【主题】
在某个大型网站中,有张保存新闻记录的表,数据库量5万左右(其实不算大),网站页面中的新闻都是从该表中动态生产的,同时还有80~90家的通发网站中的新闻也是从该表中动态生产的。导致该表的访问量非常地的大,尤其是在搞活动时网站几乎崩溃。针对这种情况,对网站进行优化,并阐述优化中发现或可能导致死循环的情况。
【声明】
该文已经博客园上发布过,但在修改网友提出的问题时,出了问题。在这里按照上篇和下篇进行发布。dudu,若果我的行为不妥,请删除该文。谢谢!
【网站框架】IIS6.0+MS SQL 2000 +ASP3.0+win 2003
【思路】
1、 利用windows 任务管理器,查看进程cup占用情况。如果数据库进程(sqlservr.exe)占用的cup很高的话,一般来说要在数据库优化(这里不谈优化工具)上下功夫;如果IIS 进程(w3pw.exe)占用的cup很高(高的有点离谱,甚至是瞬间很高)的话,就要看看代码了,有死循环的嫌疑很大。
2、 数据库中的优化主要从建立索引,查询语句,存储过程,ASP代码等方面进行优化。
3、 IIS方面可以建立应用程序池,实现优化。
4、 本文不谈服务器硬件升级。
【实战】
1、 打开服务器的任务管理器
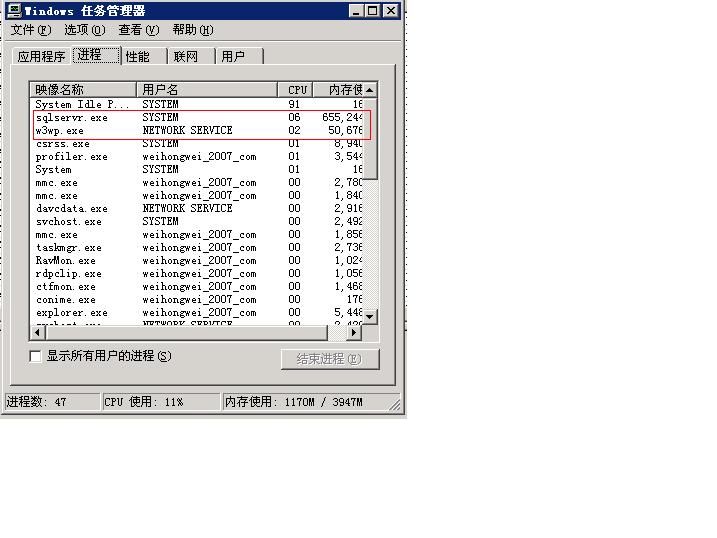 假设:sqlservr.exe占用的cup非常的高,这时的服务器cup达到100%
假设:sqlservr.exe占用的cup非常的高,这时的服务器cup达到100%
数据库优化攻略:
A、 先从数据库本身着手,建立索引。建立索引这一个话题,就可以写一篇很长的文章。
(1) 索引的结构:
可以把索引理解为一种特殊的目录。微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。
在网看到一篇文章讲聚类索引与非聚类索引,很通俗:我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。
我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。
我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
(2)聚类与非聚类索引使用的一般规则:
|
动作描述 |
使用聚集索引 |
使用非聚集索引 |
|
列经常被分组排序 |
应 |
应 |
|
返回某范围内的数据 |
应 |
不应 |
|
一个或极少不同值 |
不应 |
不应 |
|
小数目的不同值 |
应 |
不应 |
|
大数目的不同值 |
不应 |
应 |
|
频繁更新的列 |
不应 |
应 |
|
外键列 |
应 |
应 |
|
主键列 |
应 |
应 |
|
频繁修改索引列 |
不应 |
应 |
(3)根据实际情况,不要认为主键应该使用聚类索引(MS SQL 把主键设为默认的聚类索引)。通常,我们会在每个表中都建立一个ID列,以区分每条数据,并且这个ID列是自动增大的,步长一般为1。此时,如果我们将这个列设为主键,SQL SERVER会将此列默认为聚集索引。这样做可以让您的数据在数据库中按照ID进行物理排序,但在实际应用中,因为ID号是自动生成的,我们并不知道每条记录的ID号,所以我们很难在实践中用ID号来进行查询。这就使让ID号这个主键作为聚集索引成为一种资源浪费。
