TCP之Nagle算法&&延迟ACK
1. Nagle算法:
是为了减少广域网的小分组数目,从而减小网络拥塞的出现;
该算法要求一个tcp连接上最多只能有一个未被确认的未完成的小分组,在该分组ack到达之前不能发送其他的小分组,tcp需要收集这些少量的分组,并在ack到来时以一个分组的方式发送出去;其中小分组的定义是小于MSS的任何分组;
该算法的优越之处在于它是自适应的,确认到达的越快,数据也就发哦送的越快;而在希望减少微小分组数目的低速广域网上,则会发送更少的分组;
2. 延迟ACK:
如果tcp对每个数据包都发送一个ack确认,那么只是一个单独的数据包为了发送一个ack代价比较高,所以tcp会延迟一段时间,如果这段时间内有数据发送到对端,则捎带发送ack,如果在延迟ack定时器触发时候,发现ack尚未发送,则立即单独发送;
延迟ACK好处:
(1) 避免糊涂窗口综合症;
(2) 发送数据的时候将ack捎带发送,不必单独发送ack;
(3) 如果延迟时间内有多个数据段到达,那么允许协议栈发送一个ack确认多个报文段;
3. 当Nagle遇上延迟ACK:
试想如下典型操作,写-写-读,即通过多个写小片数据向对端发送单个逻辑的操作,两次写数据长度小于MSS,当第一次写数据到达对端后,对端延迟ack,不发送ack,而本端因为要发送的数据长度小于MSS,所以nagle算法起作用,数据并不会立即发送,而是等待对端发送的第一次数据确认ack;这样的情况下,需要等待对端超时发送ack,然后本段才能发送第二次写的数据,从而造成延迟;
4. 关闭Nagle算法:
使用TCP套接字选项TCP_NODELAY可以关闭套接字选项;
如下场景考虑关闭Nagle算法:
(1) 对端不向本端发送数据,并且对延时比较敏感的操作;这种操作没法捎带ack;
(2) 如上写-写-读操作;对于此种情况,优先使用其他方式,而不是关闭Nagle算法:
--使用writev,而不是两次调用write,单个writev调用会使tcp输出一次而不是两次,只产生一个tcp分节,这是首选方法;
--把两次写操作的数据复制到单个缓冲区,然后对缓冲区调用一次write;
--关闭Nagle算法,调用write两次;有损于网络,通常不考虑;
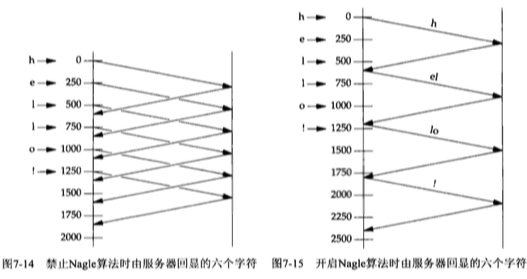
5. 禁止Nagle和开启Nagle算法发送数据与确认示意图:
发包顺序与收包问题
a) 由于TCP要通过协商解决发送出去的报文段的长度,因此我们发送的数据很有可能被分割甚至被分割后再重组交给网络层发送,而网络层又是采用分组传送,即网络层数据报到达目标的顺序完全无法预测,那么收包会出现半包、粘包问题。举个例子,发送端连续发送两端数据msg1和msg2,那么发送端[传输层]可能会出现以下情况:
i. Msg1和msg2小于TCP的MSS,两个包按照先后顺序被发出,没有被分割和重组
ii. Msg1过大被分割成两段TCP报文msg1-1、msg2-2进行传送,msg2较小直接被封装成一个报文传送
iii. Msg1过大被分割成两段TCP报文msg1-1、msg2-2,msg1-1先被传送,剩下的msg1-2和msg2[较小]被组合成一个报文传送
iv. Msg1过大被分割成两段TCP报文msg1-1、msg2-2,msg1-1先被传送,剩下的msg1-2和msg2[较小]组合起来还是太小,组合的内容在和后面再发送的msg3的前部分数据组合起来发送
v. ……………………….太多……………………..
b) 接收端[传输层]可能出现的情况
i. 先收到msg1,再收到msg2,这种方式太顺利了。
ii. 先收到msg1-1,再收到msg1-2,再收到msg2
iii. 先收到msg1,再收到msg2-1,再收到msg2-2
iv. 先收到msg1和msg2-1,再收到msg2-2
v. //…………还有很多………………
c) 其实“接收端网络层”接收到的分组数据报顺序和发送端比较可能完全是乱的,比如发“送端网络层”发送1、2、3、4、5,而接收端网络层接收到的数据报顺序却可能是2、1、5、4、3,但是“接收端的传输层”会保证链接的有序性和可靠性,“接收端的传输层”会对“接收端网络层”收到的顺序紊乱的数据报重组成有序的报文[即发送方传输层发出的顺序],然后交给“接收端应用层”使用,所以“接收端传输层”总是能够保证数据包的有序性,“接收端应用层”[我们编写的socket程序]不用担心接收到的数据的顺序问题。
d) 但是如上所述,粘包问题和半包问题不可避免。我们在接收端应用层需要自己编码处理粘包和半包问题。一般做法是定义一个缓冲区或者是使用标准库/框架提供的容器循环存放接收到数据,边接收变判断缓冲区数据是否满足包头大小,如果满足包头大小再判断缓冲区剩下数据是否满足包体大小,如果满足则提取。详细步骤如下:
1. 接收数据存入缓冲区尾部
2. 缓冲区数据满足包头大小否
3. 缓冲区数据不满足包头大小,回到第1步;缓冲区数据满足包头大小则取出包头,接着判断缓冲区剩余数据满足包头中定义的包体大小否,不满足则回到第1步。
4. 缓冲区数据满足一个包头大小和一个包体大小之和,则取出包头和包体进行使用,此处使用可以采用拷贝方式转移缓冲区数据到另外一个地方,也可以为了节省内存直接采取调用回调函数的方式完成数据使用。
5. 清除缓冲区的第一个包头和包体信息,做法一般是将缓冲区剩下的数据拷贝到缓冲区首部覆盖“第一个包头和包体信息”部分即可。