1. input layer形式为x1, x2, x3...xn,交互得到下一层hidden layer(如两者相加),hidden layer可以有很多层,最后得到output layer
2.perceptual
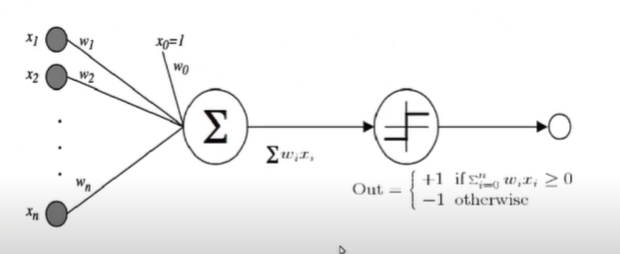
第一个圆中是根据不同的weight将input求和,第二个是根据求和的结果,大于0输出1,小于0输出-1
训练模型的过程就是不断的调整weight
首先随机选取一个w0,根据w=w+Δw对其不断更新(根据依照原始w判断错误的点更新)
假设xi是一个被误判成错误的情况,则yi=1且w * xi < 0,我们要找到x'使得w' * xI > w * xi
最简答的方式就是让w+xi,同时在xi前面添加一个大小介于01之间的学习率η(w = w + η*xi)
相反的,若是被误判成正确的情况,则减去η*xi
即:w' = w + η * yi * xi
3. 通常情况下基于gradient descent更新weight,o=x0+w1x1+...+wnxn
求td, od差值的平方和,前者为真实值,后者预测值
由于平方和图像中必有极值点,故而可以用gradient descent(找到梯度为0的点)
对每个点求相应的梯度,即每个点的偏导,得到整体偏导的方程,同时添加系数(-1*学习率)
终止条件取决于不同的算法
4. Batch mode Gradient Descent
把所有点的梯度加在一起进行更新
Incremental mode Gradient Descent
每分析完一条数据就进行更新
5. MLP
解决非线性问题
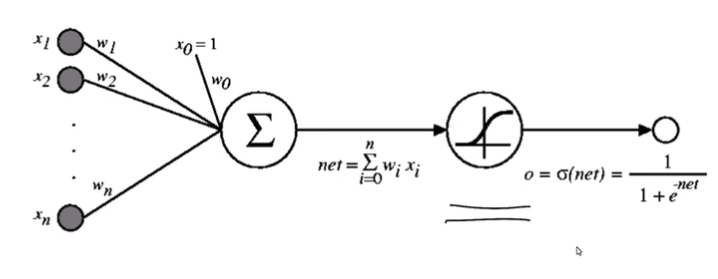
a(x) = 1/(1+e^-x)的好处是a(x)对a求导等于a(x)(1-a(x))
求导得:
6. 一层层根据output layer, hidden layer不同的方式,从后往前依次更新weight(因为只有最后一层可以跟真实值比较)
7. MLP for classification
换新的loss function
这里td代表分类属于0/1,od代表属于1的概率,希望td为1时,od尽可能大;td为0 时,od尽可能小
同样使这个loss function尽可能小
8. Deep Learning--CNN
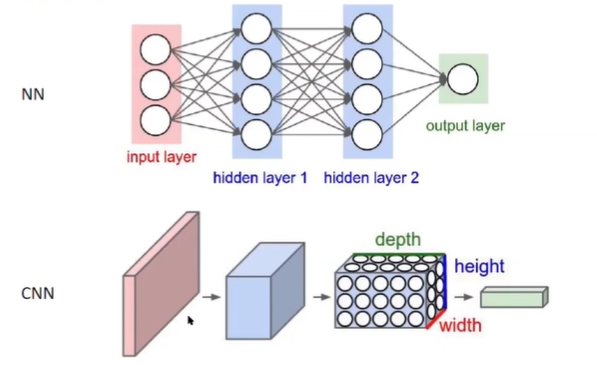
传入的为二维图像
conv layer:9517学过,可理解为用window在原始图片上遍历,最外面一圈没有相对应的故而结果比原始图片小一点
filter如5*5*3,3对应三层channel,filter中的每一层分别对应各自的image,然后加在一起
同时遍历过程中step可以大于1,stride即为步数
zero-padding是想得到与input一样大的输出时,可以在input四周加一圈0
output size = (input size - conv layer + 2 * zero padding) / stride + 1
(W-F+2P)/S+1
weights per neuron的计算中,1是bias,11*11是filter,没特殊规定情况下需要*3(RGB)
neurons即一共有多少小格子,即output size^2*filter
connections即neurons与前面一层的连线一共有多少,等于neurons*weights per neuron
independent parameters: 认定每一层filter上parameter都独立,即filter*weights per neuron
9. pooling layer
max pool: 如4*4转变成2*2,即将原图划分成2*2的小格子,找到一个最大的,代替这四个放在output中
mean pool即找中值
if the previous layer is J*K, and max pooling is applied with width F and stride S, the size of the output will be: (1 + (J - F)/S) * (1 + (K - F)/S)
不涉及任何parameter,故而none independent parameters does this add to the model
10. ReLU Layer:f(x) = max(0 ,x)
维持layer间梯度关系,实现非线性转化
11. Dropout: 防止overfitting
训练过程中禁止使用一部分节点,使训练更简单,禁用的节点是随机的
12. Loss Fuction:多分类问题下的loss function,即求熵
13. data augumentation:图片增强,人为对图像进行变化,使图片中的内容在不同情况下都可以被检测到
14. Adv Model:语义分割,图片中不同内容颜色不同;标记目标,如人脸实别
R-CNN: 用一些算法猜出目标可能出现的区域。放在CNN里,在根据是否正确进行分类
fast R-CNN:先转化到更小的尺寸上再猜对应区域
faster R-CNN:所有算法在一个莫得了完成