【注】
1、该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取;
2、Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用一般使用64位操作系统,内容分为三部分:基础环境搭建、Hadoop编译安装和Spark编译安装,该环境作为后续实验基础;
3、文章演示了Hadoop、Spark的编译过程,同时附属资源提供了编译好的安装包,觉得编译费时间可以直接使用这些编译好的安装包进行部署。
1、运行环境说明
1.1 硬软件环境
l 主机操作系统:Windows 64位,双核4线程,主频2.2G,10G内存
l 虚拟软件:VMware® Workstation 9.0.0 build-812388
l 虚拟机操作系统:CentOS6.5 64位,单核,1G内存
l 虚拟机运行环境:
Ø JDK:1.7.0_55 64位
Ø Hadoop:2.2.0(需要编译为64位)
Ø Scala:2.10.4
Ø Spark:1.1.0(需要编译)
1.2 集群网络环境
集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下:
|
序号 |
机器名 |
类型 |
核数/内存 |
用户名 |
目录 |
|
|
1 |
192.168.0.61 |
hadoop1 |
NN/DN/RM Master/Worker |
1核/3G |
hadoop |
/app 程序所在路径 /app/scala-... /app/hadoop /app/complied |
|
2 |
192.168.0.62 |
hadoop2 |
DN/NM/Worker |
1核/2G |
hadoop |
|
|
3 |
192.168.0.63 |
hadoop3 |
DN/NM/Worker |
1核/2G |
hadoop |
1.所有节点均是CentOS6.5 64bit系统,防火墙/SElinux均禁用,所有节点上均创建了一个hadoop用户,用户主目录是/home/hadoop,上传文件存放在/home/hadoop/upload文件夹中。
2.所有节点上均创建了一个目录/app用于存放安装程序,并且拥有者是hadoop用户,对其必须有rwx权限(一般做法是root用户在根目录下创建/app目录,并使用chown命令修改该目录拥有者为hadoop),否则hadoop用户使用SSH往其他机器分发文件会出现权限不足的提示
1.3 安装使用工具
1.3.1 Linux文件传输工具
向Linux系统传输文件推荐使用SSH Secure File Transfer,该工具顶部为工具的菜单和快捷方式,中间部分左面为本地文件目录,右边为远程文件目录,可以通过拖拽等方式实现文件的下载与上传,底部为操作情况监控区,如下图所示:
![clip_image002[4]](http://images0.cnblogs.com/blog/107289/201508/041120271731535.jpg "clip_image002[4]")
1.3.2 Linux命令行执行工具
l SSH Secure Shell SSH Secure工具的SSH Secure Shell提供了远程命令执行,如下图所示:
![clip_image004[4]](http://images0.cnblogs.com/blog/107289/201508/041120301422262.jpg "clip_image004[4]")
l SecureCRT SecureCRT是常用远程执行Linux命令行工具,如下图所示:
![clip_image006[4]](http://images0.cnblogs.com/blog/107289/201508/041120345643744.jpg "clip_image006[4]")
2、搭建样板机环境
本次安装集群分为三个节点,本节搭建样板机环境搭建,搭建分为安装操作系统、设置系统环境和配置运行环境三个步骤。
2.1 安装操作系统
第一步 插入CentOS 6.5的安装介质,使用介质启动电脑出现如下界面
![clip_image008[4]](http://images0.cnblogs.com/blog/107289/201508/041120362363498.jpg "clip_image008[4]")
lInstall or upgrade an existing system 安装或升级现有的系统
linstall system with basic video driver 安装过程中采用基本的显卡驱动
lRescue installed system 进入系统修复模式
lBoot from local drive 退出安装从硬盘启动
lMemory test 内存检测
第二步 介质检测选择"Skip",直接跳过
![clip_image010[4]](http://images0.cnblogs.com/blog/107289/201508/041120372833312.jpg "clip_image010[4]")
第三步 出现引导界面,点击“next”
![clip_image012[4]](http://images0.cnblogs.com/blog/107289/201508/041120406892440.jpg "clip_image012[4]")
第四步 选择安装过程语言,选中"English(English)"
![clip_image014[4]](http://images0.cnblogs.com/blog/107289/201508/041120452515178.jpg "clip_image014[4]")
第五步 键盘布局选择“U.S.English”
![clip_image016[4]](http://images0.cnblogs.com/blog/107289/201508/041120465803206.jpg "clip_image016[4]")
第六步 选择“Basic Storage Devies"点击"Next"
![clip_image018[4]](http://images0.cnblogs.com/blog/107289/201508/041120477362519.jpg "clip_image018[4]")
