论文地址 https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf
包含章节 1-4
摘要
论文将介绍为social graph量身定制的一套数据模型及API接口,而TAO则是这个模型及API的实现。TAO提供实现facebook工作流所需固定query指令集合的social graph访问,,并基于地理位置进行分布式数据存储。TAO部署在Facebook内部并将适合的数据模型从memcache迁移到了TAO上。TAO部署于数千个分布式的服务器节点上,并存储数PB的数据,每秒可以提供十亿次读取和数百万次写入。
1 介绍
TAO是一个专门针对“读”进行优化了的图存储,用以解决Facebook的社交应用需求。在TAO出现之前,Facebook直接使用mysql来存储社交图谱,并使用memcache作为后备缓存。TAO依然使用了MySQL作为持久化存储,但是使用自己的graph-aware cache作为中介。TAO作为一个单体的geographically distributed instance被部署在Fackbook中。它包含一个最小的API集合,并在单机(per-machine)上提供高效地强一致性保障。TAO最引以为傲的是它的可扩展性:可以为PB级不断变化的数据集提供提供十亿次的并发读。
总的来说,本文做了三点贡献:
1、激励并刻画了一个富有挑战性的工作:如何为一个变化中的graph提供高效和可用的读操作
2、介绍了对象及它们之间的关系,介绍了用于访问graph的数据模型及API集合
3、详细介绍了TAO的实现及性能指标
我们来看一个典型的社交样例

Alice 打卡了 地点 Golden Gate Bridge, Bob 也在这里。
Cathy 发布了一条评论“Wish we were there!”
David 点赞了 Cathy 的评论。
可以看到在上述例子中,出现了对象、对象间的关系、以及actions。
对象:User(Alice、Bob、Cathy、David)、评论(comment,“Wish we were there!” )、地理位置 (Location, Golden Gate Bridge)
动作: Commenting 、Checking in、liking
2 背景
一个facebook页面会需要聚合和过滤数百个社交图谱上的元素。Facebook为每个用户提供量身定制的内容,并使用考虑到当前查看者的隐私检查来过滤每个元素。这种极端的定制化功能使得在创建内容时就执行大多数聚合和过滤操作变得不可行。 相反,Facebook会在每次查看内容时,再去解决数据依赖性并检查隐私项。
2.1 使用memcache来服务社交图谱(Serving the Graph from Memcache)
最初,Facebook使用Mysql来存储社交图谱,并使用php来访问mysql,然后将访问(query)的结果缓存在memcache中。这套后备缓存架构很适合Facebook用于快速迭代产品,因为所有的数据映射、cache失效检查都被编码在client端,而client端的代码经常会发布新版本。随着时间的推移,PHP 开发出一个抽象层,用于允许developer读写社交图谱中的对象(点)及对象间的关联关系(边),并直接访问mysql数据库。
TAO是一个我们构建的服务, 它直接实现了对象和对象间关系。提出TAO的动因是由于PHP api的封装失败(non-PHP的应用也可以很轻易的直接访问存储)以及由后备缓存系统(memcache)带来的基础设施问题:
低效的边查询(inefficient edge lists):kv型缓存的语义并不适用于edge list操作;每次边查询都会返回所有的edges,并且对单条边的修改会导致整个edge list被reload;有些需求会并发地更新缓存中的edge list。
分布式控制逻辑(distributed control logic):在后备缓存架构下,控制逻辑是放在client端执行的,而client端之间并不知道彼此的操作。这增加了会导致错误的场景,并且很难解决 thundering herds问题 (扩展知识:缓存踩踏)。
昂贵的写后读一致性(expensive read-after-write consistency):Facebook使用异步的mysql 副本主从同步机制,写操作只会在master节点进行,一段时间这个写操作才会反映在本地副本中。通过将数据模型限制为对象和关联,我们可以在写入时更新副本的缓存,然后使用图语义并发更新缓存中维护的消息。
