disruptor 可以理解为一个生产消费的框架. 具体翻译教程: http://ifeve.com/disruptor-getting-started/
这个框架从数据上看, 是很强大的. 号称1s处理600万数据(不是消费掉600万). 这里学习一下.
一. Hello World
数据容器:
//数据的载体, 封装要传递的数据 public class LongEvent { private long value; public long getValue() { return value; } public void setValue(long value) { this.value = value; } }
这里的数据封装类, 叫 Event, 我们知道 Event 翻译过来是 事件. 但是这里表示数据. 稍微有点别扭
数据生产工厂:
//数据包装类工厂, 用来生产空容器的, 用来装数据 public class LongEventFactory implements EventFactory { @Override public Object newInstance() { return new LongEvent(); } }
这里主要是用来生产数据的空容器的. 给后面用的时候, 进行赋值用的.
消费者:
//数据的处理器, 对数据进行处理, 此处只是简单的打印 public class LongEventHandlerA implements EventHandler<LongEvent>, WorkHandler<LongEvent> { @Override public void onEvent(LongEvent event, long l, boolean b) throws Exception { System.out.println(Thread.currentThread().getName() + "消费数据(A) : " + event.getValue()); } @Override public void onEvent(LongEvent event) throws Exception { System.out.println(Thread.currentThread().getName() + "消费数据(A) : " + event.getValue()); } }
在Hello World例子中, 只要实现 EventHandler 接口就行了, 后面那个 WorkHandler 是后面例子用的.
在来一个消费者B, 代码和上面一样:
//数据的处理器, 对数据进行处理, 此处只是简单的打印 public class LongEventHandlerB implements EventHandler<LongEvent>, WorkHandler<LongEvent> { @Override public void onEvent(LongEvent event, long l, boolean b) throws Exception { System.out.println(Thread.currentThread().getName() + "消费数据(B) : " + event.getValue()); } @Override public void onEvent(LongEvent event) throws Exception { System.out.println(Thread.currentThread().getName() + "消费数据(B) : " + event.getValue()); } }
生产者:
//数据生产者 public class LongEventProducer { //生产的数据可以往 ringBuffer 里面丢 private final RingBuffer<LongEvent> ringBuffer; public LongEventProducer(RingBuffer<LongEvent> ringBuffer) { this.ringBuffer = ringBuffer; } /** * onData用来发布事件,每调用一次就发布一次事件事件 * 它的参数会通过事件传递给消费者 * * @param bb */ public void onData(ByteBuffer bb) { //可以把ringBuffer看做一个事件队列,那么next就是得到下面一个事件槽 long sequence = ringBuffer.next(); try { //用上面的索引取出一个空的事件用于填充 LongEvent event = ringBuffer.get(sequence); //设置值 event.setValue(bb.getLong(0)); } finally { //发布事件, 或者说发布数据, 通知消费者可以消费了 ringBuffer.publish(sequence); } } }
生产者的另一种写法, 要稍微简单点:
public class LongEventProducerWithTranslator { private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR = new EventTranslatorOneArg<LongEvent, ByteBuffer>() { @Override public void translateTo(LongEvent longEvent, long sequence, ByteBuffer bb) { longEvent.setValue(bb.getLong(0)); } }; private final RingBuffer<LongEvent> ringBuffer; public LongEventProducerWithTranslator(RingBuffer<LongEvent> ringBuffer) { this.ringBuffer = ringBuffer; } public void onData(ByteBuffer bb){ ringBuffer.publishEvent(TRANSLATOR, bb); } }
测试方法:
public static void main(String[] args) throws InterruptedException { //线程池 //Executor executor = Executors.newCachedThreadPool(); //装数据的容器工厂 LongEventFactory factory = new LongEventFactory(); //容器size int bufferSize = 1024; //创建 disruptor 实例 //这种方式已经不推荐使用 //Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory, bufferSize, executor); //推荐使用这种, 自定义线程工厂的方式 ThreadFactory threadFactory = new ThreadFactory() { private final AtomicInteger index = new AtomicInteger(0); @Override public Thread newThread(Runnable r) { return new Thread(null, r, "disruptor-thread-" + index.incrementAndGet()); } }; Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(factory, bufferSize, threadFactory , ProducerType.SINGLE , new YieldingWaitStrategy()); //引入数据处理器 //这种方式是消费相同的数据 disruptor.handleEventsWith(new LongEventHandlerA()) .then(new LongEventHandlerB()); //这种方式是消费不同的数据 //disruptor.handleEventsWithWorkerPool(new LongEventHandlerA(), new LongEventHandlerB()); //启动 disruptor 容器 disruptor.start(); //从 disruptor 中拿取装数据的容器 RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); //将这个容器给生产者, 生产者产生的数据, 可以直接丢进去 //LongEventProducer producer = new LongEventProducer(ringBuffer); LongEventProducerWithTranslator producer = new LongEventProducerWithTranslator(ringBuffer); ByteBuffer bb = ByteBuffer.allocate(8); for (long num = 0L; num <= 100L; num++) { bb.putLong(0, num); //发布数据 producer.onData(bb); Thread.sleep(100); } }
消费者消费的时候, 大的方向上, 有两种模式:
1. 多个消费者, 消费的数据都是一样的: handleEventsWith
2. 多个消费者, 消费的数据是不一样的: handleEventsWithWorkerPool
disruptor 有个比较有意思的功能, 就是拼接消费模型.
