摘要
本文档是关于RuleML 1.0的入门(Rule Markup Language,他也是一种规则建模语言Rule Modeling Language或叫做 规则元逻辑Rule MetaLogic)。RuleML被用于在web上共享和发布基于XML的规则。 RuleML构成一个分层的规则子语言(rule sublanguages)家族,本入门的焦点主要集中在Datalog和Horn logic。这些子语言的XML可以通过OrdLab trees可视化的呈现,例如:商业策略领域、折扣策略等。
RuleML组织
RuleML作为一个非营利组织,一直驱动着web规则的研究,建立互通其他Web规则语言之间的桥梁,与标准合作,并与落实到行业实践中。
RuleML作为一个事实上的语言标准包括:慎重的RuleML V1.0,其中:Datalog和子语言Horn logic将在这里着重介绍。
Datalog
Datalog[CGT89] 是一种轻量级推演数据库系统,是许多规则语言的核心,是最接近带有递归视图的关系数据库。这里介绍的是RuleML中的Datalog。
- (Function-free)Horn logic子语言
- SQL和Prolog语言的交集
- 程序逻辑能够代表关系数据库中信息,包括(递归的)视图
- (fact)事实:关系数据库中的表的行
- (rule)规则:用视图隐含表的定义
Datalog 的Horn logic (function-free)子语言是RuleML的语义基础。Datalog是SQL与Prolog的交集的语言。因此,它被看作是程序逻辑能够代表关系数据库中信息,包括(递归的)视图。也就是说,在Datalog中,我们可以定义事实,对应明确的关系数据库中的表的行(客观事实的定义),以及规则,对应于用视图(内在的定义)隐含表的定义。
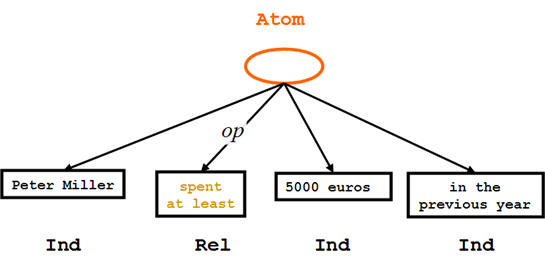
顾客花费的事实 – OrdLab Tree
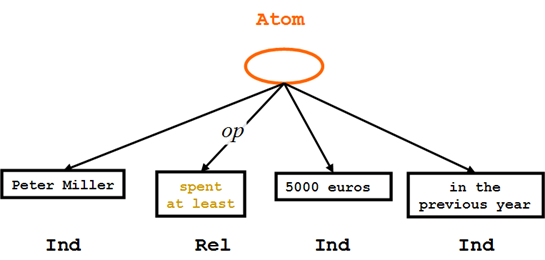
"Peter Miller spent at least 5000 euros in the previous year."
Peter在去年至少花了5000欧元
Datalog RuleML,作为一种标记语言,可以方便地进行序列化相关信息,其中所有的列内容都是自然语言的短语。为了解释Datalog功能,我们将开发一个小例子,以真实的自然语言的业务规则在RuleML中描述。这个例子对应Terry Moriarty的业务规则分类中的「资格」类别。
这种自然语言句子的结构可以用可视化的一种解析树语言,称之为OrdLab Tree (Order-Labeled)。在图中有标签(tags)和标注(label)他们都是内部节点(椭圆形,类似RDF里面那种匿名资源),例如:'Atom'(Atom公式);叶子节点(矩形,类似RDF里的那种文字,含PCDATA),例如:'Rel'(关联常量),'Ind'(独立常量),或'Data'(数据常量)。"Atom"节点连接到"Rel"节点的线条被标记为'op',这样与参数区分开来。其中间操作的顺序是模仿原来自然语言的排序。
OrdLab trees 介绍在:"A Web Data Model Unifying XML and RDF" http://www.dfki.uni-kl.de/~boley/xmlrdf.html
RuleML Datalog 事实(Fact)
<Atom> <Ind>Peter Miller</Ind> <op><Rel>至少花费</Rel></op> <Ind>5000欧元</Ind> <Ind>在去年</Ind> </Atom>
"至少花费"与以下三种发生关联: Peter Miller、5000欧元、去年(时间参考),他们可以被记录成为一个Datalog RuleML事实。在这里,XML标签 - 类似于非终端的语言 - 直接在句子上标注PCDATA(Parsed Character Data) - 类似语言的最终形式:
