字符串常量池
常量池
- 常量池是
JAVA的一项技术,八种基础数据类型(byte、short、int、long、float、double、boolean、char)除了float和double都实现了常量池技术- 将经常用到的数据存放在一块内存中,实现数据共享,从而避免了数据的重复创建与销毁,提高了系统性能
字符串常量池
字符串常量池是 JAVA 常量池技术的一种实现,在JDK1.8以后,字符串常量池也被是现在JAVA堆内存中
为什么存在字符串常量池
- 字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能
- JVM 为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化
- 为字符串开辟一个字符串常量池,类似于缓存区
- 创建字符串常量时,首先判断字符串常量池是否存在该字符串,存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
字符串常量池实现的基础
- 实现该优化的基础是因为字符串是不可变的,可以不用担心数据冲突进行共享
- 运行时实例创建的全局字符串常量池中有一个表,总是为池中每个唯一的字符串对象维护一个引用,这就意味着它们一直引用着字符串常量池中的对象,所以,在常量池中的这些字符串不会被垃圾收集器回收
字符串常量池存在哪里
JVM 运行时数据区

堆:存储的是对象,每个对象都包含一个与之对应的Class,堆中不存放基本数据类型和对象引用,只存放对象本身,对象由垃圾回收器负责回收,因此大小和生命周期不需要确定
栈:每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),每个栈中的数据(原始类型和对象引用)都是私有的。栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令),数据大小和生命周期是可以确定的,当没有引用指向数据时,这个数据就会自动消失
方法区:静态区,跟堆一样,被所有的线程共享。方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量
字符串常量池则存在于方法区
注意:
- java7之前,方法区位于永久代(PermGen),永久代和堆相互隔离,永久代的大小在启动
JVM时可以设置一个固定值,不可变- java7中,static变量从永久代移到堆中
- java8中,取消永久代,方法区存放于元空间(Metaspace),元空间仍然与堆不相连,但与堆共享物理内存,逻辑上可认为在堆中
- JDK1.8 中字符串常量池和运行时常量池逻辑上属于方法区,但是实际存放在堆内存中,因此既可以说两者存放在堆中,也可以说两者存在于方法区中,这就是造成误解的地方
字符串创建案例
字符串的两种创建方式
方式一
String s1 = "hello";
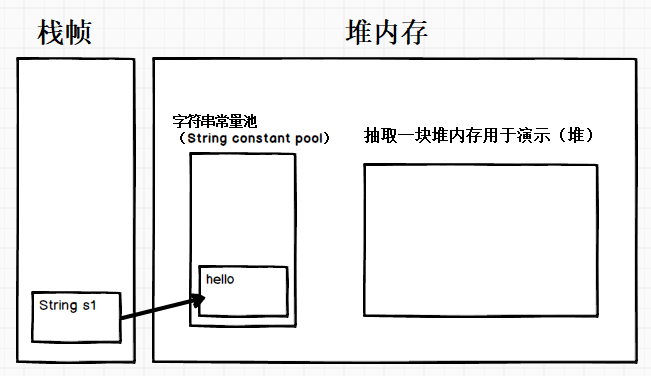
先在栈中创建一个对
String类的对象引用变量s1,然后通过符号引用去字符串常量池里找有没有"hello"如果没有则将
"hello"存放到字符串常量池,并且将此常量的引用返回给s1如果已有
"hello"常量,则直接返回字符串常量池中"hello"的引用给s1
eg:
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
可以看出str1和str2是指向同一个对象的
方式二
String s2 = new String("hello");
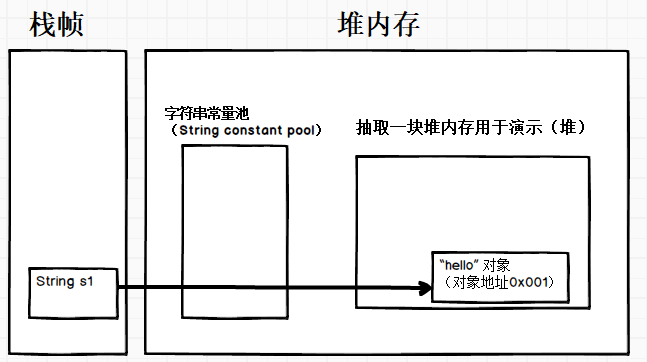
- 每一次创建都会在堆中(非字符串常量池中)创建字符串对象,而且并不会把
"hello"对象地址加入到字符串常量池中,最终把该对象的引用返回给s1- 用
new String()创建的字符串不是常量,不能在编译期就确定,所以new String()创建的字符串不放入常量池中,它们有自己的地址空间
String str1 =new String ("abc");
