接上文:https://www.cnblogs.com/erlou96/p/13856089.html
根据上文的jdk的docker镜像,来制作hadoop大数据docker镜像
一: 基础环境准备
- open-jdk1.8的docker镜像(上文已制作好)
- hadoop-3.2.1(自行网上下载)
二: Hadoop安装包配置修改
新建目录:
mkdir -p /opt/docker-file/ubuntu-ssh-jdk-hadoop
将hadoop安装包放到目录下:
cp -r hadoop-3.2.1.tar.gz /opt/docker-file/ubuntu-ssh-jdk-hadoop
解压hadoop安装包:
tar -zxvf hadoop-3.2.1.tar.gz
修改$HADOOP_HOME/etc/hadoop 目录下的配置文件
- 修改hadoop-env.sh
插入如下:
export JAVA_HOME=/usr/java/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 修改core-site.xml
内容如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- 修改hdfs-site.xml
内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/mnt/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/mnt/hadoop/hdfs/data</value>
</property>
</configuration>
- 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
- 修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME</value>
</property>
</configuration>
- 修改workers文件
master
slave1
slave2
修改$HADOOP_HOME/sbin 目录下的启动脚本
- 修改start-dfs.sh和stop-dfs.sh(顶部添加即可)
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
- 修改start-yarn.sh 和 stop-yarn.sh (顶部添加即可)
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
删除$HADOOP_HOME/share/doc 目录
rm -rf /opt/docker-file/ubuntu-ssh-jdk-hadoop/hadoop-3.2.1/share/doc
重新归档压缩hadoop
tar -czvf hadoop.tar.gz hadoop-3.2.1
三: 编写Dockerfile文件
Dockerfile文件内容如下:
# 选择一个已有的os镜像作为基础
FROM ubuntu-ssh-jdk:v1
# 镜像的作者
MAINTAINER hanzhe
# ADD命令 将jdk打包文件上传到镜像的/usr/java ,会自动解压
ADD hadoop.tar.gz /opt
# 配置java环境变量
ENV JAVA_HOME /usr/java/jdk
ENV PATH $JAVA_HOME/bin:$PATH
RUN mv /opt/hadoop-3.2.1 /opt/hadoop
&& mkdir -p /mnt/hadoop/hdfs/name
&& mkdir -p /mnt/hadoop/hdfs/data
&& mkdir -p /mnt/hadoop/tmp
ENV HADOOP_HOME /opt/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
四: 构建docker image
构建命令:
docker build -t="ubuntu-ssh-jdk-hadoop:v1" .
五: 查看docker image
docker images

六: 配置docker网络
参考本人另一篇博客:https://www.cnblogs.com/erlou96/p/12113408.html
七: 启动容器
#启动master容器
docker run --name master --add-host slave1:172.172.0.11 --add-host slave2:172.172.0.12 --net docker-br0 --ip 172.172.0.10 --hostname master -d -P ubuntu-ssh-jdk-hadoop:v1
#启动slave1容器
docker run --name slave1 --add-host master:172.172.0.10 --add-host slave2:172.172.0.12 --net docker-br0 --ip 172.172.0.11 --hostname slave1 -d -P ubuntu-ssh-jdk-hadoop:v1
#启动slave2容器
docker run --name slave2 --add-host master:172.172.0.10 --add-host slave2:172.172.0.11 --net docker-br0 --ip 172.172.0.12 --hostname slave2 -d -P ubuntu-ssh-jdk-hadoop:v1
(别人的方案)给容器设置固定IP
- 安装pipework
- 下载pipework
- 下载地址:https://github.com/jpetazzo/pipework.git
- 把下载的zip包上传到宿主机服务器上,解压,改名字
#解压
unzip pipework-master.zip
#重命名
mv pipework-master pipework
#拷贝环境变量
cp -rp pipework/pipework /usr/local/bin/
- 安装bridge-utils
apt install bridge-utils
- 创建网络
brctl addbr br1
ip link set dev br1 up
ip addr add 192.168.2.1/24 dev br1
- 给容器设置固定ip
pipework br1 master 192.168.2.10/24
pipework br1 slave1 192.168.2.11/24
pipework br1 slave2 192.168.2.12/24
- 如果容器被移除,有重新启动,需要将对应的虚拟网卡卸载掉
# 因为重新启动的docker容器mac地址不一样,所以主机名虽然对应,但仍无法ping通
ifconfig XXXX down
# 重新分配固定ip
pipework br1 master 192.168.2.10/24
- 验证
能ping通,就说明没问题!
七: 设置ssh免密码登录
进入容器
docker exec -it master /bin/bash
ssh-keygen -t rsa(一直按回车即可)
分发秘钥
ssh-copy-id master
八:启动服务
启动伪分布式hadoop集群:
#进入目录
cd /opt/hadoop/sbin/
启动hdfs:
./start-dfs.sh
启动yarn:
./start-yarn.sh
如果启动报错,原因有如下几个:
- 免密没有制作
- 不让以root用户,进行启动,参考上面的修改即可
- ubuntu的解释器 默认为dash,需修改成bash,参考另一篇博客即可https://www.cnblogs.com/erlou96/p/13398387.html
- 配置文件有误
jps 查看服务进程
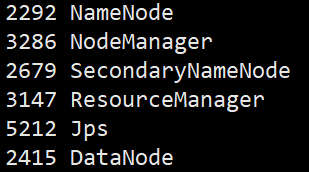
好了:到此搭建hadoop集群,到此为止!