第七步 询问是否覆写所有数据,选择"Yes,discard any data"
![clip_image020[4]](http://images0.cnblogs.com/blog/107289/201508/041120510336444.jpg "clip_image020[4]")
第八步 Hostname填写格式“英文名.姓”
![clip_image022[4]](http://images0.cnblogs.com/blog/107289/201508/041120536589742.jpg "clip_image022[4]")
第九步 时区可以在地图上点击,选择“Shanghai”并取消System clock uses UTC选择
![clip_image024[4]](http://images0.cnblogs.com/blog/107289/201508/041120547515542.jpg "clip_image024[4]")
第十步 设置root的密码
![clip_image026[4]](http://images0.cnblogs.com/blog/107289/201508/041120561581313.jpg "clip_image026[4]")
第十一步 硬盘分区,一定要按照图示点选
![clip_image028[4]](http://images0.cnblogs.com/blog/107289/201508/041120571426613.jpg "clip_image028[4]")
第十二步 询问是否改写入到硬盘,选择"Write changes to disk"
![clip_image030[4]](http://images0.cnblogs.com/blog/107289/201508/041120582366710.jpg "clip_image030[4]")
第十三步 选择系统安装模式为"Desktop"
![clip_image032[4]](http://images0.cnblogs.com/blog/107289/201508/041120592989753.jpg "clip_image032[4]")
第十四步 桌面环境就设置完成了,点击安装
![clip_image034[4]](http://images0.cnblogs.com/blog/107289/201508/041121004237310.jpg "clip_image034[4]")
第十五步 安装完成,重启
![clip_image036[4]](http://images0.cnblogs.com/blog/107289/201508/041121038766721.jpg "clip_image036[4]")
第十六步 重启之后,的License Information
![clip_image038[4]](http://images0.cnblogs.com/blog/107289/201508/041121048458792.jpg "clip_image038[4]")
第十七步 创建用户和设置密码(这里不进行设置用户和密码)
![clip_image040[4]](http://images0.cnblogs.com/blog/107289/201508/041121075336604.jpg "clip_image040[4]")
第十八步 "Date and Time" 选中 “Synchronize data and time over the network”
Finsh之后系统将重启
![clip_image042[4]](http://images0.cnblogs.com/blog/107289/201508/041121084087703.jpg "clip_image042[4]")
2.2 设置系统环境
该部分对服务器的配置需要在服务器本地进行配置,配置完毕后需要重启服务器确认配置是否生效,特别是远程访问服务器需要设置固定IP地址。
2.2.1 设置机器名
以root用户登录,使用#vi /etc/sysconfig/network 打开配置文件,根据实际情况设置该服务器的机器名,新机器名在重启后生效
![clip_image044[4]](http://images0.cnblogs.com/blog/107289/201508/041121096587988.jpg "clip_image044[4]")
2.2.2 设置IP地址
1. 点击System-->Preferences-->Network Connections,如下图所示:
![clip_image046[4]](http://images0.cnblogs.com/blog/107289/201508/041121118305358.jpg "clip_image046[4]")
2. 修改或重建网络连接,设置该连接为手工方式,设置如下网络信息:
IP地址: 192.168.0.61
子网掩码: 255.255.255.0
网关: 192.168.0.1
DNS: 221.12.1.227 (需要根据所在地设置DNS服务器)
【注意】
1、网关、DNS等根据所在网络实际情况进行设置,并设置连接方式为"Available to all users",否则通过远程连接时会在服务器重启后无法连接服务器;
2、如果是运行在VM Ware虚拟机,网络使用桥接模式,设置能够连接到互联网中,以方便后面Hadoop和Spark编译等试验。
![clip_image048[4]](http://images0.cnblogs.com/blog/107289/201508/041121128611943.jpg "clip_image048[4]")
3. 在命令行中,使用ifconfig命令查看设置IP地址信息,如果修改IP不生效,需要重启机器再进行设置(如果该机器在设置后需要通过远程访问,建议重启机器,确认机器IP是否生效):
![clip_image050[4]](http://images0.cnblogs.com/blog/107289/201508/041121145489627.jpg "clip_image050[4]")
2.2.3设置Host映射文件
1. 使用root身份编辑/etc/hosts映射文件,设置IP地址与机器名的映射,设置信息如下:
#vi /etc/hosts
