原博客:https://blog.csdn.net/huplion/article/details/79069365
(在此仅作学习记录作用)
一、前言
在前几篇文章中,我们学习到如何在训练集上设置权重,并由此计算出损失(loss),其中loss是由两部分组成,分别是数据损失项和正则化项目。我们最终想要得到损失函数关于权重矩阵w的梯度表达式,然后进行优化(这句话点明了反向传播和训练的作用)。我们采用梯度下降算法,进行迭代运算,计算梯度进行权重的更新,并一直循环执行这个操作。最后会停留在一个损失函数的低值点,我们得到的这个低值点就等价于对基于训练集的分数结果进行良好的预测。
计算梯度的方法有两种:
(1)数值梯度(Numerical gradient): 利用表达式直接进行计算,但是对于数据量过大的情况,运算太慢,不切实际。
(2)解析梯度(Analytic gradient): 利用微积分公式计算得到,运算速度很快,但有时会得到错误的结果。
所以,我们会综合以上两种方式,进行梯度检查的操作,先通过运算得到解析梯度,然后用数值梯度二次检测它的准确性。
二、 引入BP
以上知识的回顾,让我们会有这样的疑问,我们已经利用梯度下降(Gradient descent)的方式很好的解决了得到最小损失W的问题,为什么还要提出BP反向传播算法?答案是纵然梯度下降神通广大,但却不是万能的。梯度下降可以应对带有明确导数的情况,或者是说直接用上面的表达式计算的情况,比如逻辑回归(Logistic Regression),我们可以把它看做没有隐藏层的网络; 但对于多隐藏层的神经网络,输出层可以直接求出误差来更新参数,但其中隐藏层的误差是不存在的,因此不能对它直接应用梯度下降,而是先将误差反向传播至隐藏层,然后再应用梯度下降,其中将误差从末层往前传递过程需要链式法则(Chain Rule)的帮助,因此反向传播算法可以说是梯度下降在链式法则中的应用。
接下来这部分来自另外一个博客:
https://blog.csdn.net/dawningblue/article/details/82901900
主要理解两个核心概念:
1. 计算图的概念
2. 反向传播利用了链式求导但是本质不完全是链式法则。
理解概要:
与其说反向传播算法的本质是链式求导法则,倒不如说它的本质是分治的思想在链式求导法则中的应用。因为当一个函数很复杂的时候即使是我们会链式求导法则,求这个函数对某一个变量的偏导数(的解析度)依然是一个非常困难的事情。而反向传播则是把一个大问题拆成一个一个各自独立互不影响的小问题,分别求出这些小问题的解,再把这个解组合起来。为了解释清楚这个问题,我们需要引入一个工具-----“计算图模型”
什么是计算图模型?在这个课程里虽然我们基于这个概念做了很多操作,但是没有直接定义。
我们认为:计算图模型其实就是数学公式的一种图形化展示。
其实我们以前学习数字电路的时候已经用到了这种工具,因为用起来很自然所以没有仔细琢磨。(还有一个理解方式是把一个计算表达式想象成一棵树,似乎数据结构里用到这种方法)这里用到了很多“门”的概念,而“门”就是数字电路里的概念。这里门就是一个运算单元,实现了基本的运算,比如加减乘除等。其实神经网络和数字电路有相似之处,都是数学表达式的图形化显示(或者说具象化的体现),神经网络是一种特殊的数字电路。数学公式是由基本的运算组合而成,而数字电路模拟了这个过程。
运算单元可以看成一个输入输出模型,所谓的输入输出模型,也就是下面这个东西,本质就是一个函数,而函数本质上就是一个映射(对应关系)。
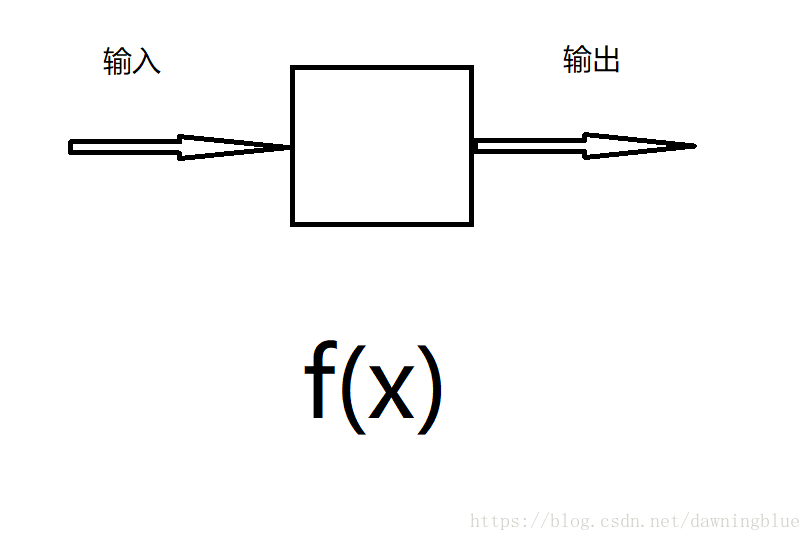
