Elasticsearch总结
1:项目结构
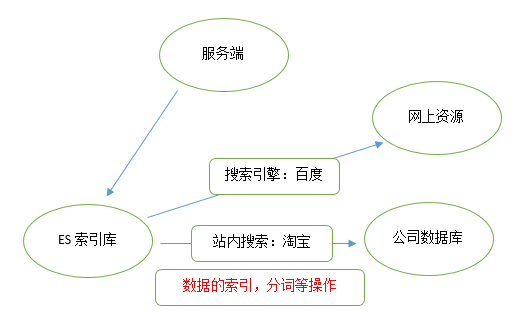
2.介绍
2.1 什么是elasticsearch?
它是一个天生的实时的分布式搜索和分析引擎。他可以处理大规模的数据,在大规模的搜索时相比solr的效率高性能好,不需要借助外部插件来完成分布式搜索功能。是一个基于lucene的搜索服务器。基于restful web接口,它是用java语言开发的,能达到实时搜索,稳定、可靠、快速、安装使用方便等优势。
注释:实时搜索(多次搜索的结果动态变化,不局限于静态数据的搜索)
2.2 elasticsearch的特点
(1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公
司;也可以运行在单机上
(2)将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;
(3)开箱即用的,部署简单
(4)全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理
3.基本概念
3.1索引(一般称索引库,类比关系型数据库的数据库)
3.2类型(类比关系型数据库中的表)
3.3文档(类比数据库中的行)
4.postman调用restAPI
4.1创建索引
例如我们要创建一个叫articleindex的索引 ,就以put方式提交
注意无需添加body数据
http://127.0.0.1:9200/articleindex/
4.2新建文档
以post方式提交 http://127.0.0.1:9200/索引名称/类型(文档名称)
Body需要添加json数据(类比添加文档下的字段及内容)
{
“key”:”value”
}
4.3查询一个类型(全部文档)
查询某索引某类型的全部数据,以get方式请求
http://127.0.0.1:9200/articleindex/article/_search 返回结果如下:
_id是由系统自动生成的。
4.4修改类型(全部文档)
如果我们在地址中的ID不存在,则会创建新文档
以put形式提交以下地址:
http://192.168.184.134:9200/索引/类型/AWPKrI4pFdLZnId5S_F7
body:
{
“key”:”value”
}
注意:如果类型有多个数据,修改必须将未修改的数据也写上,否则丢失其他数据。
4.5按_id查询类型的数据
GET方式请求
http://192.168.184.134:9200/articleindex/article/1
4.6基本匹配查询(模糊查询*代表0到多个任意字符)
根据某列进行查询 get方式提交下列地址:
http://192.168.184.134:9200/articleindex/article/_search?q=title:titleValue
http://192.168.184.134:9200/articleindex/article/_search?q=title:titleValue*
titleValue可以用使用正则
4.7删除文档
根据ID删除文档,删除ID为1的文档 DELETE方式提交
http://192.168.184.134:9200/articleindex/article/1
5.Head插件的安装与使用(可视化界面操作ES)
如果都是通过rest请求的方式使用Elasticsearch,未免太过麻烦,而且也不够人性化。我
们一般都会使用图形化界面来实现Elasticsearch的日常管理,最常用的就是Head插件
步骤1:
下载head插件:https://github.com/mobz/elasticsearch-head
elasticsearch-head-master.zip
步骤2:
解压到任意目录,但是要和elasticsearch的安装目录区别开。
步骤3:
安装node js ,安装cnpm
npm install ‐g cnpm ‐‐registry=https://registry.npm.taobao.org
步骤4:
将grunt安装为全局命令 。Grunt是基于Node.js的项目构建工具。它可以自动运行你所设定的任务
npm install ‐g grunt‐cli
步骤5:安装依赖
cnpm install
步骤6:
进入head目录启动head,在命令提示符下输入命令
grunt server
步骤7:
打开浏览器,访问head插件项目,输入http://localhost:9100
步骤8:
点击连接按钮没有任何相应,按F12发现有如下错误
No 'Access-Control-Allow-Origin' header is present on the requested resource
这个错误是由于elasticsearch默认不允许跨域调用,而elasticsearch-head是属于前端工程,所以报错。
我们这时需要修改elasticsearch的配置,让其允许跨域访问。
修改elasticsearch配置文件:elasticsearch.yml,增加以下两句命令:
http.cors.enabled: true
http.cors.allow-origin: "*"
此步为允许elasticsearch跨越访问 点击连接即可看到相关信息
5.1 Head插件操作
5.1.1 新建索引
选择“索引”选项卡,点击“新建索引”按钮
输入索引名称点击OK
5.1.2 新建或修改文档
在复合查询中提交地址,输入内容,提交方式为PUT
点击数据浏览 ,点击要查询的索引名称,右侧窗格中显示文档信息
点击文档信息:
修改数据后重新提交请求 , ID已经存在,所以执行的是修改操作。
不存在则为添加操作
重新查询此记录,发现版本为2。也就是说每次修改后版本都会增加1.