l 192.168.0.61 hadoop1
l 192.168.0.62 hadoop2
l 192.168.0.63 hadoop3
![clip_image052[4]](http://images0.cnblogs.com/blog/107289/201508/041121172055682.jpg "clip_image052[4]")
2. 使用如下命令对网络设置进行重启
#/etc/init.d/network restart
或者 #service network restart
![clip_image054[4]](http://images0.cnblogs.com/blog/107289/201508/041121186264682.jpg "clip_image054[4]")
3. 验证设置是否成功
![clip_image056[4]](http://images0.cnblogs.com/blog/107289/201508/041121225331022.jpg "clip_image056[4]")
2.2.4关闭防火墙
在hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常
1. service iptables status 查看防火墙状态,如下所示表示iptables已经开启
![clip_image058[4]](http://images0.cnblogs.com/blog/107289/201508/041121253922249.jpg "clip_image058[4]")
2. 以root用户使用如下命令关闭iptables
#chkconfig iptables off
![]()
2.2.5关闭SElinux
1. 使用getenforce命令查看是否关闭
![clip_image062[4]](http://images0.cnblogs.com/blog/107289/201508/041121291115645.gif "clip_image062[4]")
![clip_image064[4]](http://images0.cnblogs.com/blog/107289/201508/041121319087657.jpg "clip_image064[4]")
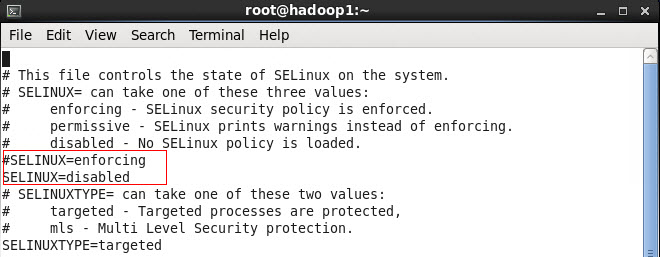
2. 修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效
#vi /etc/selinux/config
2.3 配置运行环境
2.3.1 更新OpenSSL
CentOS系统自带的OpenSSL存在bug,如果不更新OpenSSL在Ambari部署过程会出现无法通过SSH连接节点,使用如下命令进行更新:
#yum update openssl
![clip_image068[4]](http://images0.cnblogs.com/blog/107289/201508/041121378925097.jpg "clip_image068[4]")
![clip_image070[4]](http://images0.cnblogs.com/blog/107289/201508/041121392361652.jpg "clip_image070[4]")
2.3.2 修改SSH配置文件
1. 以root用户使用如下命令打开sshd_config配置文件
#vi /etc/ssh/sshd_config
开放三个配置,如下图所示:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
![clip_image072[4]](http://images0.cnblogs.com/blog/107289/201508/041121437514106.jpg "clip_image072[4]")
2. 配置后重启服务
#service sshd restart
![clip_image074[4]](http://images0.cnblogs.com/blog/107289/201508/041121449236648.jpg "clip_image074[4]")
2.3.3增加hadoop组和用户
使用如下命令增加hadoop 组和hadoop 用户(密码),创建hadoop组件存放目录
#groupadd -g 1000 hadoop
#useradd -u 2000 -g hadoop hadoop
#mkdir -p /app/hadoop
#chown -R hadoop:hadoop /app/hadoop
#passwd hadoop
![clip_image076[4]](http://images0.cnblogs.com/blog/107289/201508/041121462058689.jpg "clip_image076[4]")
创建hadoop用户上传文件目录,设置该目录组和文件夹为hadoop
#mkdir /home/hadoop/upload
#chown -R hadoop:hadoop /home/hadoop/upload
![clip_image078[4]](http://images0.cnblogs.com/blog/107289/201508/041121476733675.jpg "clip_image078[4]")
2.3.4JDK安装及配置
1. 下载JDK1.7 64bit安装包
打开JDK1.7 64bit安装包下载链接为:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
打开界面之后,先选中 Accept License Agreement ,然后下载 jdk-7u55-linux-x64.tar.gz,如下图所示:
![clip_image080[4]](http://images0.cnblogs.com/blog/107289/201508/041121496588101.jpg "clip_image080[4]")
2. 赋予hadoop用户/usr/lib/java目录可读写权限,使用命令如下:
$sudo chmod -R 777 /usr/lib/java
