一、好友推荐算法在实际的社交环境中应用较多,比如qq软件中的“你可能认识的好友”或者是Facebook中的好友推介。常见的好友推介算法有六度分割理论,三元闭包论和最基本的好友推介算法。
学习和分享好友推介算法。
假设用户A有好友A1,A2,A3,则A1,A2,A3相互之间都可能通过好友A认识,是潜在的好友关系。如果用户B有好友A1,A2,B1,则A1,A2,B1相互之间都可能通过好友B认识。如下图所示
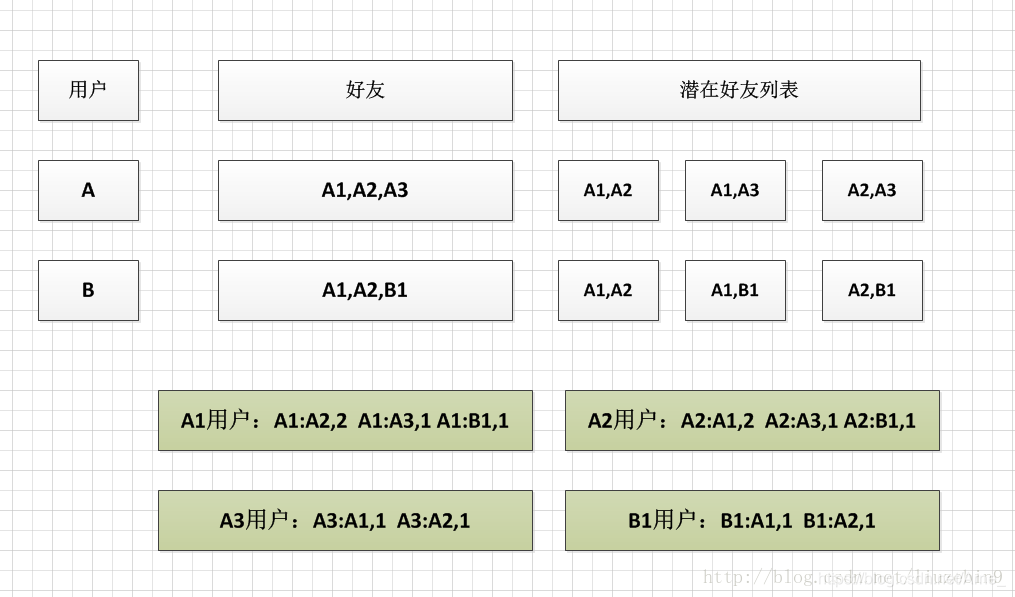
如上图所示,A1,A2在潜在好友列表中出现2次,说明A1,A2有2个共同好友,在上图中即为A,B。当两个潜在好友如果共同好友越多,则他们可能认识的可能性就越大,彼此之间推介机会就越高。