原文连接:https://blog.csdn.net/MOU_IT/article/details/82717745
1、简介
对于tensorflow.contrib这个库,tensorflow官方对它的描述是:此目录中的任何代码未经官方支持,可能会随时更改或删除。每个目录下都有指定的所有者。它旨在包含额外功能和贡献,最终会合并到核心Tensorflow中,但其接口可能仍然会发生变化,或者需要进行一些测试,看是否可以获得更广泛的接受。所以slim依然不属于原生tensorflow。那么什么是slim? slim到底有什么用?
slim是一个使构建,训练,评估神经网络变得简单的库。它可以消除原生tensorflow里面很多重复的模板性的代码,让代码更紧凑,更具备可读性。另外slim提供了很多计算机视觉方面的著名模型(VGG, AlexNet等),我们不仅可以直接使用,甚至能以各种方式进行拓展。
slim由几个独立存在的部分组成,以下为主要的模块:
arg_scope: 提供了一个新的scope, 它允许用户定义在这个scope内的许多特殊操作(比如卷积、池化等)的默认参数。
data: 这个模块包含data_decoder、prefetch_queue、dataset_data_provider、tfexample_decoder、dataset、data_provider、paraller_reader。
evalution:包含一些评估模型的例程。
layers: 包含使用TensorFlow搭建模型的一些high level layers。
learning: 包含训练模型的一些例程。
losses: 包含常用的损失函数
metrics: 包含一些常用的评估指标。
nets: 包含一些常用的网络模型的定义, 比如VGG和AlexNet.
queues: 提供一个上下文管理器,使得开启和关闭一个QueueRunners更加简单和安全。
regularizers: 包含权重正则化器。
variables: 为变量的创建和操作提供了比较方便的包装器。
2、定义模型
通过组合slim中变量(variables)、网络层(layer)、前缀名(scope), 模型可以被简洁定义。
(1)变量(Variables)定义
在原始的TensorFlow中,创建变量时,要么需要预定义的值,要么需要一个初始化机制(比如高斯分布中的随机采样)。此外,如果需要在一个特定设备(比如GPU)上创建一个变量,这个变量必须被显式的创建。为了减少创建变量的代码,slim提供了一些列包装器 函数允许调用者轻易的创建变量。
例如,为了创建一个权重变量,它使用截断正太分布初始化、使用L2的正则化损失并且把这个变量放到CPU中,我们只需要简单的做如下声明:
weights = slim.variable('weights', shape=[10, 10, 3, 3], initializer = tf.truncated_normal_initializer(stddev=0.1), regularizer = slim.l2_regularizer(0.05), device='/CPU:0')
注意在原本的TensorFlow中,有两种类型的变量: 常规(regular)变量和局部(local)变量。大部分的变量都是常规变量,它们一旦被创建,它们就会被保存到磁盘。而局部变量只存在于一个Session的运行期间,它们并不会被保存到磁盘中。在Slim中,模型变量代表一个模型中的各种参数,Slim通过定义模型变量,进一步把各种变量区分开来。模型变量在训练过程中不断被训练和调参,在评估和预测时可以从checkpoint文件中加载进来。例如被slim.fully_connected()或slim.conv2d()网络层创建的变量。而非模型变量是指那些在训练和评估中用的的但是在预测阶段没有用到的变量,例如global_step变量在训练和评估中用到,但是它并不是一个模型变量。同样,移动平均变量可能反映模型变量,但移动平均值本身不是模型变量。模型变量和常规变量可以被slim很容创建如下:
# 模型变量 weights = slim.model_variable('weights',shape=[10, 10, 3, 3], initializer=tf.truncated_normal_initializer(stddev=0.1), regularizer = slim.l2_regularizer(0.05), 6 device = '/CPU:0') model_variables = slim.get_model_variables() #常规变量 my_var = slim.variable('my_var', shape=[20, 1], initializer = tf.zeros_initializer()) regular_variables_and_model_variables = slim.get_variables()
那这是怎么工作的呢?当你通过slim的网络或者直接通过slim.model_variable()创建模型变量时,Slim把模型变量加入到tf.GraphKeys.MODEL_VARIABLES的collection中。那如果你有属于自己的自定义网络层或者变量创建例程,但是你仍然想要slim来帮你管理,这时要怎么办呢?Slim提供了一个便利的函数把模型变量加入到它的collection中
my_model_variable = CreateViaCustomCode()
#让Slim知道有额外的变量
slim.add_model_variable(my_model_variable)
(2) 网络层(layers)定义
虽然TensorFlow操作集非常广泛,但神经网络的开发人员通常会根据更高级别的概念来考虑模型,例如“层”,“损失”, “度量”和“网络”。 一个网络层,比如一个卷积层、一个全连接层或一个BatchNorm层相对于一个简单的TensorFlow操作而言是非常的抽象,而且一个网络层通常包含多个TensorFlow的操作。此外,不像TensorFlow许多原生的操作一样,一个网络层通常(但不总是)有与之相关联的变量。例如,神经网络中的一个卷积层通常由以下几个Low-level的操作组成:
1) 创建权重和偏置变量
