Sample Code
import torch
import random
import torchvision
from torch.utils.data import DataLoader
from torch import nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
n_epochs = 10
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 100
torch.backends.cudnn.enabled = False
random_seed = random.randint(1, 1000000)
torch.manual_seed(random_seed)
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([ # 归一化并转化为Tensor
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=3)
self.conv2 = nn.Conv2d(10, 20, kernel_size=3)
self.conv3 = nn.Conv2d(20, 20, kernel_size=3)
self.conv4 = nn.Conv2d(20, 30, kernel_size=3)
self.fc1 = nn.Linear(480, 100)
self.fc2 = nn.Linear(100, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = F.relu(self.conv3(x))
x = F.relu(F.max_pool2d(self.conv4(x), 2))
x = x.view(-1, 480)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
network = Net()
network = network.cuda()
optimizer = torch.optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
train_dataset_size = len(train_loader.dataset)
train_size = len(train_loader)
test_dataset_size = len(test_loader.dataset)
test_size = len(test_loader)
train_losses = []
train_acc_counter = []
train_acc = []
train_counter = []
test_losses = []
test_acc = []
test_counter = [i * train_dataset_size for i in range(n_epochs + 1)]
def train(epoch):
network.train() # 训练时, 调整网络至训练状态,启用 BN 和 Dropout
correct = 0
for batch_idx, (data, target) in enumerate(train_loader):
data = data.cuda()
target = target.cuda()
optimizer.zero_grad() # 梯度归零,保证每个 batch 互不干扰
output = network(data)
pred = output.data.max(1, keepdim=True)[1]
pred = pred.cuda()
correct += pred.eq(target.data.view_as(pred)).sum() # 计算正确答案数量
loss = F.nll_loss(output, target)
loss.backward() # 反向传播计算梯度值
optimizer.step() # 梯度下降实现参数更新
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data),
train_dataset_size,
100. * batch_idx / train_size, loss.item()))
train_losses.append(loss.item()) # 方便后续画图
train_counter.append((batch_idx * batch_size_train) + ((epoch - 1) * train_dataset_size))
correct = correct.cpu()
train_acc_counter.append(epoch * train_dataset_size)
train_acc.append(100. * correct / train_dataset_size)
print('Train Epoch {} Accuracy: {}/{} ({:.2f}%)'.format(epoch, correct, train_dataset_size,
100. * correct / train_dataset_size))
def test():
network.eval() # 评价时,禁用 BN 和 Dropout