(4)SQL语句优化的实例:
SARG的定义:用于限制搜索的一个操作,因为它通常是指一个特定的匹配,一个值得范围内的匹配或者两个以上条件的AND连接。形式如下:
列名 操作符 <常数 或 变量>或<常数 或 变量> 操作符列名
1)、如果在表中的name自段上建立索引,在用like进行模糊查询
请使用name like '张%'
不用使用:name like '%张%'
字符串的开始使用配符%,索引将无法使用。
2)、or语句的代价是引起全表扫描
Name='张三' and age > 20
Name='张三' or age > 20
第二条语句将引起全表的扫描。请注意使用,尽量避免。
3)、不用写select * from table 这样的语句
如果只需名称和年龄,要养成使用select name ,age from table的习惯。
4)、请谨慎地使用嵌套查询
对于 select name from table where age in (select age from table)之类的语句,将引起全表的扫描,索引也就没有意义了。
5)、在实现记录分页时,请利用top
实现分页的经典语句:
SELECT TOP PAGESIZE NEWSTITLE
FORM NEWSINFO WHERE NEWSID NOT IN
(SELECT TOP (PAGE-1)* PAGESIZE NEWSID FROM NEWSINFO
WHERE Auditing=1 and NEWSBREED='企业新闻' order by NEWSID DESC)
AND Auditing=1 and NEWSBREED='企业新闻' order by NEWSID DESC
其中:PAGE表示当前页数,PAGESIZE表示页的大小;这里利用了NOT IN,但总比一次读取全部的记录要好。
针对本人的实例还有一个更好的方案:因为NEWSID字段是自增字段,对于NOT IN 进行如下的改造,比不影响结果。但速度提高了很多
SELECT TOP PAGESIZE NEWSTITLE
FORM NEWSINFO WHERE NEWSID >
(SELECT MAX(NEWSID) FROM (SELECT TOP (PAGE-1) * PAGESIZE NEWSID FROM NEWSINFO WHERE Auditing=1 and NEWSBREED='企业新闻' order by NEWSID ) AS TB)AND Auditing=1 and NEWSBREED='企业新闻' order by NEWSID
6)、复合索引的前导列,是最经常在查询条件中使用的
比如在 PUTDT,AUTHORNAME列上建立了复合的索引,其中PUTDT为前导列
对于如下的三条语句:
SELECT PUTDT, AGE FROM USER_NEWS WHERE PUTDT > '2007-1-16'
SELECT PUTDT, AGE FROM USER_NEWS WHERE PUTDT>'2007-1-16'and AUTHORNAME='DAVID'