2.2 TAO 的目标
TAO 适用于那些需要高效提供细粒度定制化内容(内容之间高度关联)的应用。系统需要允许有一部分数据在某些场景下是陈旧的,但大部分情况下都是实时数据。
3 TAO Data Model and API
Facebook关注 people、actions及relations。 我们将这些实体及其关联刻画为graph中的点和边。TAO的目标并不是实现一个完备的图语义,而是提供足够的表现力来处理大多数应用程序需求,同时保持可扩展性及数据的高效访问。如上述社交实例中的场景,每次app在渲染时都会请求服务器获取相关社交图谱上的点和边,并根据隐私策略进行过滤。对于不同的访问者(viewer)而言,每个事件(activity)底层依赖的点和边是相同的,但由于隐私策略的原因,每个viewer的聚合及过滤规则是不同的。
3.1 对象和关联( Objects and Associations)
TAO中的对象是类型化的节点(typed nodes),而TAO中的associations是节点间类型化的有向边(typed directed edges between nodes)。Object由64bit的int型ID唯一标识,所有object类型都在统一的ID语义空间下。association则由源object(id1)、关联类型(association type, atype)及目标object(id2)来标识。两个objects之间,同类型的association只能有一条边。object和association(点和边)上,都可以存放kv型的属性。每个association都有一个32bit的时间戳,用于在query中扮演关键角色。

下图表达了上述事例中的object和object间的association。
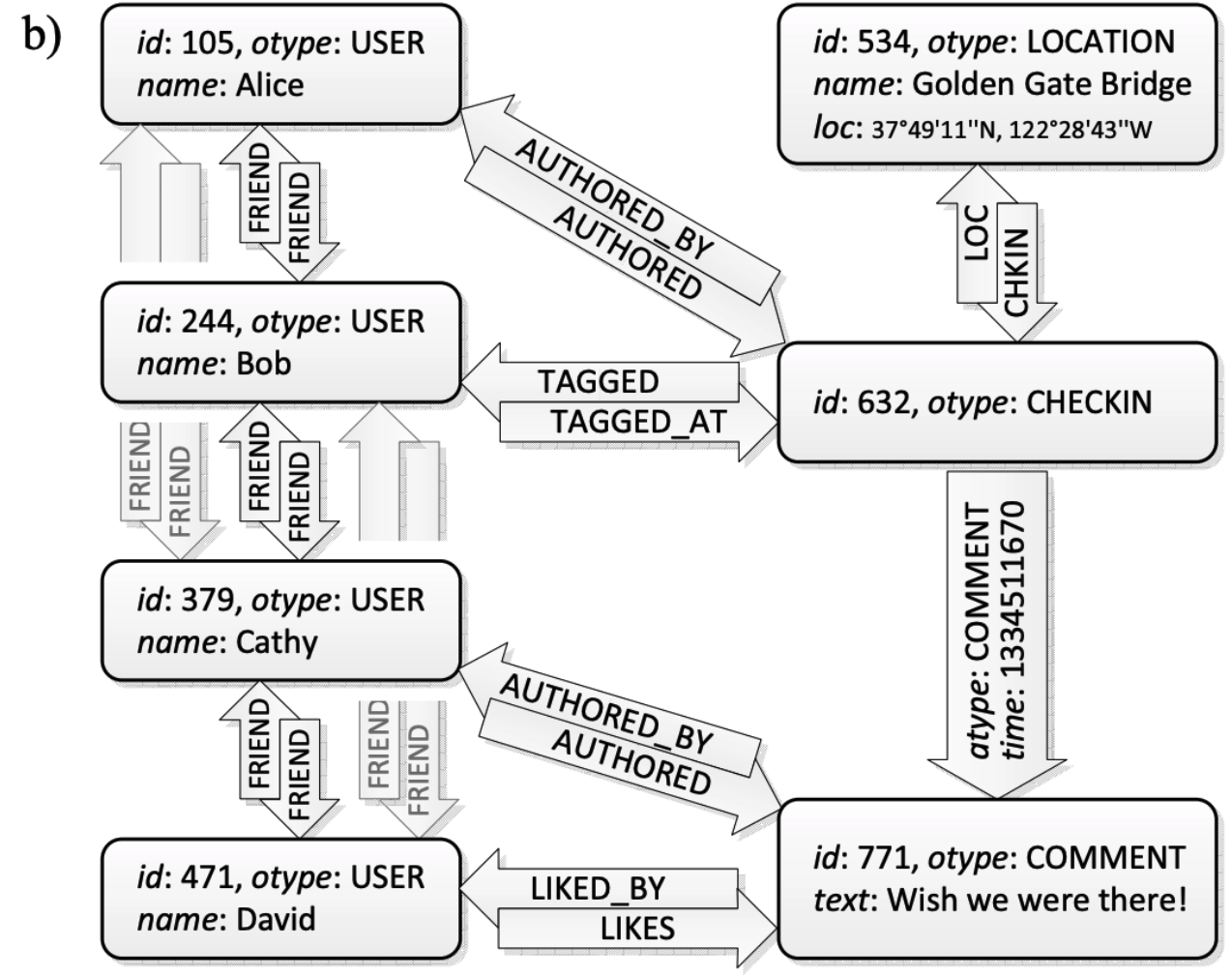
对象间的关联关系有:
1、互关(FRIEND):Alice和Bob、Bob和Cathy、Cathy和David。
2、发布(AUTHORED、AUTHORED_BY):Alice发布了打卡点、Cathy 发布了 评论。
3、打卡(TAGGED、TAGGED_BY):Bob tag了打卡点。
4、地点(LOC、CHKIN):打卡点是 xxxx 。
5、点赞(LIKE、LIKED_BY) :David 点赞了 Cathy 的评论。
actions可以通过object或association来编码。cathy的“评论”和David的“点赞”均是用户的actions,但只有“评论”会被认为是一种object。association一般用于表示两个对象间仅发生一次的动作或记录状态转移,如接受一次要求、点赞一条评论;而可重复的动作一般会被表达为object,如发表一条“评论”。
PS:当action重复执行时,同类action但不同次执行时,其所表达含义是否有不同来区分可能更清楚。
例如,A点赞B这个action,无论A点赞B多少次,所表达的含义都是相同的。但A评论B,那么不同次的评论所包含的内容可能不同。
object和association的schema仅描述该类型(otype)的数据,并不约束每类node能连接的边的类型,以及可以终止边的节点类型。例如,graph中允许self-edges的出现(例如,自己评论自己)。
3.2 Object API
TAO中的object API提供了一系列操作来实现:
(1)object对象的创建
(2)对指定id对象进行增删改查操作
TAO的object API中没有提供compare-and-set函数,因为该语义在TAO的最终一致性模型下没有太大意义。特别指出的是,update操作可以细粒度到object和association的kv属性集合中的部分字段。
3.3 Association API
社交图谱中的边,很多多少双向的。例如上例中的对称地FRIEND(好友)、或非对称的AUTHORED和AUTHORED_BY。双向边被定义成两种association。TAO提供了“inverse type”来支持association和它的逆保持sync状态。(例如,可以将AUTHORED和AUTHORED_BY的“inverse type”分别指向对法,已实现边更新时候的同步,即当增/删/改其中一个association时,其逆向association也会同步被TAO操作)。对称型的association,它的“inverse type”是它自己的类型(例如,FRIEND的reverse type就是FRIEND,而AUTHORED的reverse type是AUTHORED_BY)。
