structed streaming的执行批次,较spark streaming有所改变。更加灵活。总结下来,可大白话地分为三类:
1尽可能快的执行,不定时间
2按固定间隔时间执行
3仅执行一次
详情如下:
| Trigger类型 | 使用 | 注意 |
|---|---|---|
| unspecified (default) | as soon as micro-batch | If no trigger setting is explicitly specified, then by default, the query will be executed in micro-batch mode, where micro-batches will be generated as soon as the previous micro-batch has completed processing.如果不设置,默认使用微批,但没有时间间隔,尽可能快的处理 |
| Interval micro-batch(固定间隔的微批) | Trigger.ProcessingTime(long interval, TimeUnit timeUnit) | 根据数据实际情况,不定时批次1. 没有明确指明触发器时,默认使用该触发器,即Trigger.ProcessingTime(0L), 表示将尽可能快地执行查询。2. 该模式下,将按用户指定的时间间隔启动微批处理。3. 如果前一个微批在该间隔内完成,则引擎将等待该间隔结束,然后再开始下一个微批处理。4. 如果前一个微批花费的时间比间隔要长,下一个微批将在前一个微批处理完成后立即开始。5. 如果没有新数据可用,则不会启动微批处理。 |
| One-time micro-batch (一次性微批) | Trigger.Once() | 仅执行一次 |
| Continuous with fixed checkpoint interval(连续处理) | Trigger.Continuous(long interval, TimeUnit timeUnit) | 以固定的Checkpoint间隔(interval)连续处理。在这种模式下,连续处理引擎将每隔一定的间隔(interval)做一次checkpoint,可获得低至1ms的延迟。但只保证 at-least-once |
为什么continuous只支持at-least-once
df.writeStream
.format("console")
.trigger(continuous='1 second')
.start()
注意这里的 1 second 指的是每隔 1 秒记录保存一次状态,而不是说每隔 1 秒才处理数据
continuous 不再是周期性启动 task,而是启动长期运行的 task,也不再是处理一批数据,而是不断地一个数据一个数据地处理,并且也不用每次都记录偏移,而是异步地,周期性的记录状态,这样就能实现低延迟.
