主要介绍下完成了模型训练、评估之后的部署环节。
前言:之前舆情情感分析那一篇文章已经讲了如何使用ernie以及paddlehub来进行模型的训练和优化以及评估环节,所以接下来会讲下如何进行部署,进行实际的运用环节。在这里,用的是上次讲的舆情情感分析的模型。
将Fine-tune好的模型转化成paddleHub Module:
第1步,创建必要的目录与文件
创建一个finetuned_model_to_module的目录,并在finetuned_model_to_module目录下分别创建__init__.py、module.py,其中
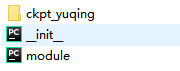
| 文件名 | 用途 |
|---|---|
| __init__.py | 空文件 |
| module.py | 主模块,提供Module的实现代码 |
| ckpt文件 | 利用PaddleHub Fine-tune得到的ckpt文件夹,其中必须包含best_model文件 |
第2步,编写Module处理代码
module.py文件为Module的入口代码所在,我们需要在其中实现预测逻辑。
step 2_1. 引入必要的头文件
1 from __future__ import absolute_import 2 from __future__ import division 3 from __future__ import print_function 4 5 import os 6 7 import numpy as np 8 from paddlehub.common.logger import logger 9 from paddlehub.module.module import moduleinfo, serving 10 import paddlehub as hub
step 2_2. 定义ERNIE_Finetuned类
module.py中需要有一个继承了hub.Module的类存在,该类负责实现预测逻辑,并使用moduleinfo填写基本信息。当使用hub.Module(name=”ernie_finetuned”)加载Module时,PaddleHub会自动创建ERNIE_Finetuned的对象并返回。
1 @moduleinfo( 2 name="ernie_finetuned", 3 version="1.0.0", 4 summary="ERNIE which was fine-tuned on the yuqing dataset.", 5 author="enhaofrank", 6 author_email="", 7 type="nlp/semantic_model") 8 class ERNIETinyFinetuned(hub.Module):
step 2_3. 执行必要的初始化
1 def _initialize(self, 2 ckpt_dir="ckpt_yuqing", 3 num_class=3,#3分类 4 max_seq_len=128, 5 use_gpu=False, 6 batch_size=1): 7 self.ckpt_dir = os.path.join(self.directory, ckpt_dir) 8 self.num_class = num_class 9 self.MAX_SEQ_LEN = max_seq_len 10 11 # Load Paddlehub ERNIE Tiny pretrained model 12 self.module = hub.Module(name="ernie") 13 inputs, outputs, program = self.module.context( 14 trainable=True, max_seq_len=max_seq_len) 15 16 self.vocab_path = self.module.get_vocab_path() 17 18 # Download dataset and use accuracy as metrics 19 # Choose dataset: GLUE/XNLI/ChinesesGLUE/NLPCC-DBQA/LCQMC 20 # metric should be acc, f1 or matthews 21 metrics_choices = ["acc"] 22 23 # For ernie_tiny, it use sub-word to tokenize chinese sentence 24 # If not ernie tiny, sp_model_path and word_dict_path should be set None 25 reader = hub.reader.ClassifyReader( 26 vocab_path=self.module.get_vocab_path(), 27 max_seq_len=max_seq_len, 28 sp_model_path=self.module.get_spm_path(), 29 word_dict_path=self.module.get_word_dict_path()) 30 31 # Construct transfer learning network 32 # Use "pooled_output" for classification tasks on an entire sentence. 33 # Use "sequence_output" for token-level output. 34 pooled_output = outputs["pooled_output"] 35 36 # Setup feed list for data feeder 37 # Must feed all the tensor of module need 38 feed_list = [ 39 inputs["input_ids"].name, 40 inputs["position_ids"].name, 41 inputs["segment_ids"].name, 42 inputs["input_mask"].name, 43 ] 44 45 # Setup runing config for PaddleHub Finetune API 46 config = hub.RunConfig( 47 use_data_parallel=False, 48 use_cuda=use_gpu, 49 batch_size=batch_size, 50 checkpoint_dir=self.ckpt_dir, 51 strategy=hub.AdamWeightDecayStrategy()) 52 53 # Define a classfication finetune task by PaddleHub's API 54 self.cls_task = hub.TextClassifierTask( 55 data_reader=reader, 56 feature=pooled_output, 57 feed_list=feed_list, 58 num_classes=self.num_class, 59 config=config, 60 metrics_choices=metrics_choices)
初始化过程即为Fine-tune时创建Task的过程。
NOTE:
-
执行类的初始化不能使用默认的__init__接口,而是应该重载实现_initialize接口。对象默认内置了directory属性,可以直接获取到Module所在路径。
-
使用Fine-tune保存的模型预测时,无需加载数据集Dataset,即Reader中的dataset参数可为None。
step 2_4. 完善预测逻辑