![clip_image082[4]](http://images0.cnblogs.com/blog/107289/201508/041121516111771.jpg "clip_image082[4]")
该步骤有可能遇到问题2.2,可参考解决办法处理
3. 把下载的安装包,使用1.1.3.1介绍的ssh工具上传到/usr/lib/java 目录下,使用如下命令进行解压
$tar -zxvf jdk-7u55-linux-x64.tar.gz
![clip_image084[4]](http://images0.cnblogs.com/blog/107289/201508/041121538304127.jpg "clip_image084[4]")
解压后目录如下图所示:
![clip_image086[4]](http://images0.cnblogs.com/blog/107289/201508/041121547986198.jpg "clip_image086[4]")
4. 使用root用户配置/etc/profile文件,并生效该配置
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
![clip_image088[4]](http://images0.cnblogs.com/blog/107289/201508/041121579707396.jpg "clip_image088[4]")
5. 重新登录并验证
$logout
$java -version
![clip_image090[4]](http://images0.cnblogs.com/blog/107289/201508/041121594862665.jpg "clip_image090[4]")
2.3.5 Scala安装及配置
1. 下载Scala安装包
Scala2.10.4安装包下载链接为:http://www.scala-lang.org/download/2.10.4.html,因为在Scala2.11.4下IDEA有些异常,故在这里建议安装Scala2.10.4版本
![clip_image092[4]](http://images0.cnblogs.com/blog/107289/201508/041122004396209.jpg "clip_image092[4]")
2. 上传Scala安装文件
把下载的scala安装包使用SSH Secure File Transfer工具(如1.3.1介绍)上传到/home/hadoop/upload目录下,如下图所示:
![clip_image094[4]](http://images0.cnblogs.com/blog/107289/201508/041122050331704.jpg "clip_image094[4]")
3. 解压缩
到上传目录下,用如下命令解压缩:
$cd /home/hadoop/upload
$tar -zxf scala-2.10.4.tgz
![clip_image096[4]](http://images0.cnblogs.com/blog/107289/201508/041122068611646.jpg "clip_image096[4]")
迁移到/app目录下:
$sudo mv scala-2.10.4 /app/
4. 使用root用户配置/etc/profile文件,并生效该配置
export SCALA_HOME=/app/scala-2.10.4
export PATH=$PATH:${SCALA_HOME}/bin
![clip_image098[4]](http://images0.cnblogs.com/blog/107289/201508/041122077981960.jpg "clip_image098[4]")
5. 重新登录并验证
$exit
$scala -version
![clip_image100[4]](http://images0.cnblogs.com/blog/107289/201508/041122095959144.jpg "clip_image100[4]")
3、配置集群环境
复制样板机生成其他两个节点,按照规划设置及其命名和IP地址,最后设置SSH无密码登录。
3.1 复制样板机
复制样板机两份,分别为hadoop2和hadoop3节点
![clip_image102[4]](http://images0.cnblogs.com/blog/107289/201508/041122105642216.jpg "clip_image102[4]")
3.2 设置机器名和IP地址
以root用户登录,使用vi /etc/sysconfig/network 打开配置文件,根据1.2规划修改机器名,修改机器名后需要重新启动机器,新机器名在重启后生效
![clip_image104[4]](http://images0.cnblogs.com/blog/107289/201508/041122114863599.jpg "clip_image104[4]")
按照2.2.2配置方法修改机器IP地址
![clip_image106[4]](http://images0.cnblogs.com/blog/107289/201508/041122125333413.jpg "clip_image106[4]")
3.3 配置SSH无密码登录
1. 使用hadoop用户登录在三个节点中使用如下命令生成私钥和公钥;
$ssh-keygen -t rsa
![clip_image108[4]](http://images0.cnblogs.com/blog/107289/201508/041122174398281.jpg "clip_image108[4]")
2. 进入/home/hadoop/.ssh目录在三个节点中分别把公钥命名为authorized_keys_hadoop1、authorized_keys_hadoop2和authorized_keys_hadoop3,使用命令如下:
$cd /home/hadoop/.ssh
$cp id_rsa.pub authorized_keys_hadoop1
![clip_image110[4]](http://images0.cnblogs.com/blog/107289/201508/041122188765808.jpg "clip_image110[4]")