过去我们在设计数字电路的时候主要利用的是计算图的前向传播过程,也就是从左到右的计算出表达式的结果,而这里我们计算梯度就需要在这个自然感官的基础上定义一些新的操作。我在这块花了好长时间琢磨,看讲义的时候怎么也没搞明白
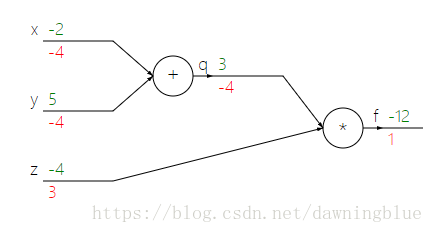
虽然能知道q下面的那个-4是因为![]() 而z = -4所以q下面-4,顺着往下计算,能算出z下面的3以及x,y下面的-4,但是f下面的“1”是怎么回事?
而z = -4所以q下面-4,顺着往下计算,能算出z下面的3以及x,y下面的-4,但是f下面的“1”是怎么回事?
后来看了视频课程之后才明白是怎么回事。我们在计算图定义的求梯度的操作是这样的:我们求的梯度都是f(最终输出的函数)对各个变量的梯度,
比如q下面的值是f对q的梯度也就是∂f/∂q, z下面的值f是对z的梯度也就是∂f/∂z, x下面的值是f对x的梯度也就是∂f/∂x, y下面的值是f对y的梯度就是∂f/∂y,
同理,f下面的值是f对f的梯度,也就是∂f/∂f。梯度(在只有一个自变量的时候也叫做导数)衡量的是自变量的变化能带来因变量多大的变化(变化带来的变化),
不同的运算变化速率当然是不一样的,比如加法运算,提升就是线性的,导数为1嘛,而乘法运算提升也是线性的,不过要加一个倍数,运算的阶数越高变化率越大。
形象一点就是高度提升的速度,也就是比较大或者梯度比较高。
从计算上来看,函数对任意某个变量的梯度,就等于函数的最终输出除以这边变量对应的输出。

我们从最右边的图末开始计算输出对于最后一个变量也就是 f 的梯度,很明显这个梯度是1,因为最终的输出和最后一个变量的值是一样的,
自己和自己比,注意梯度为1不代表没有梯度,代表的是横坐标和纵坐标的变化是一摸一样的(梯度为一表示的是斜率为45度)。
接下来我们计算 f 在q上的梯度![]() ,这个结果是z,而z等于-4。
,这个结果是z,而z等于-4。
之后我们想计算f在y上的梯度,但是f和y没有直接联系,所以我们这里用链式求导法则,![]() ,我们已经知道
,我们已经知道![]() 是-4,而
是-4,而![]() 也可以计算出来是1,于是乎
也可以计算出来是1,于是乎![]() 同理可以求出
同理可以求出![]() 也是-4。
也是-4。
我一开始还有一个疑问,就是随着数据从左边到右边,其实梯度是在不断提升的,可以说,输入端是在山脚下,输出端是在山顶,中间过了好多个陡坡,为什么反而最右边输出的梯度反而比左边变量的梯度数值上还小呢?
其实这个变量下面的数值,代表这样一个含义: ~~就是这个变量变化了1对最终输出产生的变化是多少,比如q下面的那个-4,并不是说,右边梯度1传到这边就变成了-4,而是说q每变化1,造成最终的输出变化-4。 ~~这个理解有点点偏差,讲课的小姐姐是这样说的:当y变化了一点点(不是1), 那么y对q的影响就会变成1(也就是![]() ,这才是梯度的准确含义,是这点切线的斜率),而q对f的影响也会马上变成-4(也就是
,这才是梯度的准确含义,是这点切线的斜率),而q对f的影响也会马上变成-4(也就是![]() ),这样我们就得到y对f的影响(
),这样我们就得到y对f的影响(![]() )
)

所以在我们的计算图中每个节点知道与它相邻的节点,只知道输入和输出。

可能在进行普通的数值计算,这些属性就足够用了,但是其实在这个结果上我们还能挖掘更多,我们可以计算这个节点的“局部梯度”。
差不过也就只能挖掘出这么多了,当反向传播发生的时候发生了什么呢?
