参照老张的博客:http://www.cnblogs.com/imyalost/p/6229355.html
有4种参数化,今天只练习了第一种
1.CSV Data Set Config
2.随机数--函数助手
3.计数器:生成不重复的 固定格式的 一组字符串
4.随机变量:
5.用户参数
6.用户定义的变量
一、配置元件——CSV Data Set Config
总结:
1.通过配置元件进行参数化,提前准备好csvtest.dat文件,添加线程组并设置线程数的时候,文件中有多少行数据,线程数就设置为几,不然只执行一次
2.添加辅助元件,查看结果数,http信息头管理器(发送http请求时要携带的头部信息header)
3.多试错,多练习。
第一步,在测试计划下,右键-添加线程组,接着添加配置元件,如下图:
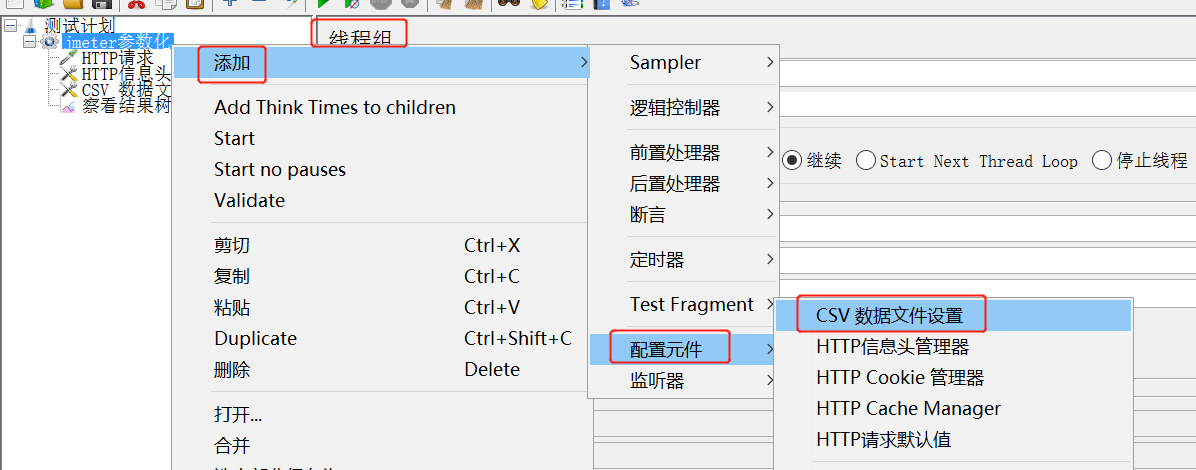
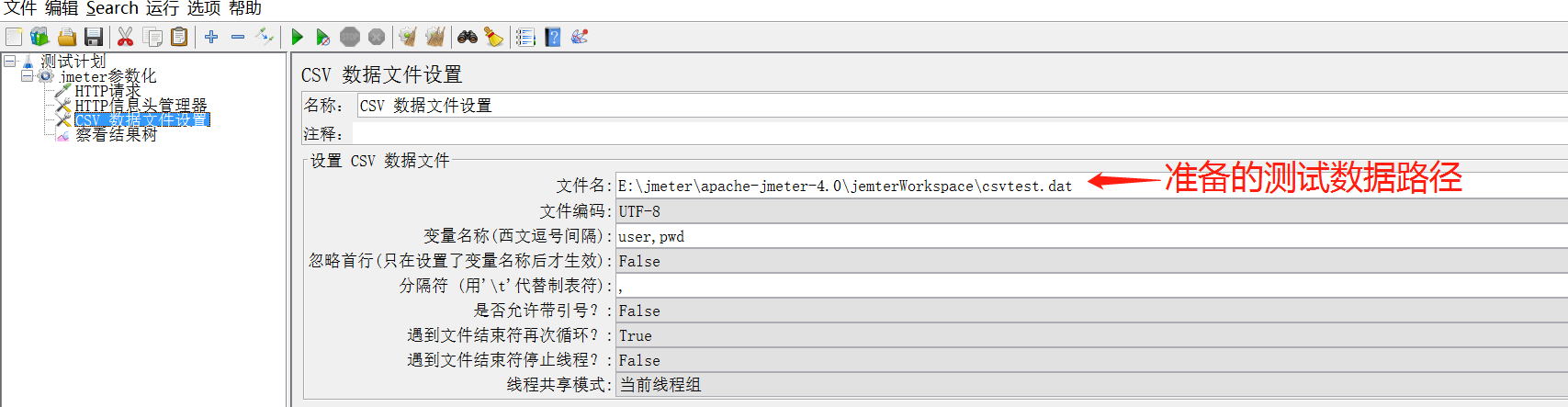
第二步,配置CSV数据文件设置
CSV数据文件设置:主要是文件编码、变量名称两栏
第三步:查看编写好的测试数据csvtest.dat
csvtest.dat:以前搞过应该遇到过坑,尽量存为UTF-8格式