2) 将权重和输入或者前一层的输出进行卷积
3) 对卷积的结果加上偏执项
4) 对结果使用激活函数
使用原生的TensorFlow代码来实现的话,这是非常麻烦的,如下:
input = ... with tf.name_scope('conv1_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype = tf.float32, stddev = 1e-1), name='weights') # 卷积核就是权重 conv = tf.nn.conv2d(input, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[128], dtype= tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv1 = tf.nn.relu(bias, name=scope)
为了减轻这种重复码代码的工作量,slim提供了许多定义在网络层(layer)层次的操作,这些操作使得创建模型更加方便。比如,使用slim中的函数来创建一个和上面类似的网络层,如下:
input = ... net = slim.conv2d(input, 128, [3, 3], scope='conv1_1')
slim提供了在搭建神经网络模型时许多函数的标准实现
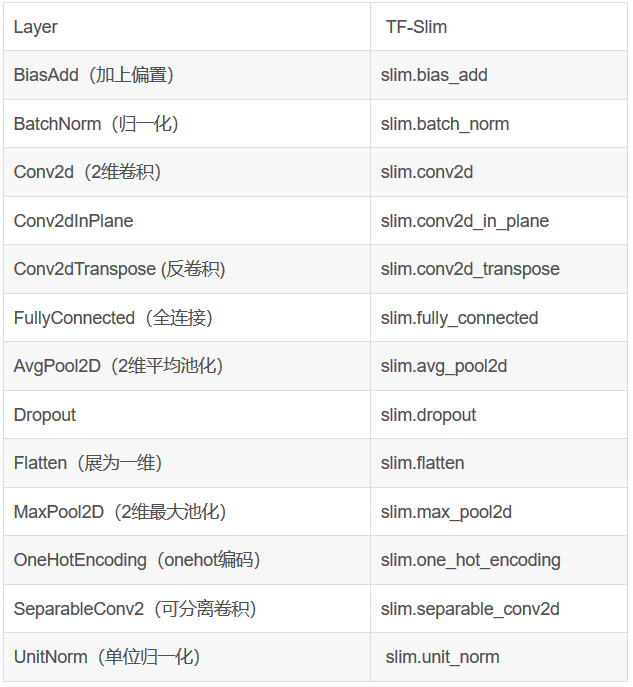
slim也提供了两个称为repeat和stack的元操作,这两个操作允许用户重复的使用某个相同的操作。比如,考虑如下VGG网络中的代码片段,在两虚的两个池化层之间会执行多个卷积操作:
net = ... net = slim.conv2d(net, 256, [3, 3], scope='conv3_1') net = slim.conv2d(net, 256, [3, 3], scope='conv3_2') net = slim.conv2d(net, 256, [3, 3], scope='conv3_3') net = slim.max_pool2d(net, [2, 2], scope='pool2')
一种减少这种代码重复的方式是使用循环,例如:
net = ... for i in range(3): net = slim.conv2d(net, 256, [3, 3], scope='conv3_%d', % (i+1)) net = slim.max_pool2d(net, [2, 2], scope='pool2')
而使用slim提供slim.repeat()操作将更加简洁:
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool2')
注意,slim.repeat()操作不仅仅可以应用相同的参数,它还可以为操作加上scope,因此,被赋予每个后续slim.conv2d()操作的scope都被附加上下划线和编号。具体来说,在上例中的scope将会被命名为:' conv3/conv3_1', 'conv3/conv3_2'和'conv3/conv3_3'。
此外,slim的slim.stack()操作允许调用者使用不同的参数来调用相同的操作,从而建立一个堆栈式(stack)或者塔式(Tower)的网络层。slim.stack()同样也为每个操作创建了一个新的tf.variable_scope()。比如,创建多层感知器(MLP)的简单的方式如下:
# 常规方式
x = slim.fully_connected(x, 32, scope='fc/fc_1') x = slim.fully_connected(x, 64, scope='fc/fc_2') x = slim.fully_connected(x, 128, scope='fc/fc_3')
# 使用slim.stack()方式
slim.stack(x, slim.fully_connected, [32, 64, 128], scope='fc')
在这个例子中, slim.stack()三次调用slim.fully_connected(), 把每次函数调用的输出传递给下一次的调用,而每次调用的隐层的单元数从32到64到128。同样的,我们也可以用slim.stack()来简化多个卷积操作:
# 常规方式 x = slim.conv2d(x, 32, [3, 3], scope = 'core/core_1') x = slim.conv2d(x, 32, [1, 1], scope = 'core/core_2') x = slim.conv2d(x, 64, [3, 3], scope = 'core/core_3') x = slim.conv2d(x, 64, [1, 1], scope = 'core/core_4')
# 使用Slim.stack():
slim.stack(x, slim.conv2d, [(32, [3, 3]), (32, [1, 1]), (64, [1 , 1]), (64, [3, 3]), (64, [1, 1]), scope='core')
(3) Scopes定义
除了TensorFlow的scope机制(name_scope, variable_scope), Slim添加了一种新的称为arg_scope的机制。这种新的scope允许一个调用者在arg_scope中定义一个或多个操作的许多默认参数,这些参数将会在这些操作中传递下去。通过实例可以更好地说明这个功能。考虑如下代码:
net = slim.conv2d(inputs, 64, [11, 11], 4, padding='SAME', weights_initializer=tf.truncated_normal_initializer(stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0005), scope='conv1') net = slim.conv2d(net, 128, [11, 11], padding='VALID', weights_initializer=tf.truncated_normal_initializer(stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0005), scope='conv2') net = slim.conv2d(net, 256, [11, 11], padding='SAME', weights_initializer=tf.truncated_normal_initializer(stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0005), scope='conv3')
