GOOD POST
https://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
Epoch
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次Epoch。所有训练样本在神经网络中都进行了一次正向传播和一次反向传播。一个Epoch就是讲所有训练样本训练一次的过程。
一个Epoch训练样本数量可能太过庞大,就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
一个epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程。由于一个epoch常常太大,计算机无法负荷,我们会将它分成几个较小的batches。那么,为什么我们需要多个epoch呢?我们都知道,在训练时,将所有数据迭代训练一次是不够的,需要反复多次才能拟合收敛。在实际训练时,我们将所有数据分成几个batch,每次送入一部分数据,梯度下降本身就是一个迭代过程,所以单个epoch更新权重是不够的。
下图展示了使用不同个数epoch训练导致的结果。

可见,随着epoch数量的增加,神经网络中权重更新迭代的次数增多,曲线从最开始的不拟合状态(右侧图),慢慢进入优化拟合状态(中间图),最终进入过拟合(左侧图)。
因此,epoch的个数是非常重要的。那么究竟设置为多少才合适呢?恐怕没有一个确切的答案。对于不同的数据集来说,epoch数量是不同的。但是,epoch大小与数据集的多样化程度有关,多样化程度越强,epoch应该越大。
例如,训练数据集总共有1000个样本。若batch_size=10,那么训练完全体样本集需要100次迭代,1次epoch。
例如:训练样本10000条,batchsize设置为20,将所有的训练样本在同一个模型中训练5遍,则epoch=5,batchsize=20, iteration=10000/20=500
Batch Size
所谓Batch就是每次送入网络中训练的一部分数据,而Batch Size就是每个batch中训练样本的数量。上文提及,每次送入训练的不是所有数据而是一小部分数据,另外,batch size 和batch numbers不是同一个概念。
Batch size大小的选择也至关重要。为了在内存效率和内存容量之间寻求最佳平衡,batch size应该精心设置,从而最优化网络模型的性能及速度。
batchsize太大或者太小都不好,如果该值太小,假设batchsize=1,每次用一个数据进行训练,如果数据总量很多时(假设有十万条数据),就需要向模型投十万次数据,完整训练完一遍数据需要很长的时间,训练效率很低;如果该值太大,假设batchsize=100000,一次将十万条数据扔进模型,很可能会造成内存溢出,而无法正常进行训练。
所以,我们需要设置一个合适的batchsize值,在训练速度和内存容量之间寻找到最佳的平衡点。
几点经验:
相对于正常数据集,如果Batch_Size过小,训练数据就会非常难收敛,从而导致欠拟合。增大Batch_Size,相对处理速度会变快,同时所需内存容量增加。为了达到更好的训练效果,一般在Batchsize增加的同时,我们需要对所有样本的训练次数(也就是后面要讲的epoch)增加,以达到最好的结果。增加Batchsize的同时,一般会让所有样本的训练次数增加,这同样会导致耗时增加,因此需要寻找一个合适的Batchsize值,在模型总体效率和内存容量之间做到最好的平衡。
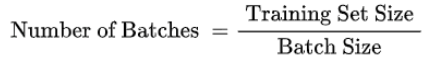
Iterations
所谓 iterations 就是完成一次epoch所需的batch个数。
刚刚提到的,batch numbers 就是iterations。
简单一句话说就是,我们有2000个数据,分成4个batch,那么batch size就是500。运行所有的数据进行训练,完成1个epoch,需要进行4次iterations。
用mnist 数据集举例:
mnist 数据集有60000张图片作为训练数据,假设现在选择 Batch_Size = 100对模型进行训练。
-
每个 Epoch 要训练的图片数量:60000 (训练集上的所有图像)
-
训练集具有的 Batch 个数:60000/100=600
-
每个 Epoch 需要完成的 Batch 个数:600
-
每个 Epoch 具有的 Iteration 个数:600(完成一个Batch训练,相当于参数迭代一次)
-
每个 Epoch 中发生模型权重更新的次数:600
-
训练 10 个Epoch后,模型权重更新的次数:600*10=6000
-
不同Epoch的训练,其实用的是同一个训练集的数据。第1个Epoch和第10个Epoch虽然用的都是训练集的图片,但是对模型的权重更新值却是完全不同的。因为不同Epoch的模型处于代价函数空间上的不同位置,模型的训练代越靠后,越接近谷底,其代价越小。
链接:
https://baijiahao.baidu.com/s?id=1637024752671211788&wfr=spider&for=pc