第四步,设置http请求中的参数 ${user} ${pwd}
Http请求:参数的引用 ${user} ${pwd} 与csv数据文件设置一栏变量名称那保持一致

第五步,利用查看结果树元件,查看请求的成功与失败

-
Jmeter参数化的作用是什么?
参数化的作用主要是将我们访问服务器的信息可以通过变量进行封装,更加符合多用户的访问服务器的场景,未进行参数化之前,访问服务器只能通过URL或者变量设置固定的值,这就造成模拟的用户请求信息都是相同的,显示环境中是不可能的,Jmeter参数可以实现不同的用户用不同的请求信息访问服务器。
-
参数化可适用于哪些测试场景?
批量操作测试数据
回归测试
以下摘自:http://www.cnblogs.com/imyalost/p/6229355.html
主要是对CSV元件各个字段的说明
Filename:F:jmetercsvtest.dat文件名,保存参数化数据的文件目录,可选择相对或者绝对路径(建议填写相对路径,避免脚本迁移时需要修改路径); File encoding:UTF-8,F:jmetercsvtest.dat文件的编码格式,在保存时保存编码格式为UTF-8即可; Variable Names(comma-delimited):对对应参数文件每列的变量名,类似excel文件的文件头,起到标示作用,同时也是后续引用的标识符,建议采用有意义的英文标示; (如:有几列参数,在这里面就写几个参数名称,每个名称中间用分隔符分割,这里的 user,pwd,可以被利用变量名来引用:user,{pwd}; Delimitet:参数文件分隔符,用来在“Variable Names”中分隔参数,与参数文件中的分隔符保持一致即可; Allow quote data:是否允许引用数据,默认false,选项选为“true”的时候对全角字符的处理出现乱码 ; Recycle on EOF?:是否循环读取参数文件内容;因为CSV Data Set Config一次读入一行,分割后存入若干变量中交给一个线程,如果线程数超过文本的记录行数,那么可以选择从头再次读入; △ Ture:为true时,当已读取完参数文件内的测试用例数据,还需继续获取用例数据时,此时会循环读取参数文件数据(即:读取文件到结尾时,再重头读取文件); △False:为false时,若已至文件末尾,则不再继续读取测试数据;通常在“线程组线程数* 线程组循环次数>参数文件行数”时,选用false(即:读取文件到结尾时,停止读取文件); Stop thread on EOF?:当Recycle on EOF为False时(读取文件到结尾),停止进程,当Recycle on EOF为True时,此项无意义; △若为ture,则在读取到参数文件行末尾时,终止参数文件读取线程; △若为false,此时线程继续读取,但会请求错误,因此时读取的数据为EOF; Sharing mode:共享模式,即参数文件的作用域,有以下几种方式: △All threads:当前测试计划中的所有线程中的所有的线程都有效,默认; △Current thread group:当前线程组中的线程有效; △Current thread:当前线程有效;