1 def predict(self, data, return_result=False, accelerate_mode=True): 2 """ 3 Get prediction results 4 """ 5 run_states = self.cls_task.predict( 6 data=data, 7 return_result=return_result, 8 accelerate_mode=accelerate_mode) 9 results = [run_state.run_results for run_state in run_states] 10 prediction = [] 11 for batch_result in results: 12 # get predict index 13 batch_result = np.argmax(batch_result, axis=2)[0] 14 batch_result = batch_result.tolist() 15 prediction += batch_result 16 return prediction
step 2_5. 支持serving调用
如果希望Module可以支持PaddleHub Serving部署预测服务,则需要将预测接口predcit加上serving修饰(@serving),接口负责解析传入数据并进行预测,将结果返回。
如果不需要提供PaddleHub Serving部署预测服务,则可以不需要加上serving修饰。
1 @serving 2 def predict(self, data, return_result=False, accelerate_mode=True): 3 """ 4 Get prediction results 5 """ 6 run_states = self.cls_task.predict( 7 data=data, 8 return_result=return_result, 9 accelerate_mode=accelerate_mode) 10 results = [run_state.run_results for run_state in run_states] 11 prediction = [] 12 for batch_result in results: 13 # get predict index 14 batch_result = np.argmax(batch_result, axis=2)[0] 15 batch_result = batch_result.tolist() 16 prediction += batch_result 17 return prediction
这样子,就得到了module
完成Module编写后,我们可以通过以下方式测试该Module:
调用方法
直接通过Hub.Module(directory=…)加载
1 import paddlehub as hub 2 import numpy as np 3 import datetime 4 ernie_finetuned = hub.Module(directory="finetuned_model_to_module")
1 data = [["美邦服饰经营范围新增日用口罩、食品经营等。原标题:美邦服饰经营范围新增日用口罩、食品经营等,天眼查数据显示,近日,上海美特斯邦威服饰股份有限公司发生工商变更,经营范围新增日用口罩(非医疗),食品经营(销售预包装食品);此外,公司新增许可项目,为第二类增值电信业务(依法须经批准的项目,经相关部门批准后方可开展经营活动,具体经营项目以相关部门批准文件或许可证件为准)。(文章来源:e公司)(责任编辑:DF358)"]] 2 inv_label_map = {0: '中性', 1: '利空', 2: '利好'} 3 predictions = ernie_finetuned.predict(data=data) 4 for index, text in enumerate(data): 5 print("%s predict=%s" % (data[index][0], inv_label_map[predictions[index]]))

这样就可以对新闻内容进行预测了!例如输入上面的一段内容,预测结果为中性。
接下来进行serving的调用方法:
第一步:启动预测服务
1 hub serving start -m ernie_finetuned
第二步:发送请求,获取预测结果
通过如下脚本既可以发送请求:
1 # coding: utf8 2 import requests 3 import json 4 5 6 # 待预测文本 7 texts = [["美邦服饰经营范围新增日用口罩、食品经营等。原标题:美邦服饰经营范围新增日用口罩、食品经营等,天眼查数据显示,近日,上海美特斯邦威服饰股份有限公司发生工商变更,经营范围新增日用口罩(非医疗),食品经营(销售预包装食品);此外,公司新增许可项目,为第二类增值电信业务(依法须经批准的项目,经相关部门批准后方可开展经营活动,具体经营项目以相关部门批准文件或许可证件为准)。(文章来源:e公司)(责任编辑:DF358)"], 8 ["近半数食品饮料股获机构推荐 杠杆资金提前入场7月份加仓超80亿元。最近30日内,有47家食品饮料行业公司获得评级机构192次推荐类评级,占业内公司总数的47%。数据显示,食品饮料行业中的51只两融标的的融资融券余额,从6月30日的346.07亿元,升至7月30日的426.49亿元,剧增80.43亿元,环比增长23.24%。其中,贵州茅台、五粮液两融余额增长最多,均超过20亿元。此外,包括伊利股份、山西汾酒、汤臣倍健等在内的9只食品饮料股两融余额增长均在亿元以上。(证券日报) 来源: 同花顺金融研究中心"]] 9 10 # key为'data', 对应着预测接口predict的参数data 11 data = {'data': texts} 12 13 # 指定模型为ernie_finetuned并发送post请求,且请求的headers为application/json方式 14 url = "http://127.0.0.1:8866/predict/ernie_tiny_finetuned" 15 headers = {"Content-Type": "application/json"} 16 r = requests.post(url=url, headers=headers, data=json.dumps(data)) 17 18 # 打印预测结果 19 print(json.dumps(r.json(), indent=4, ensure_ascii=False)
PaddleHub Serving 一键部署
命令行命令启动
开放接口
1 hub serving start --modules [Module1==Version1, Module2==Version2, ...] 2 --port XXXX 3 --use_gpu 4 --use_multiprocess 5 --workers
这样就可以用接口形式来访问,只要输入文本,就可以通过接口服务得到预测结果!
关闭接口
hub serving stop --port xxxx
总结:利用paddlehub将训练好的模型参数保存成module,之后在服务器端就可以直接使用这个模型的预测功能了,同时也可以通过接口的形式对外进行服务。
参考资料:
1、https://paddlehub.readthedocs.io/zh_CN/develop/tutorial/finetuned_model_to_module.html
---------------------------本博客所有内容以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢!---------------------
作者:enhaofrank
出处:https://www.cnblogs.com/enhaofrank/
中科院硕士毕业
现为深漂打工人