String str2 =new String ("abc");
System.out.println(str1==str2); // false
用new的方式是生成不同的对象。每new次生成一个,因此返回false
intern() 方法
String s1 = new String("hello");
String s1intern = s1.intern();
String s2 = "hello";
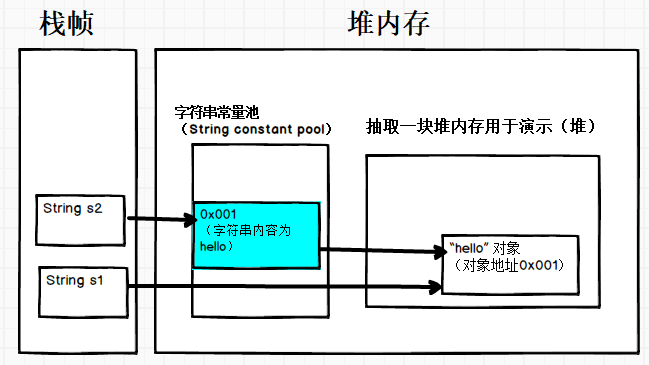
当调用 intern 方法时:
如果常量池中已经该字符串,则返回池中的字符串
否则将此字符串添加到常量池中,并返回字符串的引用
常见案例
案例一
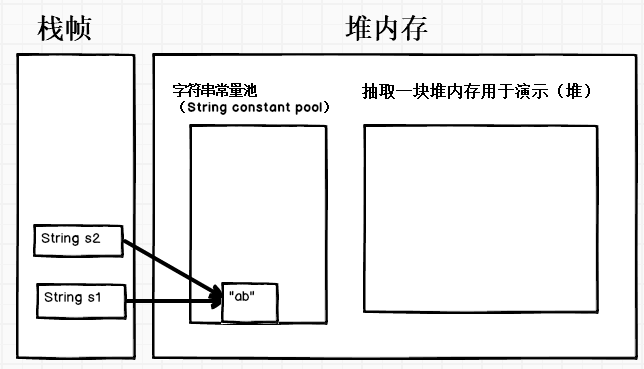
public static void main(String[] args){
//“ab”在编译的时候就能确定,所以编译的时候,ab被放进了常量池中,同时s1指向常量池中的ab对象
String s1 = "ab";
//a和b这两个常量都能在编译时确定,所以他们相加的结果也能确定,因此编译器检查常量池中是否有值为ab的String对象,发现有了,因此s2也指向常量池中的ab对象
String s2 = "a" + "b";
System.out.println(s1 == s2);//true
}
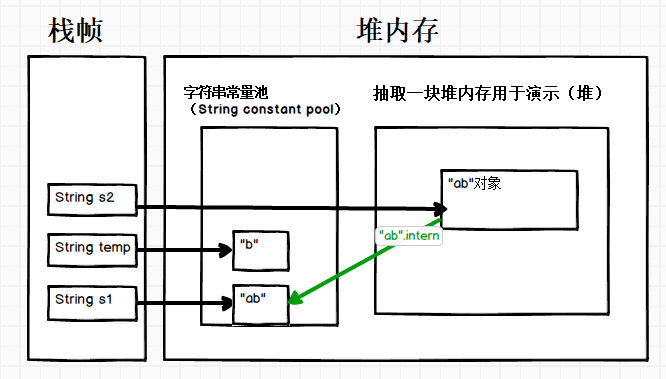
案例二
public static void main(String[] args){
String s1 = "ab";
String temp = "b";
String s2 = "a" + temp; //编译时期不能确定为常量
System.out.println(s1 == s2); //false
System.out.println(s1 == s2.intern()); //true
}
案例三
public static void main(String[] args){
String s1 = "ab";
final String temp = "b";
String s2 = "a" + temp; //temp加final后是常量,可以在编译期确定b
System.out.println(s1 == s2); //true
}
案例四
public class test4 {
public static void main(String[] args){
String s1 = "ab";
final String temp = m1();
//temp是通过函数返回的,虽然知道它是final的,但不知道具体是啥,要到运行期才知道temp的值
String s2 = "a" + temp;
System.out.println(s1 == s2); //false
System.out.println(s1 == s2.intern()); //true
}
private static String m1(){
return "b";
}
}
案例五
public class test5 {
private static String a = "ab";
public static void main(String[] args){
String s1 = "a";
String s2 = "b";
String s = s1 + s2; // s1、s2 在编译期不能确定是否是常量
System.out.println(s == a); // flase
System.out.println(s.intern() == a); //intern的含义 // true
}
}
案例六
public class test6 {
private static String a = new String("ab");
public static void main(String[] args){
String s1 = "a";
String s2 = "b";