SELECT PUTDT, AGE FROM USER_NEWS WHERE AUTHORNAME='DAVID'
说明:
第一条语句速度最快,其次为第二条,第三条最慢。
第三条中索引是无效的。所以建立复合索引,要注意细节。
第二条中条件语句的顺序不影响性能,"查询优化器"来做优化工作
7)、如果COUTN(*)只用于获取行数,可以使用ROWSET COUNT 。
8)、检查SQL 语句性能的方法
A、打开"查询分析器",打开"查询"菜单,点击"显示查询计划",执行下面的语句
select title,price from titles where title_id in
(select title_id from sales where qty>30)
select title,price from titles where exists
(select * from sales where sales.title_id=titles.title_id and qty>30)
查看查询计划:
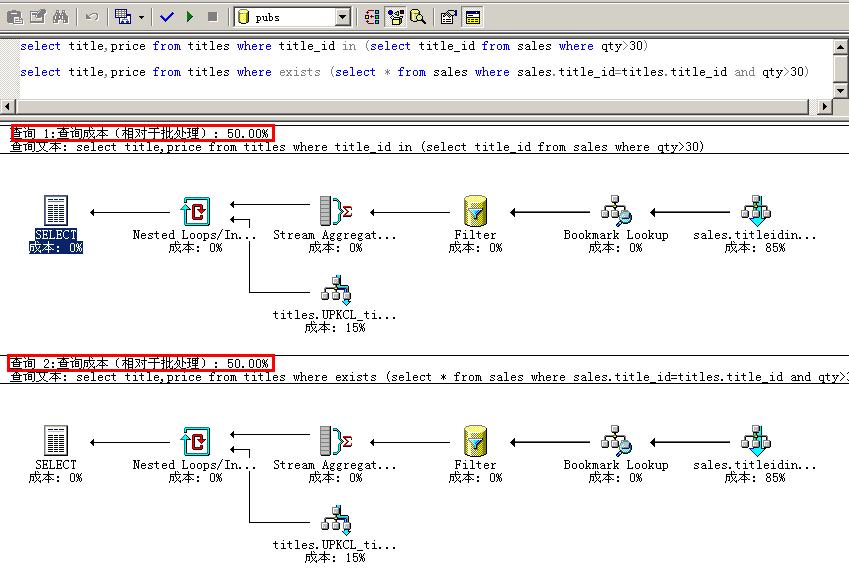
从套红的部分看,这两条语句性能是一样的,也验证了IN 和 EXISTS是等效的。
B、在各个select语句前加:declare @d datetime set @d=getdate() 并在select语句后加:select [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())
可以知道SQL语句执行需要的毫秒数。
B、采用了以上的优化以后,发现数据库的进程占用的cup有所下降,但还是偏高。
请使用MS SQL事件探查器,跟踪MS SQL的请求
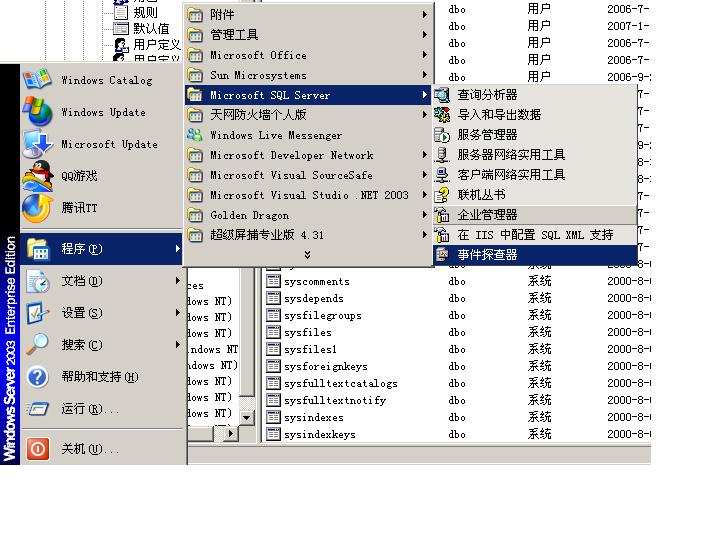
打开“事件探查器”,新建“跟踪"
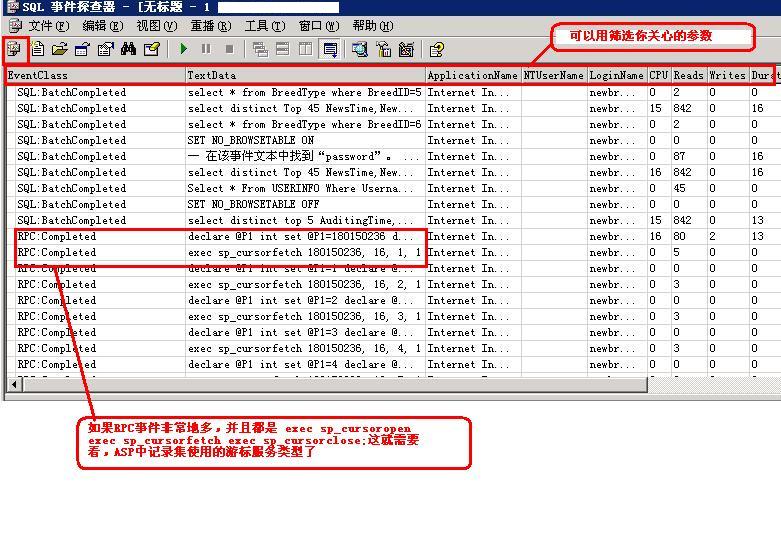
1)、如果“事件探查器”中,有很多的RPC事件,并且执行sp_cursoropen sp_cursorfetch
Sp_cursorclose ,说明在使用ASP数据集对象时,使用的游标服务不合适。
请使用“客户端游标”,代码:RS.CursorLocation=3 其中RS为数据集对象,3表示客户端游标,不要使用adUseClient,有时会有问题。
2)、数据集对象的操作要注意的地方
RS.Open一般建议:
rs.open sql,conn,0,1 顺序遍历,不需要定位跳转,不需要添加删除更新操作,速度最快
rs.open sql,conn,1,3 遍历,可以进行更新操作,但不能进行定位跳转
rs.open sql,conn,2,3 可以进行所有操作,可以跳转
说明:第三个参数表示游标的类型,第四个参数表示锁类型
可以参考:http://www.cnblogs.com/David-weihw/archive/2007/01/10/616936.html
经过以上的优化,一般应该可以解决MS SQL进程占用cup过高的情况。如果还不行的话,就严重了,请重新设计数据库存储结构去吧。