什么是样本不平衡
对于二分类问题,如果两个类别的样本数目差距很大,那么训练模型的时候会出现很严重的问题。举个简单的例子,猫狗图片分类,其中猫有990张,狗有10张,这时候模型只需要把所有输入样本都预测成猫就可以获得99%的识别率,但这样的分类器没有任何价值,它无法预测出狗。
类别不平衡(class-imbalance)就是指分类任务中正负样本数目差距很大的情况。生活中有很多类别不平衡的例子,如工业产品次品检测,次品样本数目远小于正品样本;欺诈问题,欺诈类观测在样本集中也只占据少数。因此,有必要了解解决类别不平衡的常用方法。
在实际的项目当中,数据往往是不平衡的,那么我们一半采用欠采样(undersampling)或者过采样(oversampling)来处理。
欠采样就是从多数类中删除样本,过采样就是向少数类中添加更多示例。

imbalanced-learn(imblearn)是一个用于解决不平衡数据集问题的 python 包,它提供了多种方法来进行欠采样和过采样。
a. 使用 Tomek Links 进行欠采样:
imbalanced-learn 提供的一种方法叫做 Tomek Links。Tomek Links 是邻近的两个相反类的例子。
在这个算法中,我们最终从 Tomek Links 中删除了大多数元素,这为分类器提供了一个更好的决策边界。
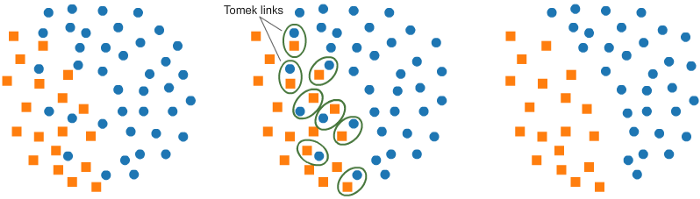
原理:如果有两个不同类别的样本,它们的最近邻都是对方,也就是A的最近邻是B,B的最近邻是A,那么A,B就是Tomek link。我们要做的就是讲所有Tomek link都删除掉。那么一个删除Tomek link的方法就是,将组成Tomek link的两个样本,如果有一个属于多数类样本,就将该多数类样本删除掉。
1 from imblearn.under_sampling import TomekLinks 2 tl = TomekLinks(return_indices=True, ratio= majority ) 3 X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. 使用 SMOTE 进行过采样:
对训练集中少数类进行“过采样”(oversampling),简单来说就是少数类中一个样本抽取多次,从而使正负样本数目接近,再进行学习。
在 SMOE(Synthetic Minority Oversampling Technique)中,我们在现有元素附近合并少数类的元素。
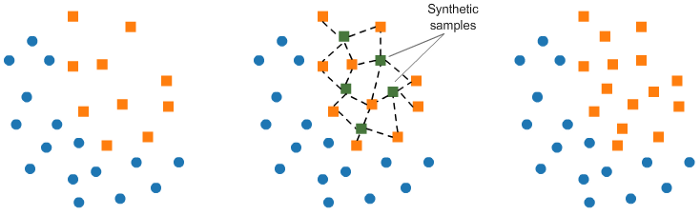
1 from imblearn.over_sampling import SMOTE 2 smote = SMOTE(ratio= minority ) 3 X_sm, y_sm = smote.fit_sample(X, y)
SMOTE全称是Synthetic Minority Oversampling Technique即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如图所示,算法流程如下。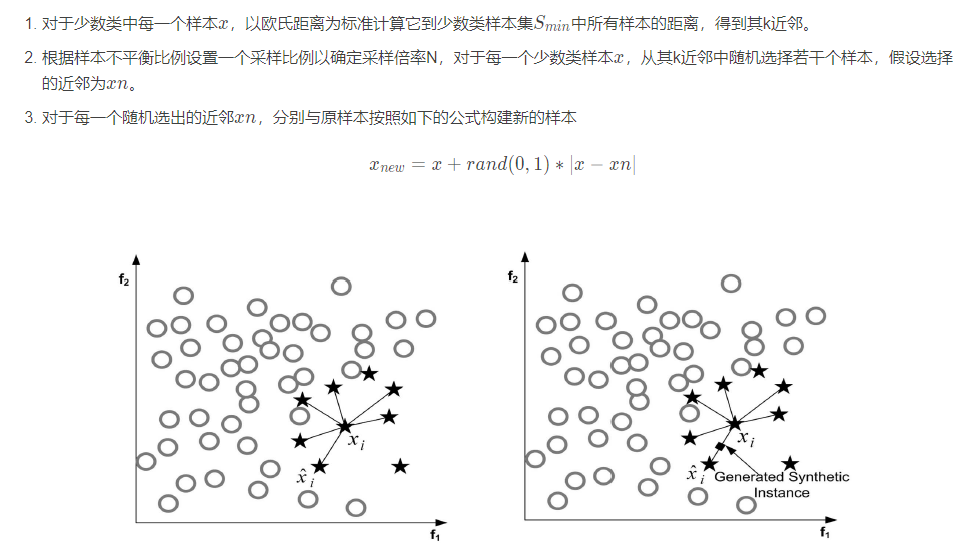
该算法主要存在两方面的问题:一是在近邻选择时,存在一定的盲目性。从上面的算法流程可以看出,在算法执行过程中,需要确定K值,即选择多少个近邻样本,这需要用户自行解决。从K值的定义可以看出,K值的下限是M值(M值为从K个近邻中随机挑选出的近邻样本的个数,且有M< K),M的大小可以根据负类样本数量、正类样本数量和数据集最后需要达到的平衡率决定。但K值的上限没有办法确定,只能根据具体的数据集去反复测试。因此如何确定K值,才能使算法达到最优这是未知的。
另外,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本集的分布边缘,则由此负类样本和相邻样本产生的“人造”样本也会处在这个边缘,且会越来越边缘化,从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善,但加大了分类算法进行分类的难度.
针对SMOTE算法存在的边缘化和盲目性等问题,很多人纷纷提出了新的改进办法,在一定程度上改进了算法的性能,但还存在许多需要解决的问题。
Han等人Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning在SMOTE算法基础上进行了改进,提出了Borderhne.SMOTE算法,解决了生成样本重叠(Overlapping)的问题该算法在运行的过程中,查找一个适当的区域,该区域可以较好地反应数据集的性质,然后在该区域内进行插值,以使新增加的“人造”样本更有效。这个适当的区域一般由经验给定,因此算法在执行的过程中有一定的局限性。
imbLearn 包中还有许多其他方法,可以用于欠采样(Cluster Centroids, NearMiss 等)和过采样(ADASYN 和 bSMOTE)。
参考资料
1、https://mp.weixin.qq.com/s/Qz4qNa5AoSluyyLC_ZSJdA
2、欠采样和过采样解决分类样本不平衡问题 - Js2Hou - 博客园 (cnblogs.com)
3、python数据预处理 :样本分布不均的解决(过采样和欠采样)_python_脚本之家 (jb51.net)
4、(15 封私信 / 41 条消息) 如何解决兼具类不平衡,类别较多的多分类,样本不足的问题? - 知乎 (zhihu.com)