为了记录在竞赛中入门深度学习的过程,我开了一个新系列【从传统方法到深度学习】。
1. 问题
Kaggle竞赛Bag of Words Meets Bags of Popcorn是电影评论(review)的情感分析,可以视作为短文本的二分类问题(正向、负向)。标注数据集长这样:
id sentiment review
"2381_9" 1 ""The Classic War of the Worlds" by Timothy Hines is a very entertaining film that obviously goes to great effort and lengths to faithfully recreate H. G. Wells' classic book. Mr. Hines succeeds in doing so. ..."
"2486_3" 0 "What happens when an army of wetbacks, towelheads, and Godless Eastern European commies gather their forces south of the border? Gary Busey kicks their butts, of course. Another laughable example of Reagan-era cultural fallout, Bulletproof wastes a decent supporting cast headed by L Q Jones and Thalmus Rasulala."
评价指标是AUC。因此,在测试数据集上应该给出概率而不是类别;即为predict_proba而不是predict:
# random frorest
result = forest.predict_proba(test_data_features)[:, 1]
# not `predict`
result = forest.predict(test_data_features)
采用BoW特征、RF (random forest)分类器,预测类别的AUC为0.84436,预测概率的AUC则为0.92154。
2. 分析
传统方法
传统方法一般会使用到两种特征:BoW (bag of words),n-gram。BoW忽略了词序,只是单纯对词计数;而n-gram则是考虑到了词序,比如bigram词对"dog run"、"run dog"是两个不同的特征。BoW可以用CountVectorizer向量化:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(analyzer="word", tokenizer=None, preprocessor=None,
stop_words=None, max_features=5000)
train_data_features = vectorizer.fit_transform(clean_train_reviews)
在一个句子中,不同的词重要性是不同的;需要用TFIDF来给词加权重。n-gram特征则可以用TfidfVectorizer向量化:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=40000, ngram_range=(1, 3), sublinear_tf=True)
train_x = vectorizer.fit_transform(clean_train_reviews)
使用unigram、bigram、trigram特征 + RF分类器,AUC为0.93058;如果改成LR分类器,则AUC为0.96330。
深度学习
竞赛tutorial给出用word2vec词向量特征来做分类,并两个生成特征思路:
- 对每一条评论的所有词向量求平均,将其平均值作为改评论的特征;
- 对训练的词向量做聚类,然后对评论中的词类别进行计数,把这种bag-of-centroids作为特征。
把生成这种特征喂给分类器,进行分类。但是,这种方法的AUC不是太理想(在0.91左右)。无论是做平均还是聚类,一方面丢失了词向量的特征,另一方面忽略了词序还有词的重要性。因此,分类效果不如tfidf化的n-gram。
大神Mikolov在推出word2vec之后,又鼓捣出了doc2vec(gensim有实现)。简单地说,就是可以把一段文本变成一个向量。与word2vec不同的是,参数除了doc对应的词列表外,还有类别(TaggedDocument)。结果证明doc2vec的效果还不如word2vec生成特征,AUC只有0.87915。
doc2vec = Doc2Vec(sentences, workers=8, size=300, min_count=40,
window=10, sample=1e-4)
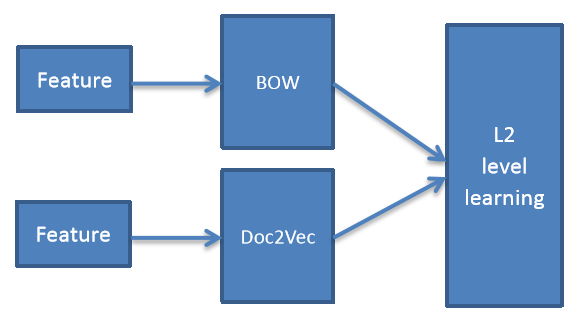
pangolulu尝试把BoW与doc2vec做ensemble,采用stacking的思路——L1层BoW特征做LR分类、doc2vec特征做RBF-SVM分类,L2层将L1层的预测概率组合成一个新特征,喂给LR分类器;多次迭代后求平均。ensemble结构图如下:
以上所有方法的AUC对比如下:
| 特征 | 分类 | AUC |
|---|---|---|
| BoW | RF | 0.92154 |
| (1,3) gram, tfidf | LR | 0.96330 |
| (1,3) gram, tfidf | RF | 0.93058 |
| word2vec + avg | RF | 0.90798 |
| word2vec + cluster | RF | 0.91485 |
| doc2vec | RF | 0.87915 |
| doc2vec | LR | 0.90573 |
| BoW, doc2vec | ensemble | 0.93926 |
3. 参考资料
[1] Zygmunt Z., Classifying text with bag-of-words: a tutorial.
[2] Michael Czerny, Modern Methods for Sentiment Analysis.