用python爬取知乎的热榜,获取标题和链接。
环境和方法:ubantu16.04、python3、requests、xpath
1.用浏览器打开知乎,并登录
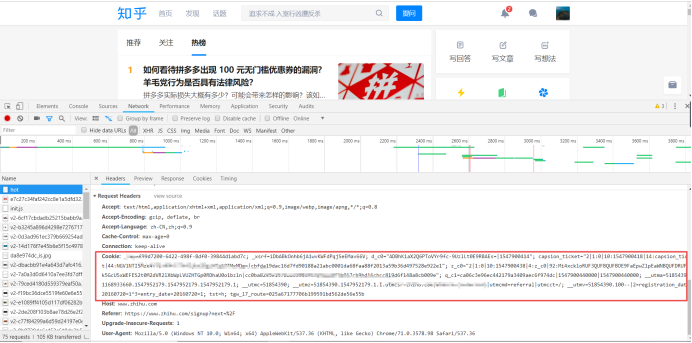
2.获取cookie和User—Agent
3.上代码
1 import requests 2 from lxml import etree 3 4 def get_html(url): 5 headers={ 6 'Cookie':'你的Cookie', 7 #'Host':'www.zhihu.com', 8 'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36' 9 } 10 11 r=requests.get(url,headers=headers) 12 13 if r.status_code==200: 14 deal_content(r.text) 15 16 def deal_content(r): 17 html = etree.HTML(r) 18 title_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/h2') 19 link_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/@href') 20 for i in range(0,len(title_list)): 21 print(title_list[i].text) 22 print(link_list[i]) 23 with open("zhihu.txt",'a') as f: 24 f.write(title_list[i].text+' ') 25 f.write(' 链接为:'+link_list[i]+' ') 26 f.write('*'*50+' ') 27 28 def main(): 29 url='https://www.zhihu.com/hot' 30 get_html(url) 31 32 main()
4.爬取结果
