起因
临下班,偶然看到阿里巴巴《JAVA开发手册》中,关于整型包装类对象之间值的比较的规约,里面提到强制使用equals,而不使用==。原因众所周知,在-128 至 127,Integer 对象是在 IntegerCache.cache 产生。
所以很多人会在代码里使用去进行-128 至 127之间的数值比较。特别是一些常量,如state,status这类的常量,值通常都在100以内进行定义。感觉上是没有问题。阿里的《JAVA开发手册》里面也提到了“**这个区间内的 Integer 值可以直接使用进行判断**”。

但是,搞大数据的同学请注意了!
大数据天然是分布式的,比如spark,每个executor执行器哪怕在同一个服务器节点上,也会申请一个单独的JVM,所以,这个时候定义一个Integer哪怕是落在-128 至 127范围以内,通过“==”能得到想要的效果吗?
都在不同的JVM了,内存地址当然不一样了,所以答案很显然是否定的。
动机
鉴于阿里巴巴的影响力,它的《JAVA开发手册》读者还有众多的。所以,觉得有必要提醒出这一点。
1.在大数据分布式情况下,对于 Integer var = ? 在-128 至 127 之间的赋值,不可以直接使用==进行判断。
2.不管是单机程序还是分布式程序,一律使用equals进行数值比较,或者使用基础数据类型。
验证
测试代码:
public class Constants {
public static final Integer STATE = 1;
}
int state = 1;
Integer state1 = 1;
Integer state2 = new Integer(1);
Integer state3 = Integer.valueOf(1);
SparkSession session = SparkSession.builder().appName("Validate").getOrCreate();
Long count = session.read().limf("/patt").select("vin").map(new MapFunction<Row, String>() {
@Override
public String call(Row value) throws Exception {
System.out.println("1 hashcode :" + System.identityHashCode(state1)+" 2:"+System.identityHashCode(state2)+" 3:"+System.identityHashCode(state3)+" constant = " + System.identityHashCode(Constants.STATE.hashCode()));
System.out.println((state == Constants.STATE) + " 1:" + (state1 == Constants.STATE) + " 2:" + (state2 == Constants.STATE) + " 3:" + (state3 == Constants.STATE));
Thread.sleep(100000);
return value.mkString();
}
}, Encoders.STRING()).count();
在不同的task打印出来的日志:

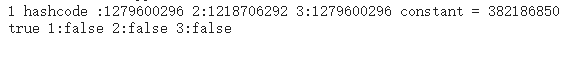
可以看到,用了Integer包装类的分布式内部比较使用“==”得不到预期值。
总结
Integer state1= 1;
Integer state2 = 1;
单机模式下state1 == state2为ture
但是上面模式下,state1和state2分属两个JVM,返回false,这种情况比较容易忽略和误用。
处理
已在github提出问题
https://github.com/alibaba/p3c/issues/863