3. 把两个从节点(hadoop2、hadoop3)的公钥使用scp命令传送到hadoop1节点的/home/hadoop/.ssh文件夹中;
$scp authorized_keys_hadoop2 hadoop@hadoop1:/home/hadoop/.ssh
$scp authorized_keys_hadoop3 hadoop@hadoop1:/home/hadoop/.ssh
![clip_image112[4]](http://images0.cnblogs.com/blog/107289/201508/041122209863963.jpg "clip_image112[4]")
![clip_image114[4]](http://images0.cnblogs.com/blog/107289/201508/041122219556034.jpg "clip_image114[4]")
4. 把三个节点的公钥信息保存到authorized_key文件中
使用$cat authorized_keys_hadoop1 >> authorized_keys 命令
![clip_image116[4]](http://images0.cnblogs.com/blog/107289/201508/041122234552776.jpg "clip_image116[4]")
5. 把该文件分发到其他两个从节点上
使用$scp authorized_keys hadoop@hadoop2:/home/hadoop/.ssh把密码文件分发出去
![clip_image118[4]](http://images0.cnblogs.com/blog/107289/201508/041122254392905.jpg "clip_image118[4]")
![clip_image120[4]](http://images0.cnblogs.com/blog/107289/201508/041122314234642.jpg "clip_image120[4]")
6. 在三台机器中使用如下设置authorized_keys读写权限
$chmod 400 authorized_keys
![]()
7. 测试ssh免密码登录是否生效
![clip_image124[4]](http://images0.cnblogs.com/blog/107289/201508/041122373452867.jpg "clip_image124[4]")
3.4 设置机器启动模式(可选)
设置好集群环境后,可以让集群运行在命令行模式下,减少集群所耗费的资源。以root用户使用#vi /etc/inittab,将 id:5:initdefault: 改为 id:3:initdefault:
![clip_image126[4]](http://images0.cnblogs.com/blog/107289/201508/041122391113593.jpg "clip_image126[4]")
Linux 系统任何时候都运行在一个指定的运行级上,并且不同的运行级的程序和服务都不同,所要完成的工作和所要达到的目的都不同。CentOS设置了如下表所示的运行级,并且系统可以在这些运行级别之间进行切换,以完成不同的工作。运行级说明
l 0 所有进程将被终止,机器将有序的停止,关机时系统处于这个运行级别
l 1 单用户模式。用于系统维护,只有少数进程运行,同时所有服务也不启动
l 2多用户模式。和运行级别3一样,只是网络文件系统(NFS)服务没被启动
l 3多用户模式。允许多用户登录系统,是系统默认的启动级别
l 4留给用户自定义的运行级别
l 5多用户模式,并且在系统启动后运行X-Window,给出一个图形化的登录窗口
l 6所有进程被终止,系统重新启动
4、问题解决
4.1 安装CentOS64位虚拟机 This host supports Intel VT-x, but Intel VT-x is disabled
在进行Hadoop2.X 64bit编译安装中由于使用到64位虚拟机,安装过程中出现下图错误:
![clip_image128[4]](http://images0.cnblogs.com/blog/107289/201508/041122415177892.jpg "clip_image128[4]")
按F1 键进入BIOS 设置实用程序 使用箭头键security面板下找virtualization按Enter 键 进去Intel VirtualizationTechnology改成Enabled按F10 键保存并退出 选择Yes按Enter 键 完全关机(关闭电源)等待几秒钟重新启动计算机此Intel虚拟化技术开启成功
4.2 *** is not in the sudoers file解决方法
当使用hadoop用户需要对文件夹进行赋权,使用chmod命令出现“hadoop is not in the sudoers file. This incident will be reported”错误,如下所示:
![clip_image130[4]](http://images0.cnblogs.com/blog/107289/201508/041122455808716.jpg "clip_image130[4]")
1. 使用su命令进入root用户
![clip_image132[4]](http://images0.cnblogs.com/blog/107289/201508/041122467056273.jpg "clip_image132[4]")
2. 添加文件的写权限,操作命令为:chmod u+w /etc/sudoers
![clip_image134[4]](http://images0.cnblogs.com/blog/107289/201508/041122486588942.jpg "clip_image134[4]")
3. 编辑/etc/sudoers文件,使用命令"vi /etc/sudoers"进入编辑模式,找到:"root ALL=(ALL) ALL"在起下面添加"hadoop ALL=(ALL) ALL",然后保存退出。
![clip_image136[4]](http://images0.cnblogs.com/blog/107289/201508/041122499396686.jpg "clip_image136[4]")