从外到内的标签,我们发现"至少花费"是标注成关系名(表名):<Rel>至少花费</Rel>。在同一级,有三个短语"Peter Miller"、"5000欧元"、"在去年"是标注成独立常量。关系有三个参数(列),顺序如下:<Ind>Peter Miller</Ind>, <Ind>5000欧元</Ind>, 和<Ind>去年</Ind>。整个应用程序的关系构成了一个Atom公式,标记由<Atom>... </Atom>。
Datalog特性
- 查询必须保证参数和关系描述的精确
- 短语细化需要Horn logic RuleML
- 关系有一个变量(有限的)是数字型的参数(可以是多个)
- RDF和OWL的二元情况
- RuleML结合SWRL中的OWL
- OrdLab图的每条边可以看作是一个二元描述语
- SQL风格的null可以通过<Ind/>表示
在上述Datalog的标记,这三个顶级"至少花费"的参数没有进一步分析,他们只是被视为独立常量。用于识别目的,它们和关系本身,将需要由一个精确的查询,它要能够检索上述的事实(如下图所示,这查询如果是规则的一部分)。每个步骤都使用RuleML标记,逐步的细化分析,可以表现出内部结构、自然语言中关系的意义,从Datalog至Hornlog (function-ful) RuleML他们都有三个基本参数为进一步使用:辅助、参数、处理。
请注意,Datalog RuleML中的一个关系可以是n元(多价),即可以是变量,但参数的个数是有限的,如n= 0,1,2,3,...一个Datalog仅允许一元(一价的)和二元(二价的)的关系是一个重要的特殊情况,例如为RuleML结合SWRL中的OWL。虽然上面的标记使用一个三元"至少花费"关系,它也可以被减少到3个二元关系,他们从独立变量分离出来的,这就代表了一个三元关系,所建议的上述RDF面向XML的可视化和解释可查询W3C Working Group Note。然而,为了保持对数据库和SQL的关系模型的表现力,以及Prolog语言中,Datalog RuleML允许直线表示n元关系,如可视化管理hyperarcs 在Grailog(Graph inscribed logic)。此外,Datalog RuleML提供SQL风格的null通过独立的<Ind/>标记。
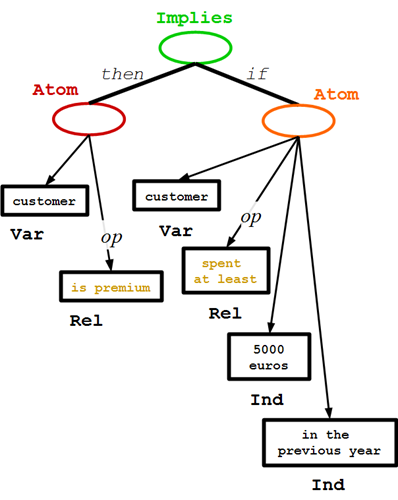
Datalog Rule 例子
Implies:推断
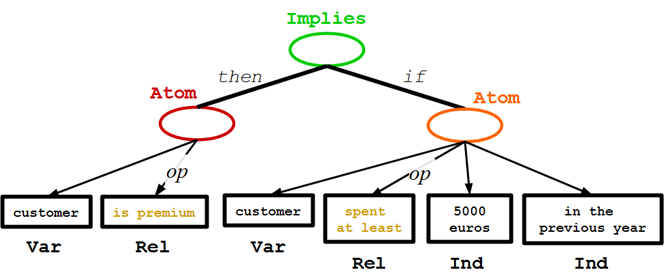
"A customer is premium if they spent at least 5000 euros in the previous year."
如果他们在去年至少花费了5000欧元,那么他们是优质的顾客
<Implies closure="universal"> <then> <Atom> <Var>顾客</Var> <Rel>是优质的</Rel> </Atom> </then> <if> <Atom> <Var>顾客</Var> <Rel>至少花费</Rel> <Ind>5000欧元</Ind> <Ind>去年</Ind> </Atom> </if> </Implies>
看看这些标记,请注意RuleML标签与Java类与方法命名约定一样,是区分大小写的。Atom公式由以下几个元素构成之前讨论的事实,其中包含:<Implies>、<If>、<Atom>,不同的是的<ind>Peter Miller</ind>被换成了<Var>顾客</Var>,顾客是一个变量标记。这个变量也发生在<Implies>的<then>的<Atom>的标签内,它适用于一元关系<Var>顾客</Var>和<Rel>是优质的</ Rel>。