综上,continuous模式下长期运行一个task,而不会实时去记录offset,所以不能保证eactly-once.
三种批次方式的验证
1.Interval micro-batch(固定间隔的微批)
`{
Logger.getRootLogger().setLevel(Level.ERROR);
Logger.getLogger(StructuredSparing.class).setLevel(Level.ERROR);
SparkSession session = SparkSession
.builder()
.master("local")
.config("spark.sql.streaming.checkpointLocation", "D://checkpoint")
.getOrCreate();
Dataset<Row> stream = session.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test")
.load();
StreamingQuery query = stream.writeStream()
.queryName("StructuredSparingTest")
.format("console")
.trigger(Trigger.ProcessingTime(5, TimeUnit.SECONDS))
.start();
try {
query.awaitTermination();
} catch (StreamingQueryException e) {
e.printStackTrace();
}
}`
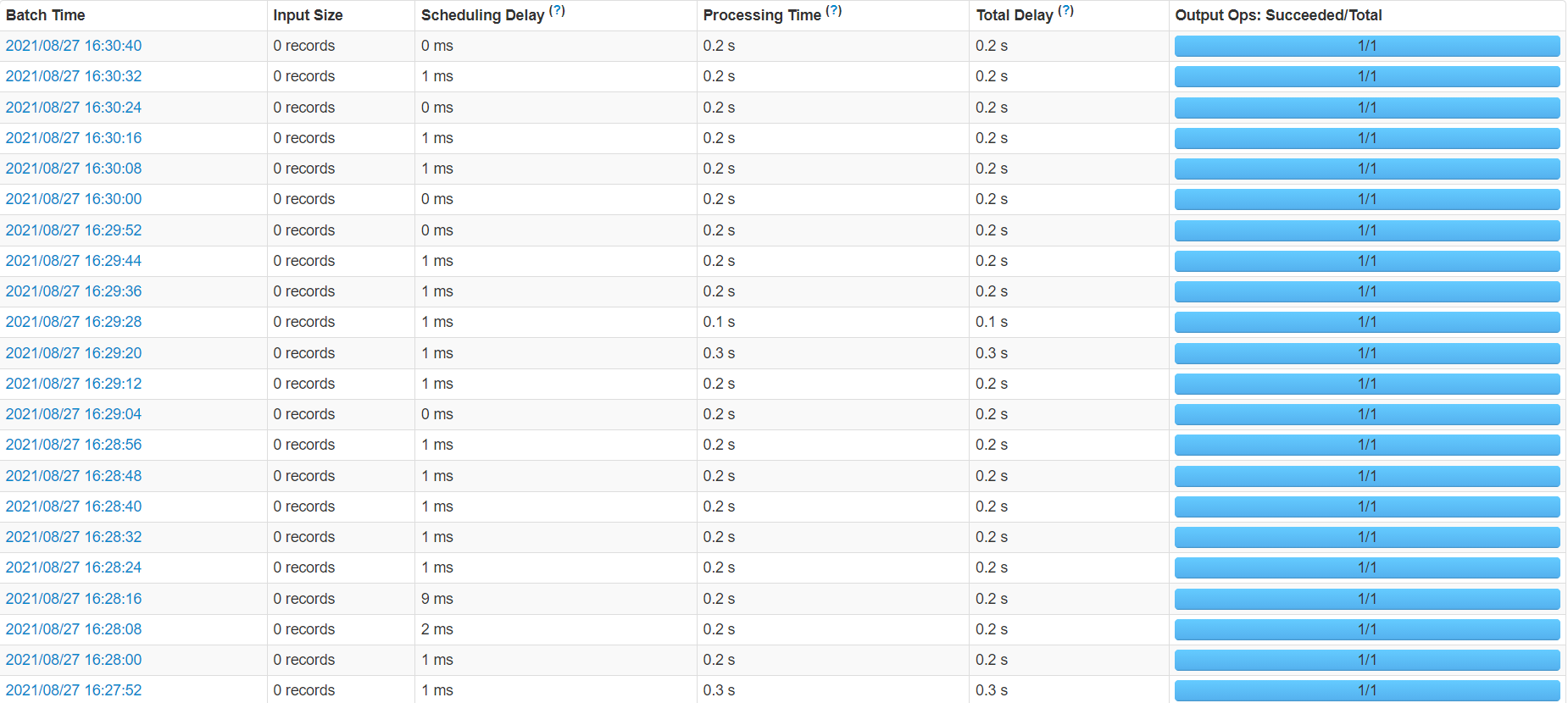
设置为5秒一个批次。
通过UI界面可以很直观地看出,在有数据的时候5秒一个批次,在没有数据的时候,10秒甚至3分钟才执行一个批次。
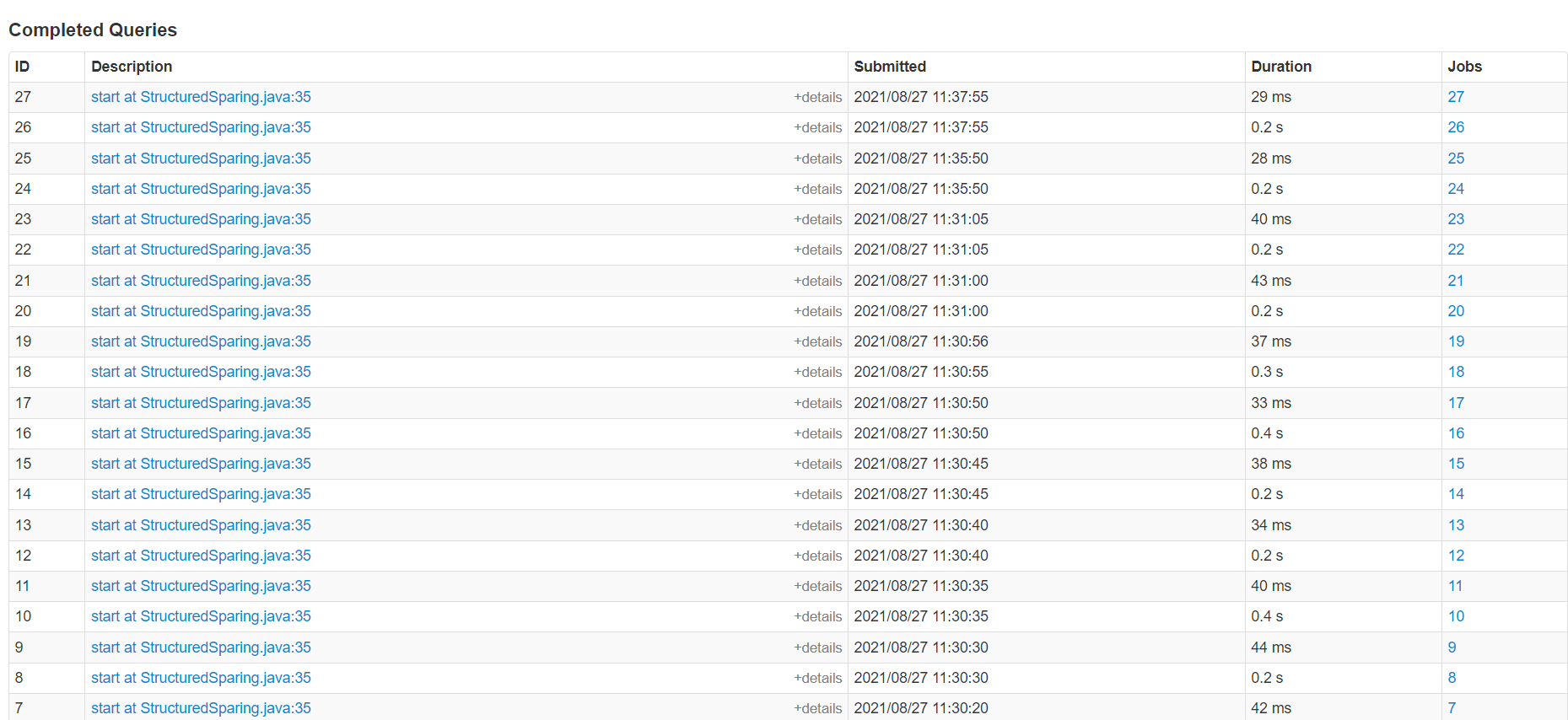
通过与spark streaming进行比较可以更加直观.在spark streaming里设置8秒一个批次,在UI界面可以看到,不管有无数据,spark streaming严格按照8秒的批次执行。
2.One-time micro-batch (一次性微批)
.trigger(Trigger.Once())
执行结果,略。
3.Continuous方式
.trigger(Trigger.Continuous(100,TimeUnit.MILLISECONDS))
设置100毫秒一个执行批次,通过UI界面可以看出,时间已经1.2分钟,但是active job一直只有一个,一直在running,证明启动了一个长期运行的task,不断地一批数据一批数据连续处理。