3.4 Association Query API
每一个TAO association的query语句,都是以一个object及atype开始的。社交图谱的一个特点是,大部分图谱上的数据都是旧的,但大部分的queries检索的是图谱中的新增的子集。当一个app更关注于当前元素时,就会出现“creation-time locality”现象。例如上例中,若Alice是一个著名的艺人,那么会有很多人在她的“打卡”信息下评论,而对于大部分viewer来说,他们默认看到的都是“最新的”几条评论。
TAO的association query是围绕“association lists”概念展开的。“association lists”的意思是由一个指定的node及特定的atype组成的一个association list,并按照时间戳倒排(We define an association list to be the list of all associations with a particular id1 and atype, arranged in descending order by the time field)。
![]()
TAO会限制单次association query时,查询的边的条数(例如:6000)。若有object的atype上有非常多边,那么client需要分批并行地请求(每个请求中带上post、limit等信息)。
4 TAO的架构 (TAO Architecture)
本章节将会介绍TAO的组成部分,以及允许TAO进行数据中心和跨地域扩展的分层设计。TAO被分为2个cache layer以及1个storage layer。
4.1 Storage Layer
远在TAO出现之前,Facebook就使用mysql来作为PHP的持久化存储。因此当TAO需要一个后端存储时,很容易就想到使用mysql。 TAO的API被映射为一组小而简单的SQL查询,但它也可以通过显示维护索引的方式,来被映射为non-SQL(如LevelDB)中的range scans指令。当评估TAO后端存储的适用性时,很重要的一点是也需要考虑不使用API来访问数据的情况(例如:数据备份、批量导入、批量删除、副本创建、异步备份、一致性监控工具、运维debug等)。一个备选的后端存储还需要能够提供原子写事务、细粒度写、延迟异常值。
由于TAO需要存储的数据远多于单个MySQL所能维护的上限,因此我们将数据划分为逻辑上的shards。每个shard被维护在一个逻辑的数据库中。每台database 服务器负责一个或多个shards。在实际情况中,shards的数量远高于server的数量,通过将不同的shards调度到不同的server来实现服务器间的负载均衡。默认情况下,所有类型的object被存储在一张table中,所有类型的association被存储在另一张表中。
每个object的id中,都嵌入了其所属的shard_ID。在一个object的生命周期里,它与一个shard_ID绑定到一起(Objects are bound to a shard for their entire lifetime)。一个association的shard_id等于它id1(源节点)所在的shard_id,这样可以在一台服务器上完成association的检索。
4.2 Caching Layer
TAO的cache层实现了client端的所有API,处理所有与数据库之间的交互。caching layer包含多台cache server,它们一起构成了一个tier(层)。一个tier可以响应任何TAO的请求(我们也将一个region下的database set视为一个tier)。每个请求,根据shard_ID被路由到一台cache server上。不同tier下,不要求有相同数量的cache server。
由client端发起的request被打到一台cache server上,这台cache server负责完成本次请求涉及的读写操作。出现cache miss或写操作时,本台cache server会尝试与其他cache server或DB进行联系。
在TAO的in-memory缓存汇总,包含了objects、associations lists以及association counts。我们按需缓存,并使用LRU策略进行逐出。高速缓存服务器了解其内容的语义,并使用它们来回答查询,即使之前未处理过确切的查询(例如, 缓存的零计数足以回答范围查询。)