算法简单介绍如下:首先需要遍历所有用户的好友列表生成两两间的潜在好友列表,计算所有用户潜在好友列表中同一对潜在好友出现的次数。如上图例子中A1,A2出现次数为2次。注意:A1:A2与A2:A1为相同的一对潜在好友,计算时应进行累加。再次计算同一个用户的潜在好友列表和出现的次数,如图中A1用户,A1与A2出现2次,A1与A3出现1次,A1与B1出现1次。如果只能给每个用户推介一个好友的话,A2与A1认识的可能性更大,优先推介A2。注意:还需要除去已经是该用户好友的潜在好友列表。如果A1与A2已经是好友关系了,则不需要再次推介。
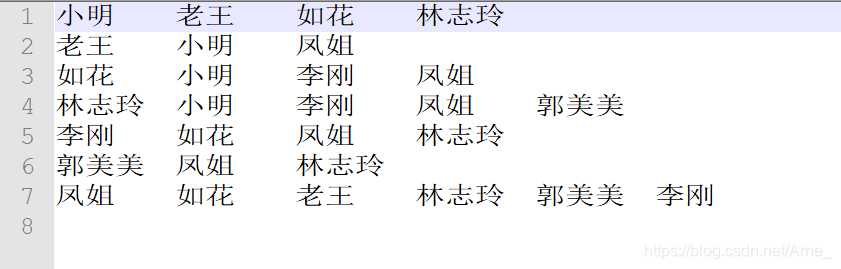
实验数据:
数据流程:
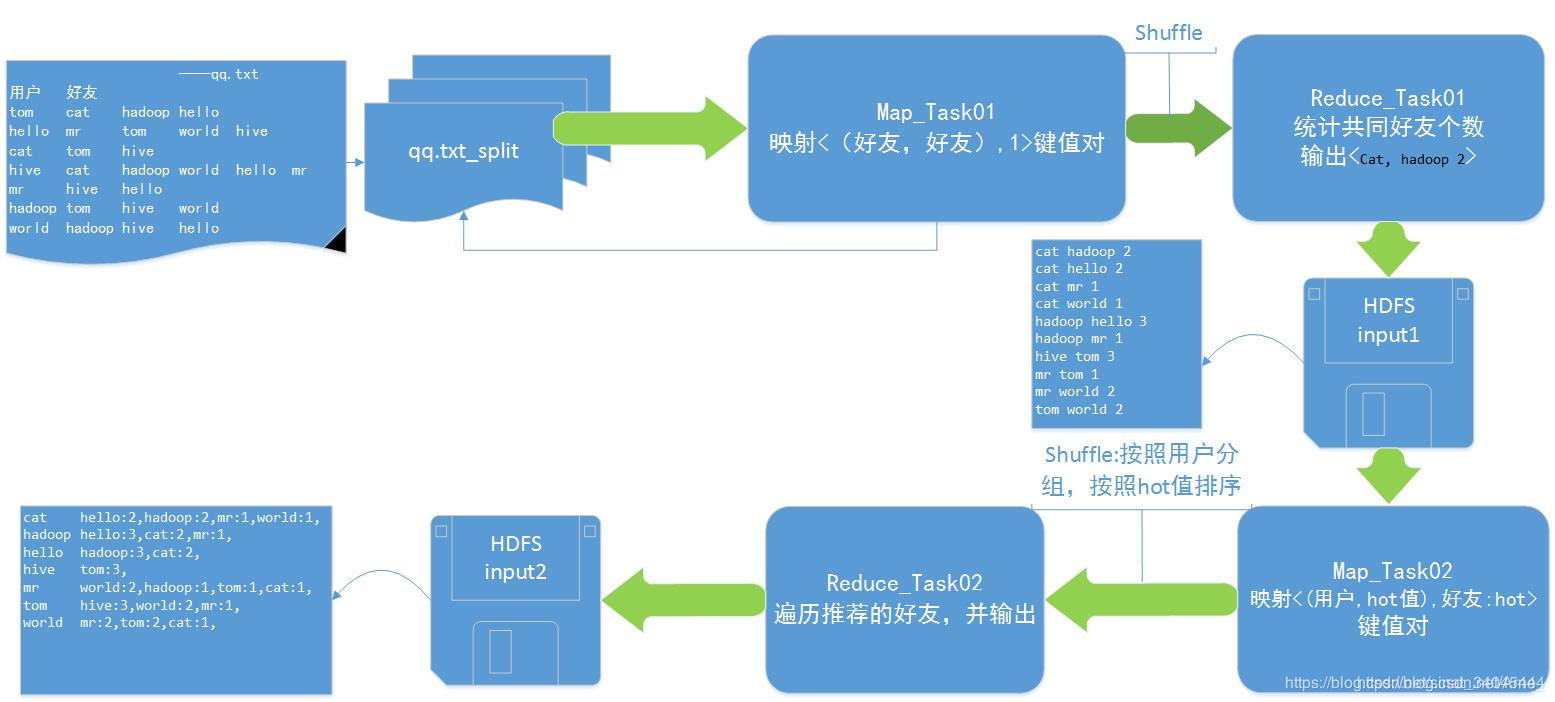
二、MapReduce程序实现
package friends;
...
