GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类、回归、排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的。 本文尝试一步一步梳理GB、GBDT、xgboost,它们之间有非常紧密的联系,GBDT是以决策树(CART)为基学习器的GB算法,xgboost扩展和改进了GDBT,xgboost算法更快,准确率也相对高一些。
1. Gradient boosting(GB)
机器学习中的学习算法的目标是为了优化或者说最小化loss Function, Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:

GB算法的思想很简单,关键是怎么生成h(x)?
,这就是常说基于残差的学习。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题![]() 残差和负梯度也是相同的。
残差和负梯度也是相同的。 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量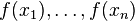 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
1.初始化模型为常数值:
1.计算伪残差
生成基学习器
4.更新模型
2. Gradient boosting Decision Tree(GBDT)
GB算法中最典型的基学习器是决策树,尤其是CART,正如名字的含义,GBDT是GB和DT的结合。要注意的是这里的决策树是回归树,GBDT中的 决策树是个弱模型,深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些 GBDT的实现加入了随机抽样(subsample 0.5<=f <=0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。因此GBDT实际的核心问题变成怎么基于 使用CART回归树生成?
使用CART回归树生成?
CART分类树在很多书籍和资料中介绍比较多,但是再次强调GDBT中使用的是回归树。作为对比,先说分类树,我们知道CART是二叉树,CART分 类树在每次分枝时,是穷举每一个feature的每一个阈值,根据GINI系数找到使不纯性降低最大的的feature以及其阀值,然后按照 feature<=阈值,和feature>阈值分成的两个分枝,每个分支包含符合分支条件的样本。用同样方法继续分枝直到该分支下的所有样 本都属于统一类别,或达到预设的终止条件,若最终叶子节点中的类别不唯一,则以多数人的类别作为该叶子节点的性别。回归树总体流程也是类似,不过在每个节 点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好 的分割点,但衡量最好的标准不再是GINI系数,而是最小化均方差--即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一 (这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。下面所有的内容来自原始paper,包括公式。
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
第t次的loss:
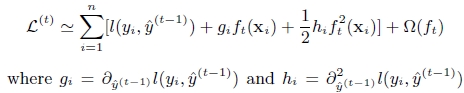
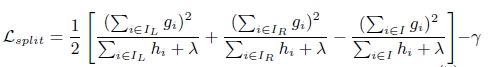
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
- 在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
- xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。
- 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
- 按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer,然后再计算,提高算法的效率。
- xgboost 还考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法,尽可能的提高算法的效率。
参考资料:
维基百科 Gradient boosting
XGBoost: A Scalable Tree Boosting System
陈天奇的slides
xgboost导读和实战.pdf