在hadoop技术体系MapReduce中,Shuffle是比较重要的一个环节。对理解好Shuffle对往后的MapReduce调优将起到非常大的作用。
以下是我个人对MapReduce Shuffle的一些理解。
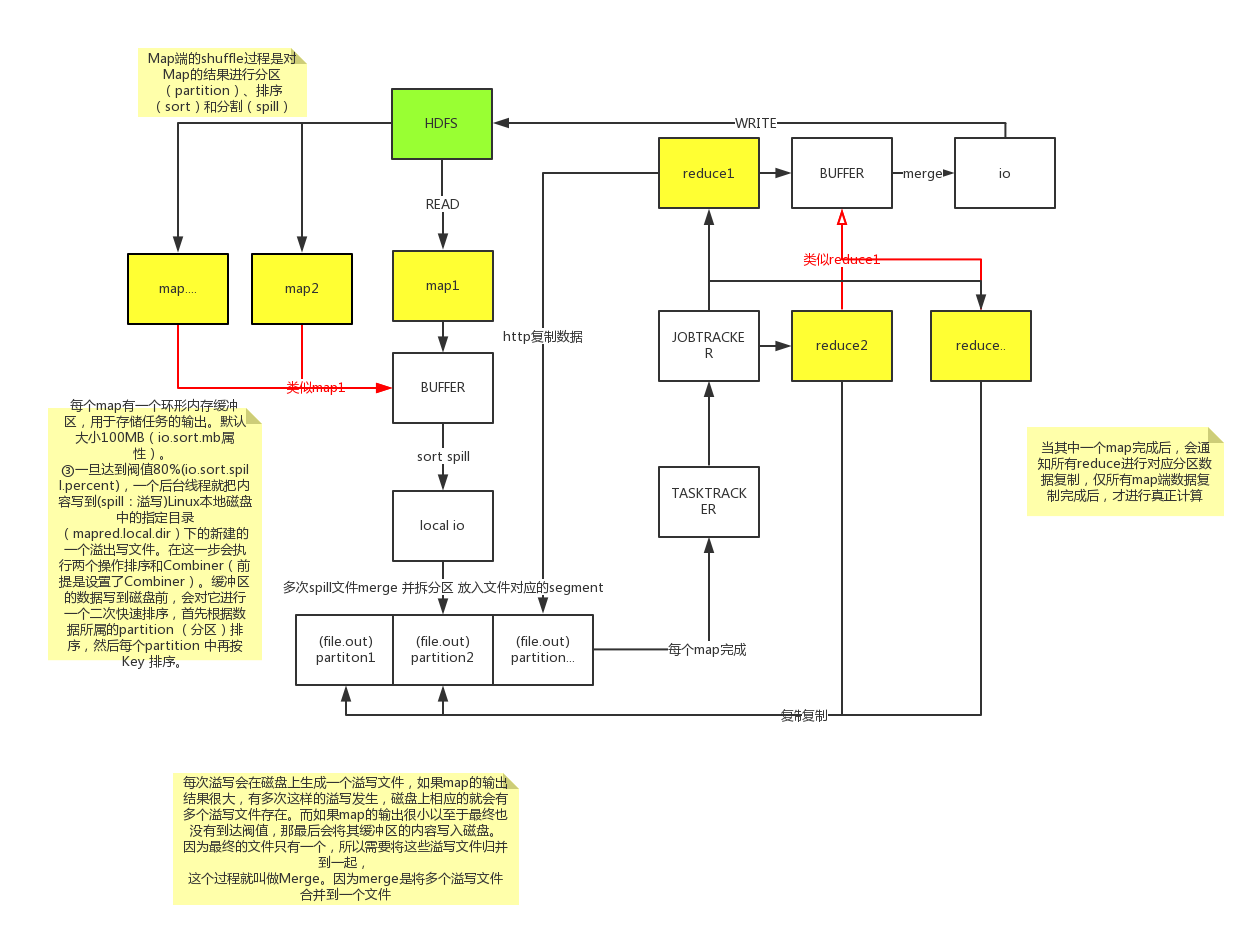
map task--数据格式化
程序会根据InputFormat将输入文件分割成splits,每个split会作为一个map task的输入,每个map task会有一个内存缓冲区,
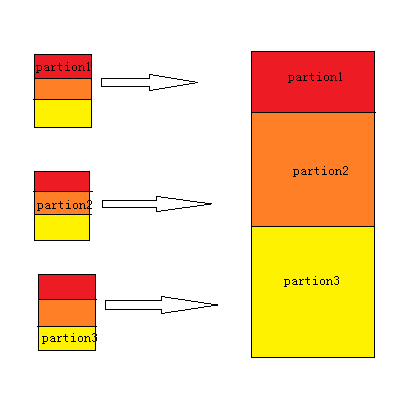
输入数据经过map阶段处理后的中间结果会写入内存缓冲区,并且决定数据写入到哪个partitioner(分区),当写入的数据到达内存缓冲
区的的阀值(默认是0.8),会启动一个线程将内存中的数据溢写入磁盘,同时不影响map中间结果继续写入缓冲区。在溢写过程中,
会对key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写
文件(最少有一个溢写文件),如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
reduce task--数据计算
当所有的map task完成后,每个map task会形成一个最终文件,并且该文件按区划分。reduce任务启动之前,一个map task完成后,
就会启动线程来拉取map结果数据到相应的reduce task,不断地合并数据,为reduce的数据输入做准备,当所有的map tesk完成后,
数据也拉取合并完毕后,reduce task 启动,最终将输出输出结果存入HDFS上。