可以看到,这三个卷积共享某些相同的超参数。有两个相同的padding方式,三个都有相同的权重初始化和权重正则化器。这种代码阅读性很差,而且包含很多可以被分解出去的重复值,一个可行的解决方案是指定变量的默认值。
padding = 'SAME' initializer = tf.truncated_normal_initializer(stddev=0.01) regularizer = slim.l2_regularizer(0.0005) net = slim.conv2d(inputs, 64, [11, 11], 4, padding=padding, weights_initializer=initializer, weights_regularizer=regularizer, scope='conv1') net = slim.conv2d(net, 128, [11, 11], padding='VALID', weights_initializer=initializer, weights_regularizer=regularizer, scope='conv2') net = slim.conv2d(net, 256, [11, 11], padding=padding, weights_initializer=initializer, weights_regularizer=regularizer, scope='conv3')
这种解决方案确保三个卷积层共享相同参数值,但是却并没有完全减少代码量。通过使用arg_scope,我们既可以确保每层共享相同的参数值,而且也可以简化代码:
with slim.arg_scope([slim.conv2d], padding='SAME', weights_initializer=tf.truncated_normal_initializer(stddev=0.01) weights_regularizer=slim.l2_regularizer(0.0005)): net = slim.conv2d(inputs, 64, [11, 11], scope='conv1') net = slim.conv2d(net, 128, [11, 11], padding='VALID', scope='conv2') net = slim.conv2d(net, 256, [11, 11], scope='conv3')
如上述例子所示,arg_scope的使用使得代码更加简洁、简单而且更容易维护。注意,尽管在arg_scope中参数被具体制定了,但是它们仍然可以被局部重写。特别的,上述三个卷积的padding方式均被指定为'SAME', 但是第二个卷积的padding可以被重写为'VALID'。
我们也可以嵌套使用arg_scope, 在相同的scope内使用多个操作。例如:
with slim.arg_scope([slim.conv2d, slim.fully_connected], activation_fn=tf.nn.relu, weights_initializer=tf.truncated_normal_initializer(stddev=0.01), weights_regularizer=slim.l2_regularizer(0.0005)): with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'): net = slim.conv2d(inputs, 64, [11, 11], 4, padding='VALID', scope='conv1') net = slim.conv2d(net, 256, [5, 5], weights_initializer=tf.truncated_normal_initializer(stddev=0.03), scope='conv2') net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc')
在这个例子中,第一个arg_scope对slim.conv2d()和slim.fully_connected()采用相同的权重初始化器和权重正则化器参数。在第二个arg_scope中,只针对slim.conv2d的附加默认参数被具体制定。
接下来我们定义VGG16网络,通过组合Slim的变量、操作和Scope,我们可以用很少的几行代码写一个常规上来讲非常复杂的网络,整个VGG网络的定义如下:
def vgg16(inputs): with slim.arg_scope([slim.conv2d, slim.fully_connected], activation_fn=tf.nn.relu, weights_initializer=tf.truncated_normal_initializer(0.0, 0.01), weights_regularizer=slim.l2_regularizer(0.0005)): net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5') net = slim.fully_connected(net, 4096, scope='fc6') net = slim.dropout(net, 0.5, scope='dropout6') net = slim.fully_connected(net, 4096, scope='fc7') net = slim.dropout(net, 0.5, scope='dropout7') net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8') return net