一个带有reverse type的association的写入操作,会涉及两个shards(因为反向association的shard_ID是由id2决定的)。收到客户端请求的tier,会发起一个id2所在tier的RPC请求,来实现DB的写入。当reverse type所在的db写入完成时(即id2的association写入完成时),tier才会提交id1 association的写入。TAO并未提供这两个UPDATE操作的原子性保障。若在写入forward边失败时,TAO不会回滚之前已经update成功的反向边。这类“半吊子(hanging)”的association会由一个“async job”来负责清理。
4.3 Client Communication Stack
当渲染一个Facebook页面时,通常会涉及数百个object和association的查询,并在短时间内引发许多cache server之间进行数据交互。TAO实现的多到多数据交互所面临的问题,以及所使用的client stack跟reference 论文21的相同,但TAO的request latency比论文21中使用memcache时的latency高很多,因为TAO会涉及到DB的读写,因此为了避免在多路复用连接上出现行头阻塞 (扩展阅读:http2都干啥了,QUIC、Google QUID) ,我们使用具有乱序响应的协议。
4.4 Leaders and Followers
理论上,只要shards足够小,一个cache tier就可以通过横向扩展的方式来应对可预见的请求量。(没太理解为什么cache tier的横向扩展会跟shards的大小有关系)。而实际上,大型层级确实存在问题,因为它们更容易出现热点,并且在all-to-all connection 中呈二次方增长。
为了在控制tier最大size的情况下,实现server追加,我们将tier分为两层:leader tier和若干follower tiers。TAO基于备用cache架构的优势,需要依赖一个db仅有一个coordinator来实现。在这样的两层分层架构下,我们可以保持coordinators在每个region中仅位于一个tier下。即,系统中的每个shard都能映射到任意tier下的一台cache server上(every shard in the system maps to one caching server in each tier),使得每个tier都包含了一组cache servers用于响应系统中任意shard的请求。Leaders节点(leader tier中的cache server)的行为如4.2节所描述。Followers节点(Follower tier中的cache servers)会将cache miss或write请求forward到leaders节点。Client只会跟Followers节点进行交互,不会直接连到leaders节点。如果与client最近的Follower节点不可用了,它会fail over到另一个相邻的Follower tier上。
由于采用了两层架构,必须留意cache间的一致性。每个shard由一个leader来维护,所有对这个shard的写请求都会路由到这个leader节点,因此天然具有一致性。而Followers则需要显示地被通知,其他Followers对数据做了哪些改动。
TAO通过发送异步的 maintainence message(leader->Follower)来保证数据的最终一致性。当leader节点更新了一个object的数据后,会enqueue一条invalidation消息到对应的Follower节点。由于发起本次write请求的Follower节点在leader的write response中已经得到同步更新,因此从队列中收到invalidation 消息后,由于版本号无更新,因此不会做重复处理。由于我们仅缓存association lists的连续前缀,因此invalidate一个association会导致association list的截断,并丢弃大量的边。
例如,原本cache中的association list包含{a1, a2, a3...., an},此时a4发生了更新,leader通知Followers a4已失效,那么cache中的association 将会被截断为{a1,a2,a3}。
