支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
具体原理:
1. 在n维空间中找到一个分类超平面,将空间上的点分类。如下图是线性分类的例子。
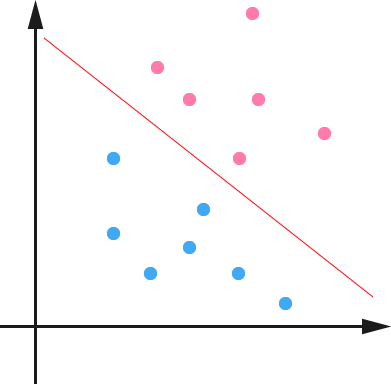
2. 一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。SVM就是要最大化这个间隔值。而在虚线上的点便叫做支持向量Supprot Verctor。


3. 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如下图);
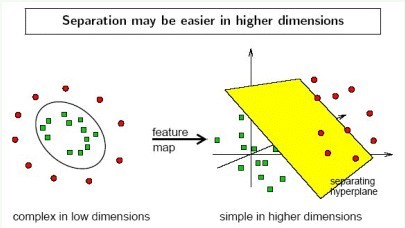
3. 线性不可分映射到高维空间,可能会导致维度大小高到可怕的(19维乃至无穷维的例子),导致计算复杂。核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
4.使用松弛变量处理数据噪音

SVM的优点:
1. SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
2. 假设现在你是一个农场主,圈养了一批羊群,但为预防狼群袭击羊群,你需要搭建一个篱笆来把羊群围起来。但是篱笆应该建在哪里呢?你很可能需要依据牛群和狼群的位置建立一个“分类器”,比较下图这几种不同的分类器,我们可以看到SVM完成了一个很完美的解决方案。

这个例子从侧面简单说明了SVM使用非线性分类器的优势,而逻辑模式以及决策树模式都是使用了直线方法。

摘抄自http://blog.csdn.net/v_july_v/article/details/7624837。