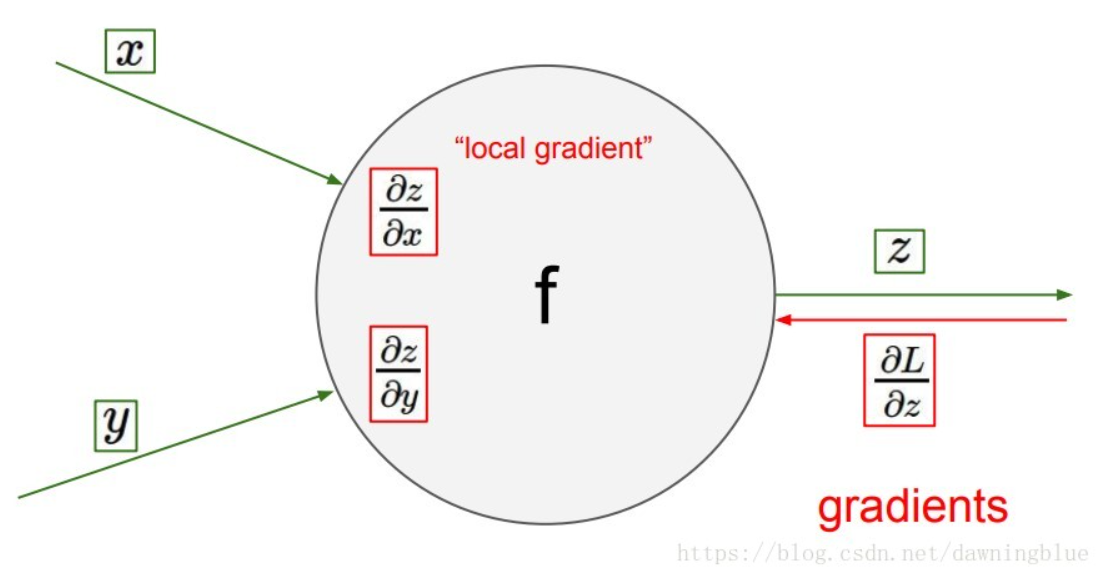
从上游传递过来梯度,这个梯度是函数的输入值对这个节点输出值的导数。
接下来找的就是这个节点输入的梯度,而这个节点输入的梯度就是从上游传递与局部梯度的乘积,一般来说,局部梯度都是可以求出表达式,而上游传过来的梯度都是计算好的数值。
不管整个函数有多么复杂,只要我把函数计算图表示出来,实际上就是拆成一个一个简单运算的组合,我们只要计算每个简单运算的梯度就可以,而每个运算单元的梯度很好求,只要前面传过来的值是一个具体的数值,我们就可以求出当前节点对上一层节点的梯度,整个问题就是通过一个一个局部的组合,一层一层的传递,把一个很复杂的问题变成了多个简单问题的组合,这个思想太精妙了。化整为零,每个部分只要关注局部就可以了。
当然还有一个问题就是写出函数的计算图,其实有一个粒度的问题,就是你把运算拆成多基础,这个可以做一个权衡,如果把每个运算都拆的特别简单,那么这个图也会变得特别的大,但是如果每个运算集成度比较高,虽然图的大小变小了,但是每个单元计算导数的复杂度也会提高。
对反向传播本质的一些想法:
你说链式法则是反向传播的本质,也不算错。
因为你看,比如一个非常复杂的复合函数,如果函数对自变量导数,中间可能需要引入5到6个中间变量。
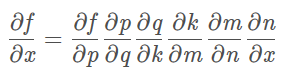
其实这个就是完整计算图的一个分支
计算图其实是把所有自变量的路径都展示出来了,但是我们计算的时候只用一条路径的。其实一旦我们把完整的计算图画出来,并且考虑以计算机的方式进行处理的时候,我们会在手工处理的基础上进行一些优化,比如有一些计算路径是重合的,或者我们可能不会以深度优先遍历的方式,分别一个个自变量的计算,而是类似于广度优先遍历的方式,一层一层的计算,等计算到最后一层的时候,所有的自变量梯度都有了。