public class RunJob {
public static void main(String[] args) {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
try {
Job job = Job.getInstance(conf);
FileSystem fs = FileSystem.get(conf);
job.setJobName("friend1");
job.setJarByClass(RunJob.class);
job.setMapperClass(Mapper1.class);
job.setReducerClass(Reducer1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1); //设置reduce的数量
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置计算输入数据
FileInputFormat.addInputPath(job, new Path("/friend"));
//设置计算输出目录(mapreduce计算完成之后,最后的结果存放的目录)
Path outpath = new Path("/fout/f1"); //该目录必须不能存在,如果存在计算框架会出错
if (fs.exists(outpath)) {//如果存在该目录,则删除
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
//开始执行
boolean f = job.waitForCompletion(true);
if (f) {
System.out.println("mapreduce程序1执行成功");
job = Job.getInstance(conf);
job.setJobName("friend1");
job.setJarByClass(RunJob.class);
job.setMapperClass(RunJob.Mapper2.class);
job.setReducerClass(RunJob.Reducer2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setSortComparatorClass(RunJob.SortComparator.class);
job.setGroupingComparatorClass(RunJob.GroupComparator.class);
job.setNumReduceTasks(1); //设置reduce的数量
job.setInputFormatClass(KeyValueTextInputFormat.class);
FileInputFormat.addInputPath(job, new Path("/fout/f1"));
outpath = new Path("/fout/f2");
if (fs.exists(outpath)) { //如果存在该目录,则删除
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
f = job.waitForCompletion(true);
if (f) {
System.out.println("mapreduce2程序2执行成功");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
*
*/
static class Mapper1 extends Mapper<Text, Text, Text, IntWritable> {
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
String user = key.toString();
String[] frinends = value.toString().split(" ");
for (int i = 0; i < frinends.length; i++) {
String f1 = frinends[i];
// 获得直接好友
String userAndFriend = getFof(user, f1);
//输出直接好友
context.write(new Text(userAndFriend), new IntWritable(-1));
//从当前一个开始往后遍历
for (int j = i + 1; j < frinends.length; j++) {
String f2 = frinends[j];
String fof = getFof(f1, f2);
context.write(new Text(fof), new IntWritable(1));
}
}
}
/**
* 保证好友顺序一致
*
* @param user1
* @param user2
* @return
*/
private String getFof(String user1, String user2) {
if (user1.compareTo(user2) > 0) {
return user1 + ":" + user2;
} else {
return user2 + ":" + user1;
}
}
}
/**
* 第二次map操作
*/
static class Mapper2 extends Mapper<Text, Text, Text, Text> {
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
String[] users = key.toString().split(":");
int count = Integer.parseInt(value.toString());
Text k1 = new Text(users[0] + "," + count);
Text v1 = new Text(users[1]);
context.write(k1, v1);
Text k2 = new Text(users[1] + "," + count);
Text v2 = new Text(users[0]);
context.write(k2, v2);
}
}
/**
* reduce阶段 第一次
*/
static class Reducer1 extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//判断是否存在直接好友的FOF
int sum = 0;
boolean flag = true;
for (IntWritable i : values) {
if (i.get() == -1) {
flag = false;
break;
} else {
sum += i.get();
}
}
if (flag) {
context.write(key, new IntWritable(sum));
}
}
}
/**
* 第二次reduce
*/
static class Reducer2 extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
String user = key.toString().split(",")[0];
for (Text t : values) {
stringBuffer.append(t.toString()).append(" ");
}
stringBuffer.substring(0, stringBuffer.length() - 1);
context.write(new Text(user), new Text(stringBuffer.toString()));
}
}
/**
* 自定义排序比较器
*/
static class SortComparator extends WritableComparator {
public SortComparator() {
super(Text.class, true);
}
/**
* @param a
* @param b
* @return
*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
Text k1 = (Text) a;
Text k2 = (Text) b;
String[] sk1 = k1.toString().split(",");
String[] sk2 = k2.toString().split(",");
int res = sk1[0].compareTo(sk2[0]);
return res == 0 ? (-Integer.compare(Integer.parseInt(sk1[1]), Integer.parseInt(sk2[1]))) : res;
}
}
/**
* 分组比较器
*/
static class GroupComparator extends WritableComparator {
public GroupComparator() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
Text k1 = (Text) a;
Text k2 = (Text) b;
String[] kk1 = k1.toString().split(",");
String[] kk2 = k2.toString().split(",");
return kk1[0].compareTo(kk2[0]);
}
}
}
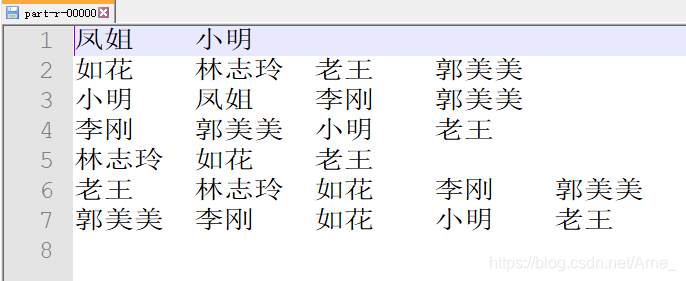
结果:
.
.
.
.
.
.
.
参考:
https://blog.csdn.net/liuzebin9/article/details/75093190
https://blog.csdn.net/sinat_34045444/article/details/86484934