一种替代方案是,leader节点发送一个refill消息到对应的Follower节点,通知其发生了association的写操作。如果某个Follower节点刚好cache有这个association,那么该Follower节点将发起一个请求至leader节点,用于更新这个association已过时的list。(6.1章节将讨论这个设计的一致性以及容错性)。
leader节点会将从多个Followers上收到的并发写操作进行串行化。因为同一个id1的写请求会被路由到同一台leader server上,因此可以实现串行化。另外,这种串行化也使DB免于遭受thundering herds请求。
4.5 基于地里位置进行扩展 (Scaling Geographically)
将cache server分为leader和Follower两种类型,使得Follower tiers可以通过横向扩展的方式抗下更大的流量。但是这一设计有一个前提,即leader server和Follower server之间、leader server和DB之间的latency比较低。若clients能被限制在一个数据中心下(或邻近的几个数据中心之间),那么低latency的假设是可以成立的。
但在实际的生产环境中,由于计算资源和网络需求的不断增长,我们不得不将机房扩展到了不同的地里空间下(不同的Follower tiers可能相隔数千英里)。在这样的配置下,网络延迟将很快成为系统的瓶颈。
由于社交图谱有很强的interconnected属性,因此没办法将用户进行按组划分。这导致了TAO的Followers必须要能够访问一个本地的DB,并且该DB上包含了完整的社交图谱数据副本。而在每个数据中心都提供完整的数据副本,是十分昂贵的。
对于这个问题的解决办法是,尽可能将数据中心归拢到几个特定region下,并保证同一个region下的cache server访问时延小于1ms。如此一来,一个region下只要保存一份完整的数据副本即可。
一个完整的跨region TAO master/slave 配置(Multi-region TAO configuration)如下图所示:
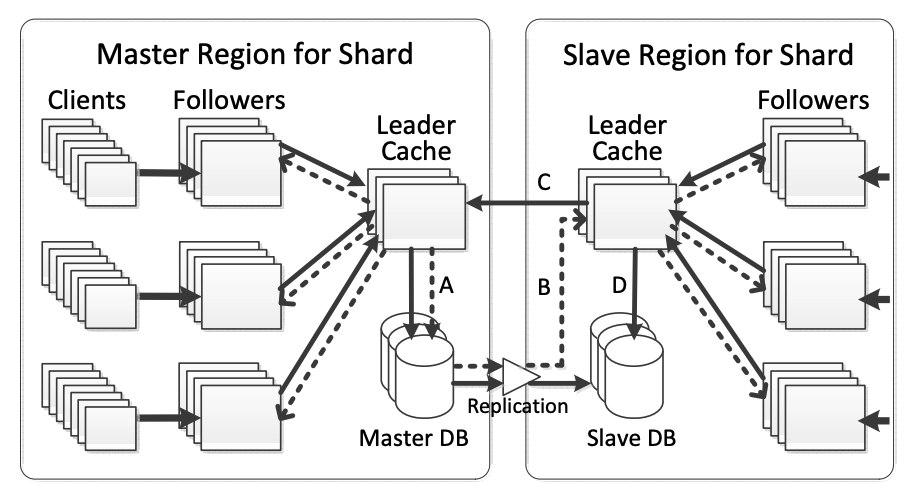
A:The master region sends read misses, writes, and embedded consistency messages to the master database
B: Consistency messages are delivered to the slave leader,as the replication stream updates the slave database(masterDB通知Slave Leader Cache的同时,也将数据副本发往Slave DB)
C: Slave leader sends writes to the master leader
D:Slave leader sends read misses to the replica DB (注意,无论是master leader cache server,还是slave leader cache server ,都只从本地的DB中读取cache miss的数据,不会跨region去读)
PS:每个shard的master和slave选取是互相独立的。由于一台server会为多个shards提供服务,因此它可能在担任shardA master的同时,也在承担着shardB的slave。
TAO倾向于将所有的master DB放在同一个region下。因为,若不同的association位于不同的region,那么当更新一个带有reverse type的association时,就需要将这个变更forward到另一个region。
TAO 将invalidation 和 refill 消息嵌入在数据库的replication stream中。当一个transaction被从A DB复制到B DB后,这些invalidation和refill消息将会及时在Region B进行传播。为什么是DB的replication完成后,才在对应的region下进行消息的传播呢?因为过早的传播invalidation和refill消息,会使得cache中的数据不一致。
因为本地cache server只会从本地的DB进行数据回源,若底层的DB replication还未完成,就尝试做cache回源,那么读到的将是旧数据。