如此例中, 我修改一句代码:
disruptor.handleEventsWith(new LongEventHandlerA()) .then(new LongEventHandlerB()).handleEventsWithWorkerPool(new LongEventHandlerC(), new LongEventHandlerD());
看结果:

仔细观察, 就能发现, A永远在B前面, 因为 B 是 then() 在A后面的.
C和D永远不会消费同一条消息. 比如 C 消费了96, 那么D就不能再消费96了, 继而只能在下一轮中消费97.
二. 等待模式
既然是生产消费, 就肯定有个速度问题. 可能是生产快了, 也可能是消费快了. 那么这种情况, 在 disruptor 也是有策略处理的. 这里直接引用译文.
Disruptor默认的等待策略是BlockingWaitStrategy。这个策略的内部适用一个锁和条件变量来控制线程的执行和等待(Java基本的同步方法)。BlockingWaitStrategy是最慢的等待策略,但也是CPU使用率最低和最稳定的选项。然而,可以根据不同的部署环境调整选项以提高性能。
SleepingWaitStrategy
和BlockingWaitStrategy一样,SpleepingWaitStrategy的CPU使用率也比较低。它的方式是循环等待并且在循环中间调用LockSupport.parkNanos(1)来睡眠,(在Linux系统上面睡眠时间60µs).然而,它的优点在于生产线程只需要计数,而不执行任何指令。并且没有条件变量的消耗。但是,事件对象从生产者到消费者传递的延迟变大了。SleepingWaitStrategy最好用在不需要低延迟,而且事件发布对于生产者的影响比较小的情况下。比如异步日志功能。
YieldingWaitStrategy
YieldingWaitStrategy是可以被用在低延迟系统中的两个策略之一,这种策略在减低系统延迟的同时也会增加CPU运算量。YieldingWaitStrategy策略会循环等待sequence增加到合适的值。循环中调用Thread.yield()允许其他准备好的线程执行。如果需要高性能而且事件消费者线程比逻辑内核少的时候,推荐使用YieldingWaitStrategy策略。例如:在开启超线程的时候。
BusySpinWaitStrategy
BusySpinWaitStrategy是性能最高的等待策略,同时也是对部署环境要求最高的策略。这个性能最好用在事件处理线程比物理内核数目还要小的时候。例如:在禁用超线程技术的时候。
在 new Disruptor() 的时候, 可以指定引用哪一种等待策略.
三. RingBuffer
RingBuffer 具体是啥, 这里我也不解析了, 可以把它理解为一个 环形结构的 数据存储器.
这里需要注意, 在给 RingBuffer 分配数据槽 的时候, 数量最好是 2的幂次倍. 这种的性能比随便写的要好很多.