test_loss = correct = 0
with torch.no_grad(): # 保证 requires_grad = False
for data, target in test_loader:
data = data.cuda()
target = target.cuda()
output = network(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
pred = pred.cuda()
correct += pred.eq(target.data.view_as(pred)).sum() # 计算正确答案数量
test_loss /= test_dataset_size
test_losses.append(test_loss)
correct = correct.cpu()
test_acc.append(100. * correct / test_dataset_size)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, test_dataset_size, 100. * correct / test_dataset_size))
test()
for i in range(1, n_epochs + 1):
train(i)
test()
fig = plt.figure()
plt.subplot(1, 2, 1)
plt.tight_layout()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.subplot(1, 2, 2)
plt.tight_layout()
plt.plot(train_acc_counter, train_acc, color = 'blue')
plt.scatter(test_counter, test_acc, color = 'red')
plt.legend(['Train Accuracy', 'Test Accuracy'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('Accuracy')
plt.show()
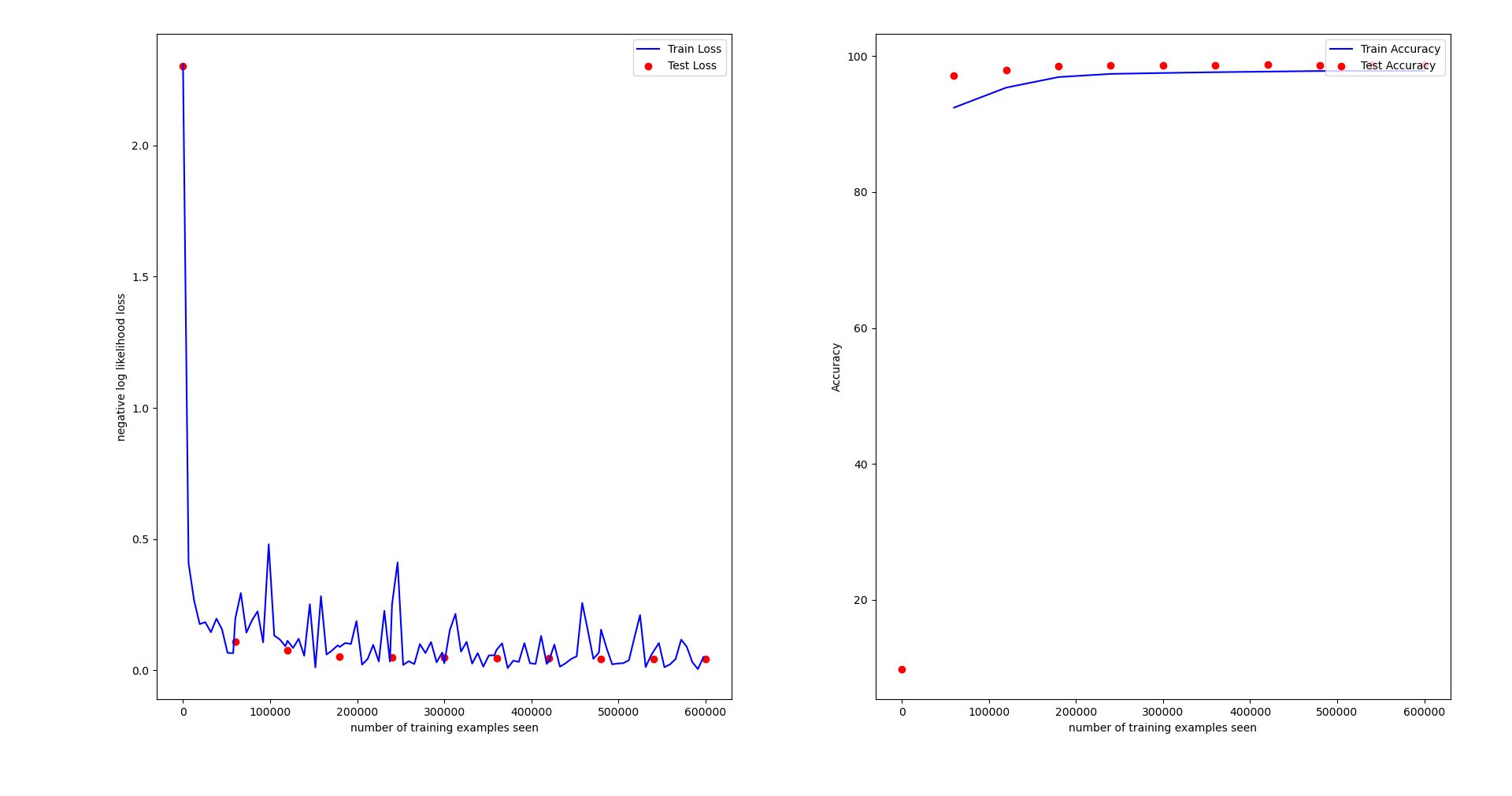
不同训练器下的训练效果(共 10 个epoch)
只用 Adam:
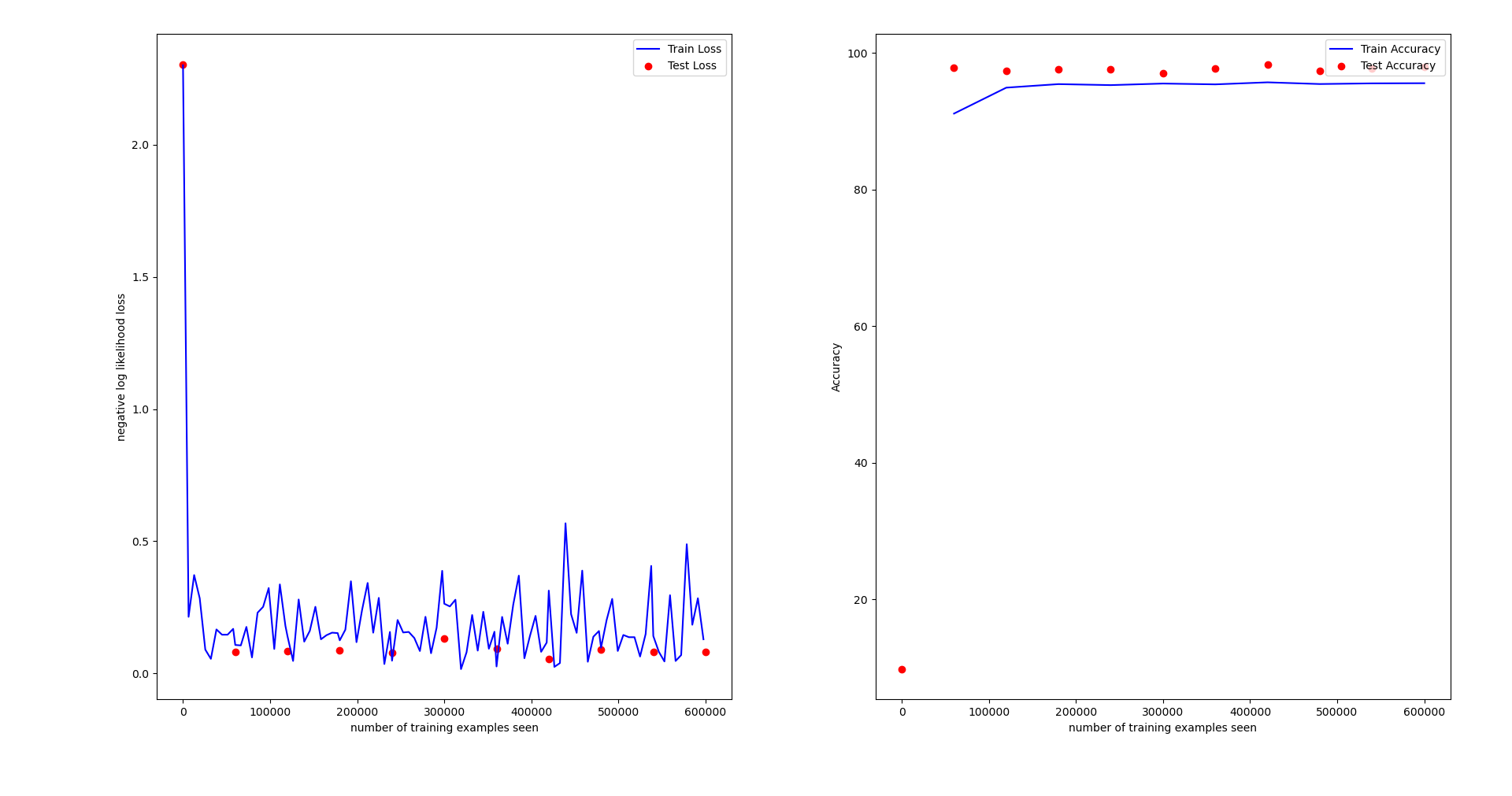
只用 SGDM:
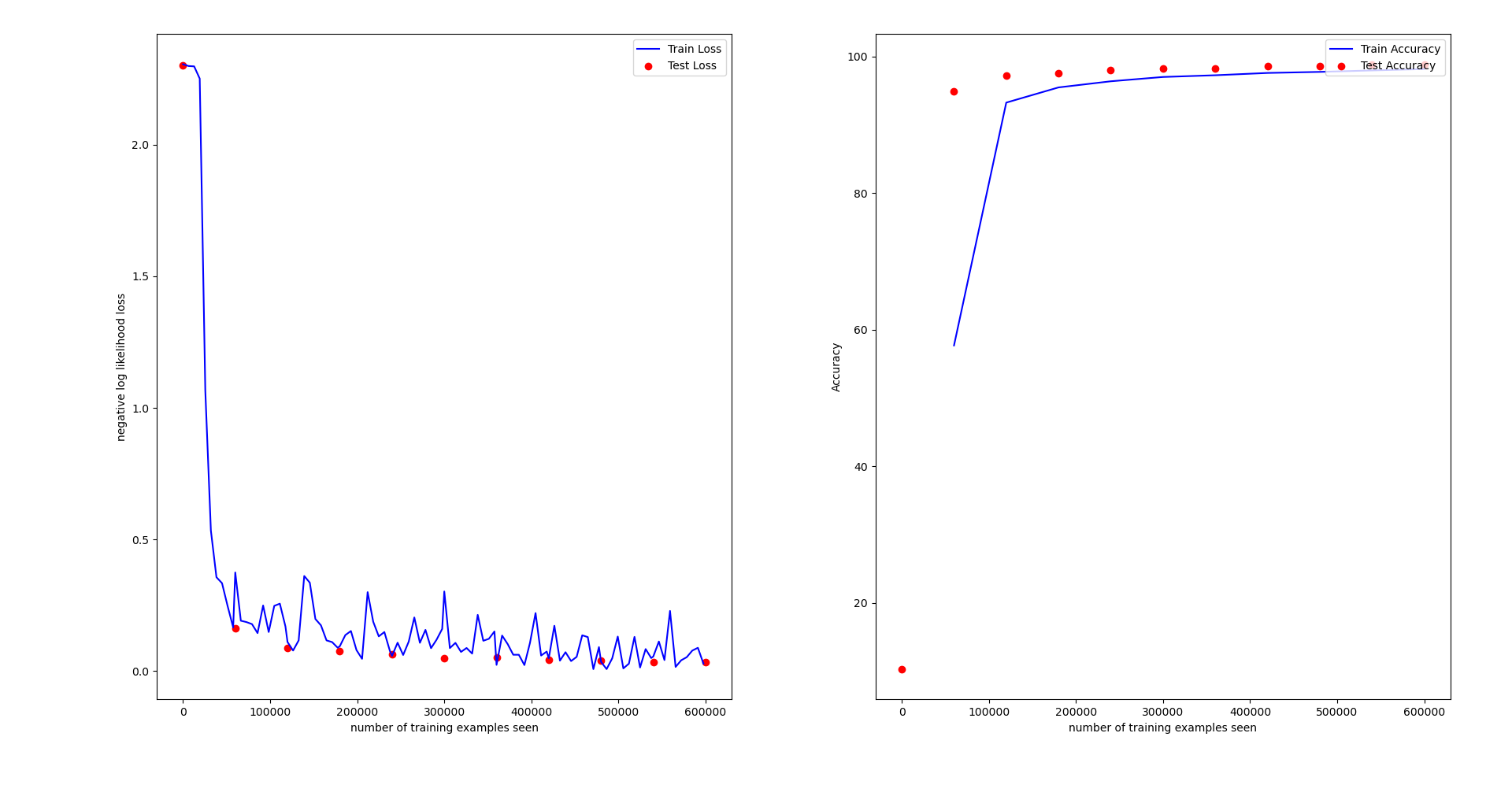
前 2 个 epoch 用 Adam, 后 8 个 epoch 用 SGDM: