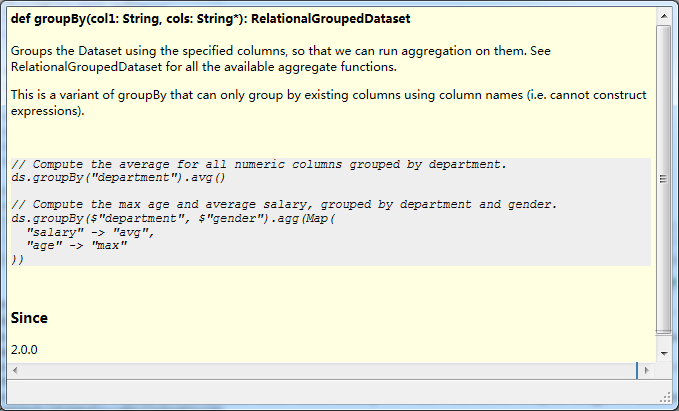
如图所示,官方提供了两种方式。第一种是单个的聚合函数。第二种是多个聚合函数。
import session.implicits._ val df = session.read.json(path) val ds = session.read.json(path).as[data] df.groupBy("LID").avg("ID").show()// select LID,AVG(ID) FROM TABLE 单个函数单个字段 df.groupBy("LID").avg("ID","LID").show()//单个函数多个字段 //其它聚合函数 df.groupBy("LID").avg("ID").show() //平均值 df.groupBy("LID").mean("ID").show()//平均值 df.groupBy("LID").max("ID").show() df.groupBy("LID").count().show() df.groupBy("LID").min("ID").show() df.groupBy("LID").sum("ID").show() //多个聚合函数 df.groupBy("LID").agg(Map( "LID" -> "max", "ID" -> "avg")).show()
聚合函数都是一些常规的东西,跟关系型数据聚合函数差不多。需要注意的是,求平均值,提供了两个函数:avg和mean,从源码上来看,功能是一样的。还有一个比较特殊的函数是pivot。
这个函数感觉是为报表而生。它可以将列值作为列名在横坐标上展示。在一定程度上,使报表展示更加清晰。
展示一个具体的例子:
测试数据:
城市 销售额 人数 月份
{ "city": "重庆", "sales": 170501, "nums": 10,"month":1}
{ "city": "四川", "sales": 170501, "nums": 12,"month":1}
{ "city": "重庆", "sales": 170502, "nums": 13,"month":2}
{ "city": "重庆", "sales": 170504, "nums": 9,"month":3}
{ "city": "四川", "sales": 170505, "nums": 20,"month":2}
{ "city": "四川", "sales": 170506, "nums": 20,"month":3}
背景需求:求每个城市每个月的平均销售额。
实现方式:
1 传统方式 SELECT city,month,avg(sales) sales FROM TABLE GROUP BY city,month
import session.implicits._ val df = session.read.json("D:/test2.txt").as[test] df.groupBy("city","month").avg("sales").show() case class test(city:String, sales:Long,nums:BigInt,month:BigInt)
显示结果:
+-----+-----+----------+
| city|month|avg(sales)|
+-----+-----+----------+
| 四川| 2 | 170505.0|
| 重庆| 3 | 170504.0|
| 四川| 1 | 170501.0|
| 四川| 3 | 170506.0|
| 重庆| 1 | 170501.0|
| 重庆| 2 | 170502.0|
+-----+-----+----------+
2
df.groupBy("city").pivot("month").avg("sales").show()
显示结果:
+-----+--------+--------+--------+
| city | 1 | 2 | 3 |
+-----+--------+--------+--------+
| 重庆|170501.0|170502.0|170504.0|
| 四川|170501.0|170505.0|170506.0|
+-----+--------+--------+--------+
当然,还可以选择哪些值作为列展示
df.groupBy("city").pivot("month", Seq("1","2")).avg("sales").show()
目前尚不支持类似excel一样的两种以上的表头。两种展示方式,孰优孰劣,不置评述。但至少提供了另一种选择。
orderBy sort
df/df已经摒弃了sortBykey等函数。两者有什么区别呢?没有区别。
** * Returns a new Dataset sorted by the given expressions. * This is an alias of the `sort` function. * * @group typedrel * @since 2.0.0 */ @scala.annotation.varargs def orderBy(sortExprs: Column*): Dataset[T] = sort(sortExprs : _*)
df.groupBy("ID").agg(Map("ID" -> "max", "LID" -> "avg","ADDRESS" -> "max")).orderBy($"ID".desc).show()
df.groupBy("ID").agg(Map("ID" -> "max", "LID" -> "avg","ADDRESS" -> "max")).sort($"ID".desc).show()
cube rollup
类似于的groupby。
cube是做幂集操作。维基百科上对幂集的解释。包括空集
Example[edit]
If S is the set {x, y, z}, then the subsets of S are
- {} (also denoted {displaystyle varnothing }
or {displaystyle emptyset }
, the empty set or the null set)
- {x}
- {y}
- {z}
- {x, y}
- {x, z}
- {y, z}
- {x, y, z}
and hence the power set of S is {{}, {x}, {y}, {z}, {x, y}, {x, z}, {y, z}, {x, y, z}}.
df.cube("ID", "LID")
session.sql("select ID,LID FROM TABLE group by ID,LID with cube").show()
//GROUP BY ID,LID
//GROUP BY LID,ID
//GROUP BY LID
//GROUP BY ID
rollup,包括空集
df.cube("ID", "LID")
session.sql("select ID,LID FROM TABLE group by ID,LID with rollup").show()
//GROUP BY ID,LID
//GROUP BY ID
stat
科学和数学函数
join
相比RDD,df/ds的join算子增加了连接条件。
val df = session.read.json(path) val ds = session.read.json(path).as[data] val df2 = session.read.json("").as[data] //两张表关联字段名相同的情况下 // df.join(df2,"LID").show() //两张表关联字段名不相同的情况下 // df2.join(df,df2("LID2") === df("LID")).show() // df2.join(df,df2("LID2") === df("LID") && df2("ID") === df("ID")).show() df2.join(df,Seq("LID","ID"),"inner").show()