这个 RingBuffer 也可以拿出来单独用, 不和 disruptor 合着用
测试方法:
public static void main2(String[] args) throws InterruptedException { ExecutorService pool = Executors.newCachedThreadPool(); LongEventHandlerA handlerA = new LongEventHandlerA(); LongEventHandlerB handlerB = new LongEventHandlerB(); RingBuffer ringBuffer = RingBuffer.createSingleProducer(new LongEventFactory(), 1024); SequenceBarrier sequenceBarrier = ringBuffer.newBarrier(); //创建消息处理器, 相当于消费者A BatchEventProcessor<LongEvent> eventProcessorA = new BatchEventProcessor<LongEvent>(ringBuffer, sequenceBarrier, handlerA); //这一步的目的就是把消费者的位置信息引用注入到生产者 如果只有一个消费者的情况可以省略 ringBuffer.addGatingSequences(eventProcessorA.getSequence()); //把消息处理器提交到线程池 pool.execute(eventProcessorA); //创建消息处理器, 相当于消费者B BatchEventProcessor<LongEvent> eventProcessorB = new BatchEventProcessor<LongEvent>(ringBuffer, sequenceBarrier, handlerB); ringBuffer.addGatingSequences(eventProcessorB.getSequence()); pool.execute(eventProcessorB); for (int i = 0; i < 100; i++) {
//拿取空槽位置 long seq = ringBuffer.next();
//对空槽进行数据填充 LongEvent event = (LongEvent) ringBuffer.get(seq); event.setValue(i);
//发布数据, 通知消费者进行数据消费 ringBuffer.publish(seq); } Thread.sleep(1000); //通知事件(或者说消息)处理器 可以结束了(并不是马上结束!!!) eventProcessorA.halt(); eventProcessorB.halt(); //关闭线程 pool.shutdown(); }
结果:
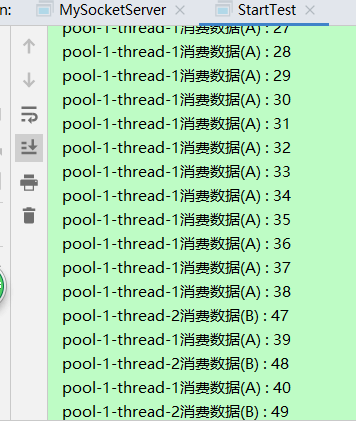
我这里只贴了一部分, 其实是都消费完了.
从图中可以看出, 消费没有顺序, 并不是A消费了B才消费, 也不是交替消费. 他们消费的数据是相同的.
除了以上这种写法, 他还有一种写法, 使用 WorkPool:
public static void main3(String[] args) throws InterruptedException { ExecutorService pool = Executors.newCachedThreadPool(); LongEventHandlerA handlerA = new LongEventHandlerA(); LongEventHandlerB handlerB = new LongEventHandlerB(); LongEventFactory eventFactory = new LongEventFactory(); RingBuffer ringBuffer = RingBuffer.createSingleProducer(eventFactory, 1024); SequenceBarrier sequenceBarrier = ringBuffer.newBarrier(); WorkerPool<LongEvent> workerPoolA = new WorkerPool<LongEvent>(ringBuffer, sequenceBarrier, new IgnoreExceptionHandler(), handlerA); workerPoolA.start(pool); WorkerPool<LongEvent> workerPoolB = new WorkerPool<LongEvent>(ringBuffer, sequenceBarrier, new IgnoreExceptionHandler(), handlerB); workerPoolB.start(pool); for (int i = 0; i < 100; i++) { long seq = ringBuffer.next();//占个坑 --ringBuffer一个可用区块 LongEvent longEvent = (LongEvent) ringBuffer.get(seq);//给这个区块放入 数据 longEvent.setValue(i); ringBuffer.publish(seq);//发布这个区块的数据使handler(consumer)可见 } Thread.sleep(1000);//等上1秒,等消费都处理完成 //通知事件(或者说消息)处理器 可以结束了(并不是马上结束!!!) workerPoolA.halt(); //通知事件(或者说消息)处理器 可以结束了(并不是马上结束!!!) workerPoolB.halt(); //终止线程 pool.shutdown(); }
结果:
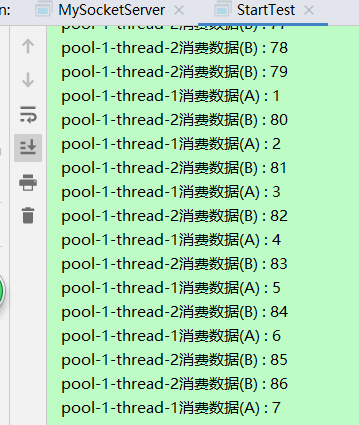
数据少的时候, 你可能会看到 A 和 B 交替出现, 但事实上, 这里并没有顺序.