String s = s1 + s2;
System.out.println(s == a); // flase
System.out.println(s.intern() == a); // flase
System.out.println(s.intern() == a.intern()); // true
}
}
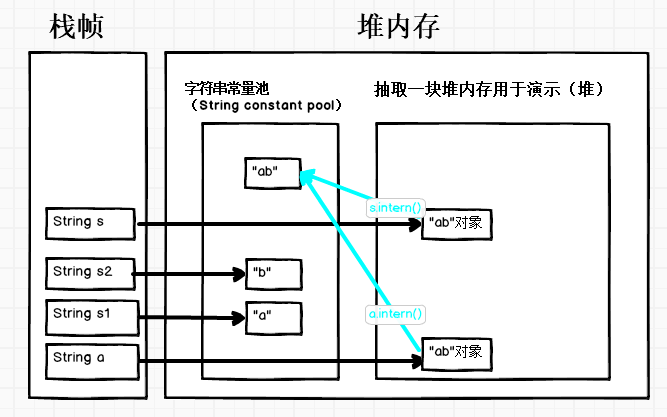
案例七
String s1 = new String("s1") ;
String s2 = new String("s1") ;
上面的代码创建了3个String对象,在编译期字符串常量池中创建了一个,运行期在堆中创建了两个(用new创建时,每new一次就在堆上创建一个对象,用引号创建的如果在常量池中已有就直接指向,不用创建)
案例八
String s1 = "s1";
String s2 = s1;
s2 = "s2";
s1指向的对象中的字符串是"s1",字符串是不可变的,s2 = “s2”实际上s2的指向就变了
小总结
当用new关键字创建字符串对象时, 不会查询字符串常量池
当用
""直接声明字符串对象时, 会查询字符串常量池通俗来讲就是字符串常量池提供了字符串的复用功能, 除非我们要显式创建新的字符串对象, 否则对同一个字符串虚拟机只会维护一份拷贝
字符串操作类
String
查看String源码可以发现,String底层是通过char类型数组实现的
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
StringBuilder & StringBuffer
查看StringBuilder以及StringBuffer源码也可以发现,他们都继承了AbstractStringBuilder类,当查看AbstractStringBuilder类时,其也使用char类型数组实现
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
}
通过两者都继承同一父类可以推断两者方法都是差不多的,只不过通过查看源码发现StringBuffer 的方法上添加了synchronized关键字,说明``StringBuffer 绝大部分方法都是线程安全的 ,因此在多线程的环境下应该使用StringBuffer以保证线程安全, 在单线程环境下我们应使用StringBuilder`以获得更高的效率
String 与 StrintgBuilder的区别
通过查看StringBuilder和String的源码我们会发现两者之间一个关键的区别:
对于String, 凡是涉及到返回参数类型为String类型的方法, 在返回的时候都会通过new关键字创建一个新的字符串对象
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
而对于StringBuilder, 大多数方法都会返回StringBuilder对象自身.
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
}
以字符串拼接为例:
当用String类拼接字符串时,
每次都会生成一个
StringBuilder对象, 然后调用两次append()方法把字符串拼接好, 最后通过StringBuilder的toString()方法new出一个新的字符串对象 也就是说每次拼接都会
new出两个对象, 并进行两次方法调用, 如果拼接的次数过多, 创建对象所带来的时延会降低系统效率, 同时会造成巨大的内存浪费. 而且当内存不够用时, 虚拟机会进行垃圾回收, 这也是一项相当耗时的操作, 会大大降低系统性能当用StringBuilder类拼接字符串时
StringBuilder拼接字符串就简单多了, 直接调用append方法就完事了, 除了最开始时需要创建StringBuilder对象, 运行时期没有创建过其他任何对象, 每次循环只调用一次append方法. 所以从效率上看, 拼接大量字符串时,StringBuilder要比String类快很多