5.1.3 查询
不点击任何表示查询所有索引的文档,点击谁单独查谁。
5.1.4 删除
6.ik分词器
默认的中文分词是将每个字看成一个词,这显然是不符合要求的,所以我们需要安装中
文分词器来解决这个问题。
IK分词是一款国人开发的相对简单的中文分词器。虽然开发者自2012年之后就不在维护
了,但在工程应用中IK算是比较流行的一款!我们今天就介绍一下IK中文分词器的使用。
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=搜索关键字
6.4 自定义词库(添加词库)
测试"传智播客",浏览器的测试效果如下:
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=传智播客
不存在词语,所以单个字都分开了。
所以需要添加额外的词语
步骤
(1)进入elasticsearch/plugins/ik/config目录
(2)新建一个my.dic文件,编辑内容:
传智播客
修改IKAnalyzer.cfg.xml(在ik/config目录下)添加my.dic文件到配置中
重新启动elasticsearch,通过浏览器测试分词效果
7.使用java继承Springdate-elasticsearch
1.导入Spring-date-elasticsearch坐标
2.编写application.yml配置文件
server:
port: 9007
spring:
application:
name: tensquare‐search #指定服务名
data:
elasticsearch:
cluster‐nodes: 127.0.0.1:9300
3.dao层接口继承ElasticsearchRepository<对应类,String>接口
4.在对应类中要添加以下注释
//indexName:数据库(索引)名称,article类型名称
@Document(indexName = "tensquare_article",type = "article")
public class Article implements Serializable {
@Id
private String id;
//是否索引,就看该字段能否被搜索
//是否分词,表示搜索的时候是整体匹配还是单词匹配
//是否存储,就是是否在页面显示
// 使用查询分词器searchAnalyzer =
"ik_max_word",要与存的分词器相同
// 使用存储分词器:analyzer
="ik_max_word",指的是存储到关系型数据库
// index = true表示这列是索引
@Field(index = true,analyzer ="ik_max_word",searchAnalyzer = "ik_max_word")
5.在service层可以调用ElasticsearchRepository中默认支持的方法
在dao层可以添加jpa规则的方法搜索
例如
Page<Article> findByContentOrTitleLike(String title, String content, Pageable pageable);
6.在controller层
return new Result(true, StatusCode.OK,"搜索成功",
new PageResult<Article>(list.getTotalElements(),list.getContent()));
8.注意事项
在docker启动ES时9300端口默认不可用
进入容器目录:
Docker exec –it +name(或id)
新建一个挂载新文件在docker容器中的容器:
V 宿主机文件:docker文件
修改挂载的文件(宿主机的文件)
将transport.host: 0.0.0.0取消注释,外部即可访问9300端口
9. IK分词器安装
(1)快捷键alt+p进入sftp , 将ik文件夹上传至宿主机
sftp> put ‐r d:setupik
(2)在宿主机中将ik文件夹拷贝到容器内 /usr/share/elasticsearch/plugins 目录下。
docker cp ik tensquare_elasticsearch:/usr/share/elasticsearch/plugins/
(3)重新启动,即可加载IK分词器
docker restart tensquare_elasticsearch